AWS Glue での Apache Spark の生成 AI トラブルシューティング
AWS Glue の Apache Spark ジョブ用の生成 AI トラブルシューティングは、データエンジニアやサイエンティストが Spark アプリケーションの問題を簡単に診断および修正するのに役立つ新機能です。この機能は、機械学習と生成 AI テクノロジーを活用して Spark ジョブの問題を分析し、詳細な根本原因分析と、それらの問題を解決するための実用的な推奨事項を提供します。Apache Spark の生成 AI トラブルシューティングは、AWS Glue バージョン 4.0 以降で実行するジョブで使用できます。
|
AI を活用したトラブルシューティングエージェントを使用して Apache Spark のトラブルシューティングを変革できます。AWS Glue、Amazon EMR on EC2、Amazon EMR Serverless、Amazon SageMaker AI のノートブックを始めとするすべての主要なデプロイモードがサポートされるようになりました。この強力なエージェントは、自然言語インタラクション、リアルタイムのワークロード分析、スマートコードの推奨事項を組み合わせてシームレスなエクスペリエンスを実現するので、複雑なデバッグプロセスが排除されます。実装の詳細については、「What is Apache Spark Troubleshooting Agent for Amazon EMR」を参照してください。AWS Glue のトラブルシューティングの例については、「Using the Troubleshooting Agent」の 2 番目のデモを参照してください。 |
Apache Spark の生成 AI トラブルシューティングの仕組み
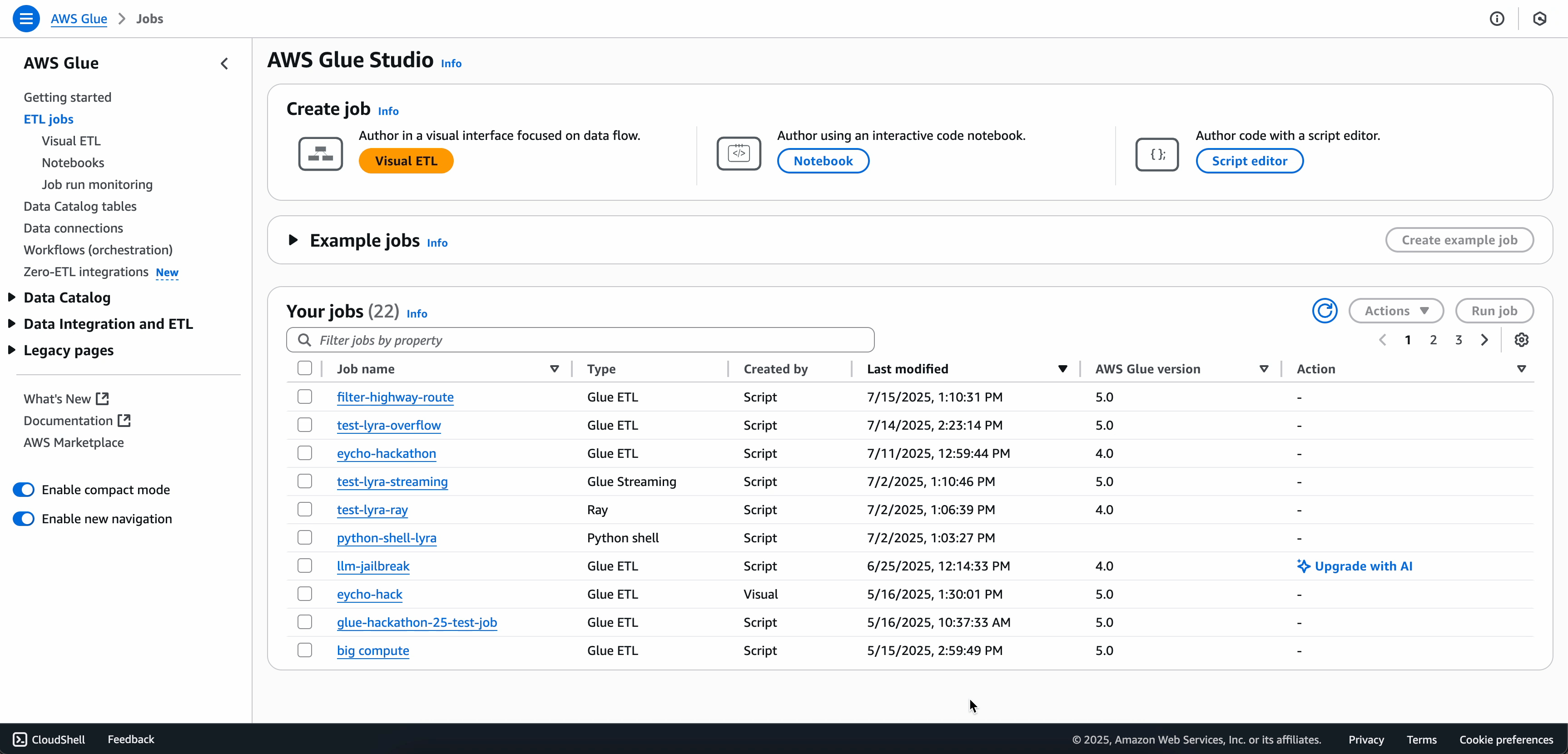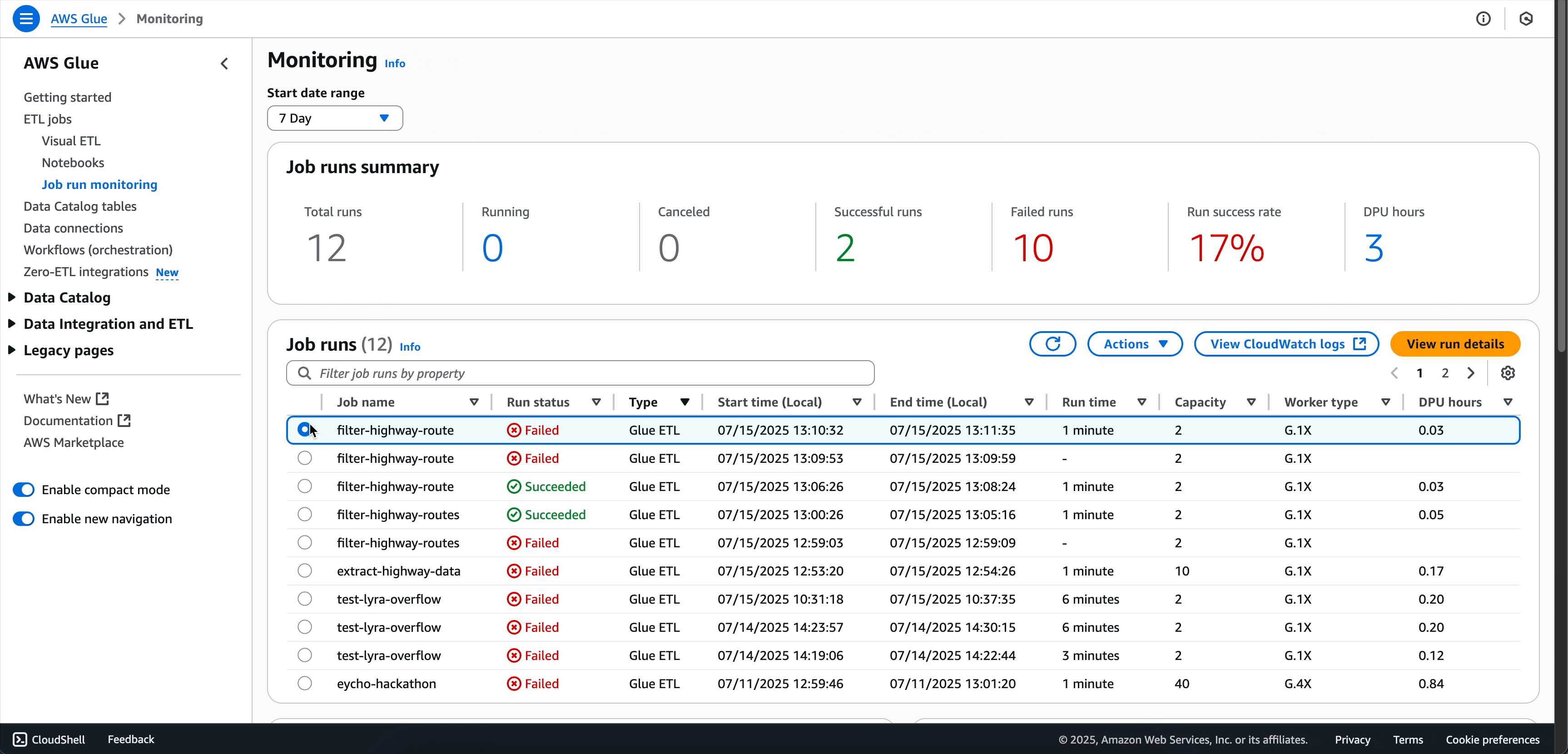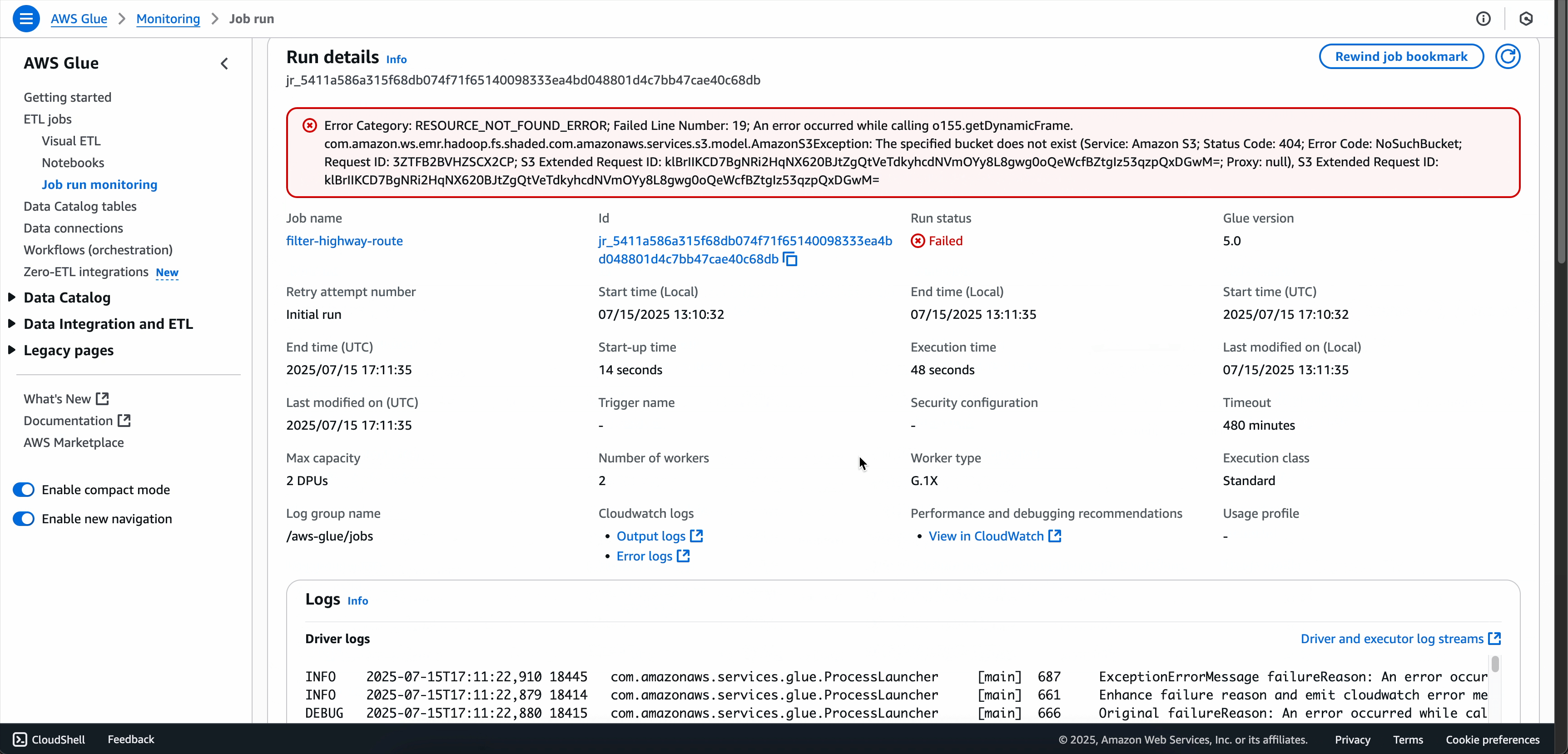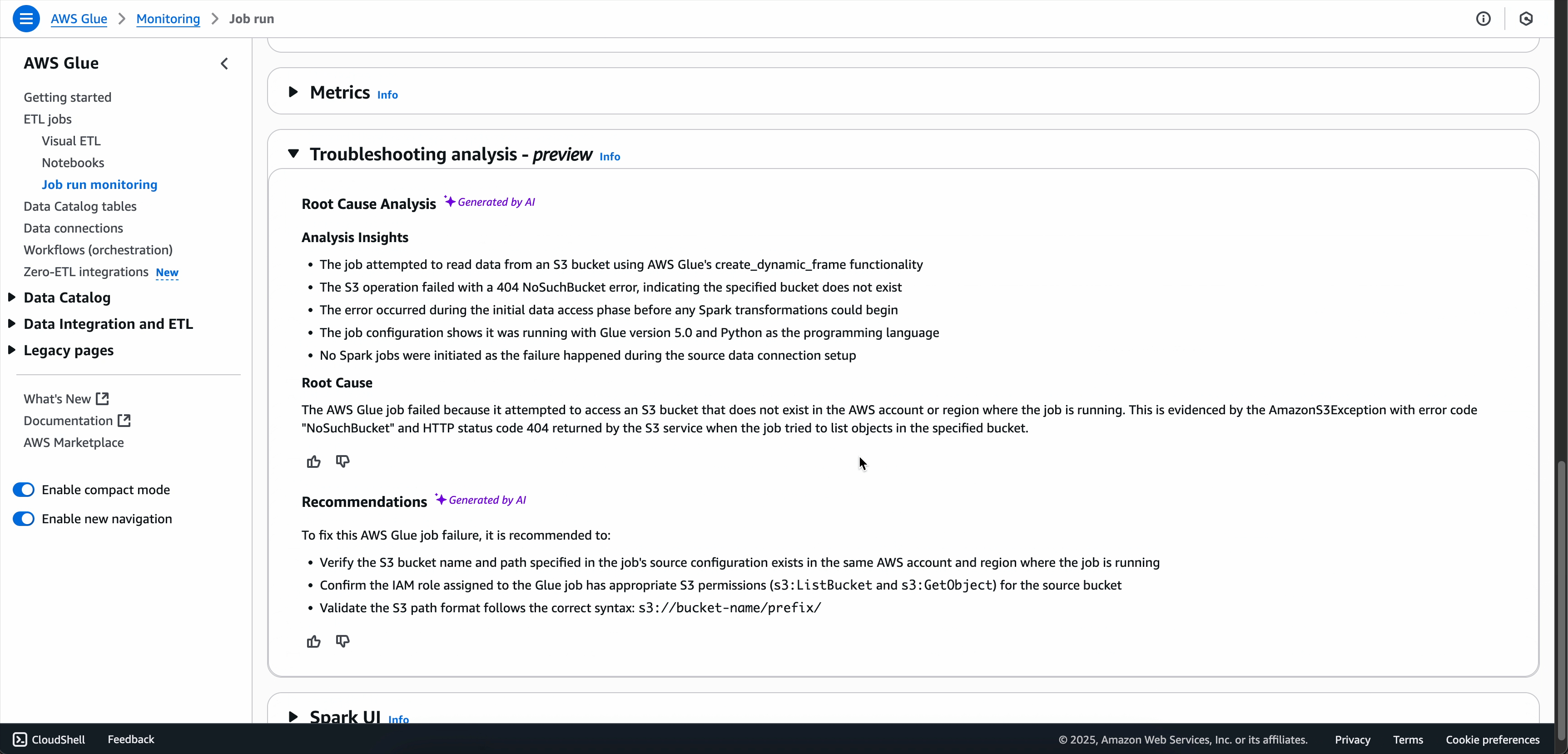
失敗した Spark ジョブの場合、生成 AI のトラブルシューティングはジョブのメタデータと、ジョブのエラー署名に関連する正確なメトリクスとログを分析して根本原因分析を生成し、ジョブの障害に対処するのに役立つ特定のソリューションとベストプラクティスを推奨します。
ジョブ用の Apache Spark の生成 AI トラブルシューティングの設定
IAM 許可の設定
AWS Glue のジョブに対して Spark トラブルシューティングで使用される APIs にアクセス許可を付与するには、適切な IAM アクセス許可が必要です。次のカスタム AWS ポリシーを IAM アイデンティティ (ユーザー、ロール、グループなど) にアタッチすることで、許可を取得できます。
注記
AWS Glue Studio コンソールを通じてこのエクスペリエンスを実現するための IAM ポリシーでは、StartCompletion と GetCompletion の 2 つの API が使用されます。
権限の割り当て
アクセスを提供するには、ユーザー、グループ、またはロールにアクセス許可を追加します。
-
IAM Identity Center のユーザーおよびグループでは: 許可セットを作成します。「IAM Identity Center のユーザーガイド」の「許可セットの作成」の手順に従ってください。
-
アイデンティティプロバイダーを介して IAM で管理されているユーザーでは: ID フェデレーションのロールを作成します。詳細については、「IAM ユーザーガイド」の「サードパーティー ID プロバイダー (フェデレーション) 用のロールの作成」を参照してください。
-
IAM ユーザーでは: 引き受けることができるロールを作成します。手順については、「IAM ユーザーガイド」の「IAM ユーザー用ロールの作成」を参照してください。
失敗したジョブ実行からのトラブルシューティング分析の実行
AWS Glue コンソールの複数のパスからトラブルシューティング機能にアクセスできます。開始方法はこちら:
オプション 1: ジョブリストページから
-
AWS Glue コンソール (https://console.aws.amazon.com/glue/
) を開きます。 -
ナビゲーションペインで、[ETL ジョブ] を選択します。
-
失敗したジョブをジョブリストで見つけます。
-
ジョブの詳細セクションで[実行] タブを選択します。
-
分析する失敗したジョブ実行をクリックします。
-
[AI によるトラブルシューティング] を選択して分析を開始します。
-
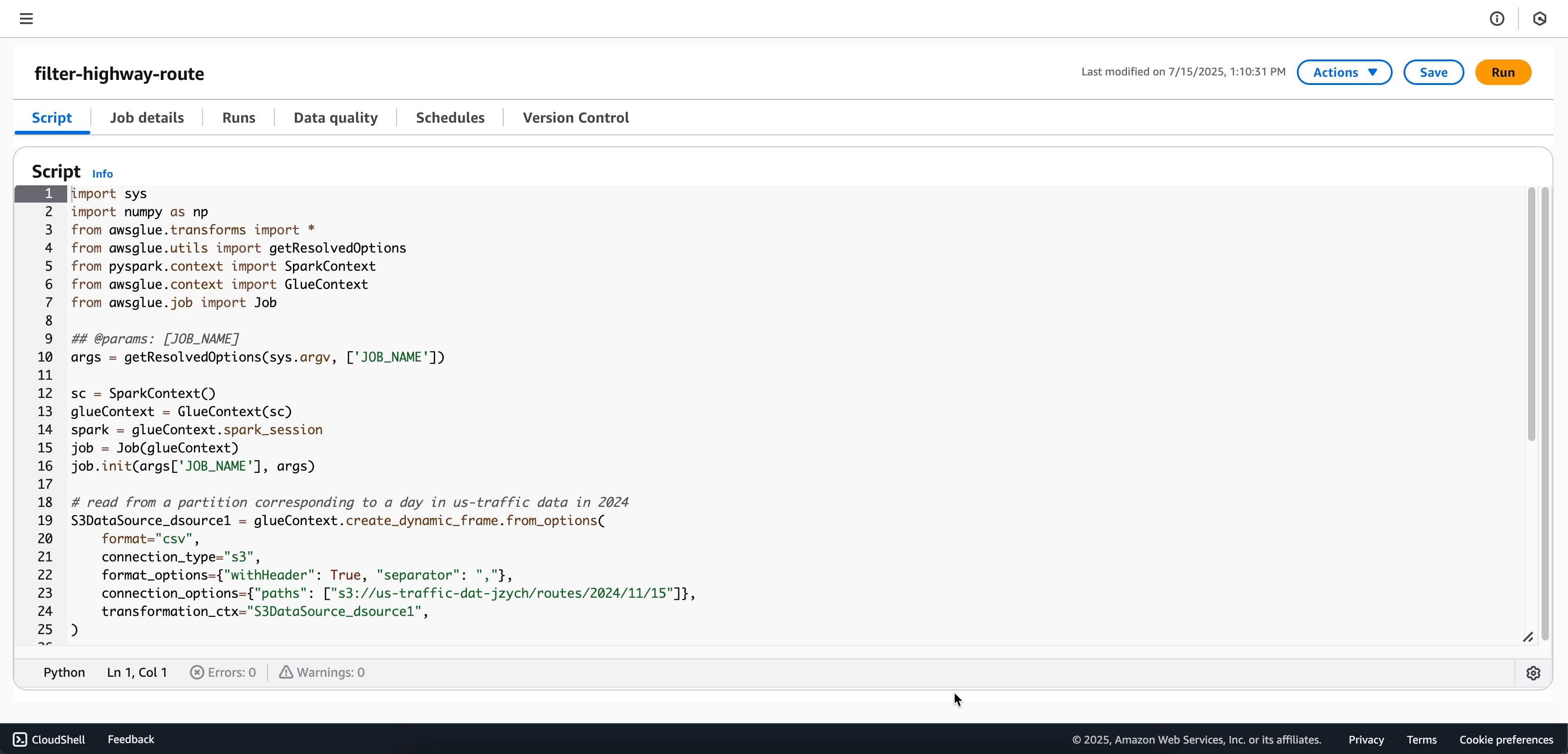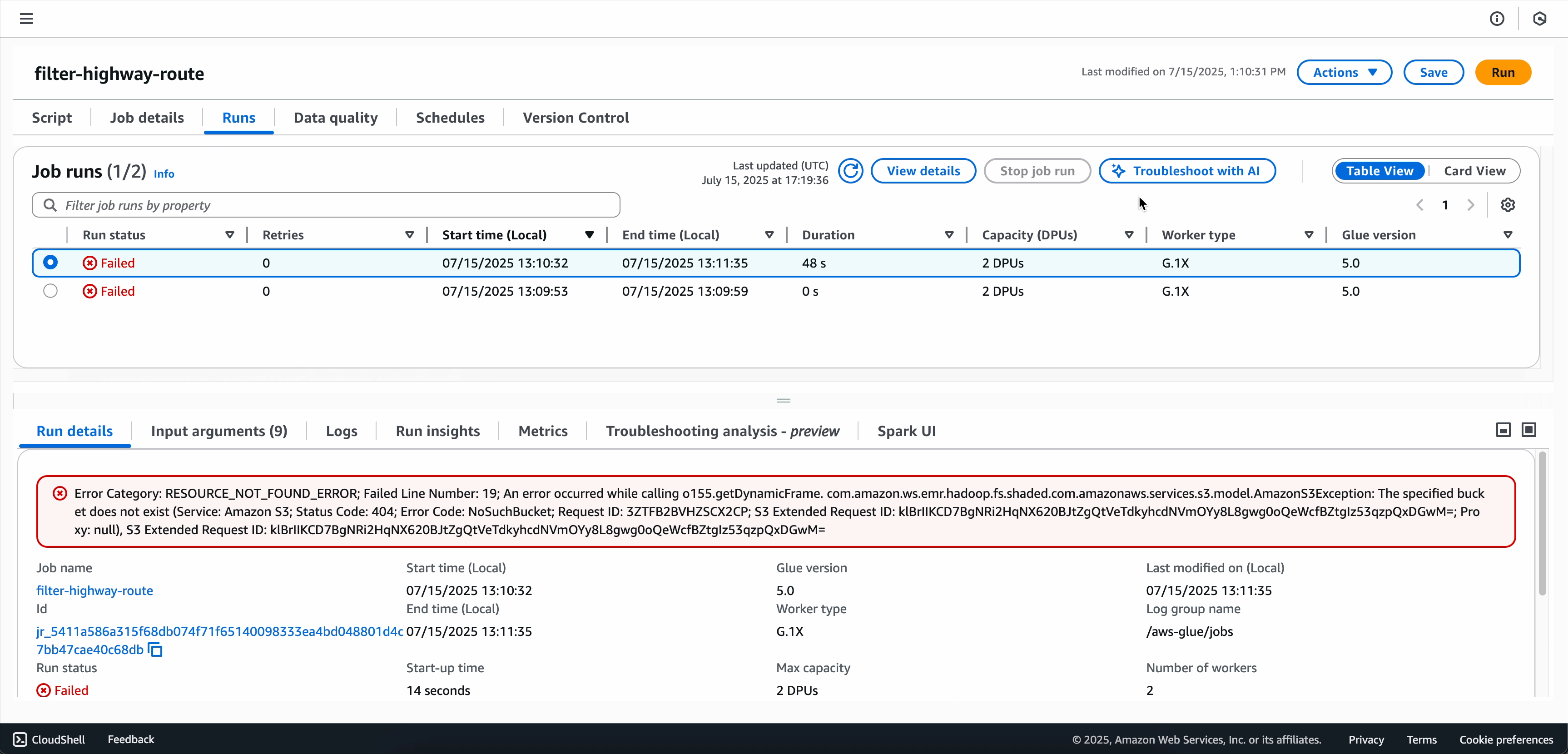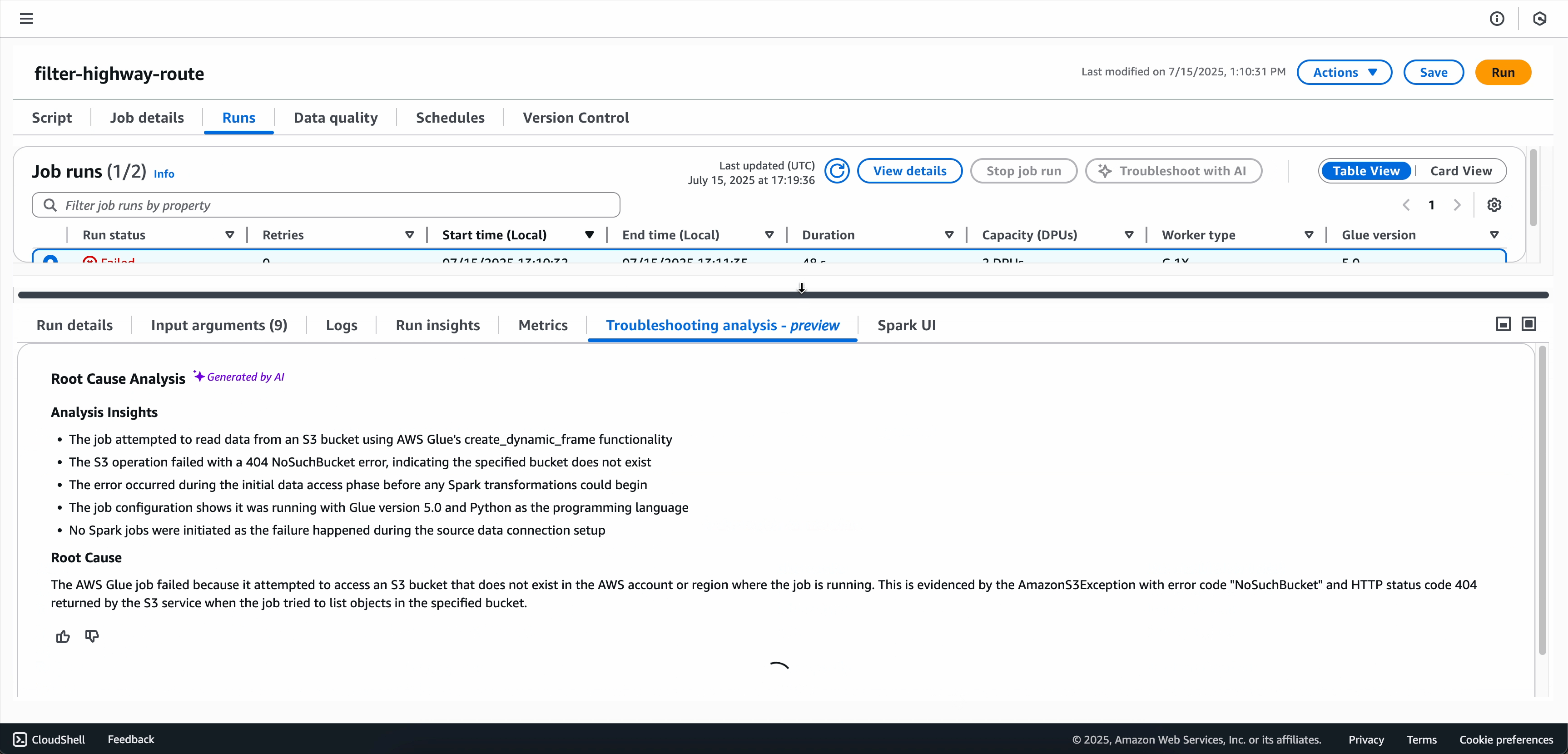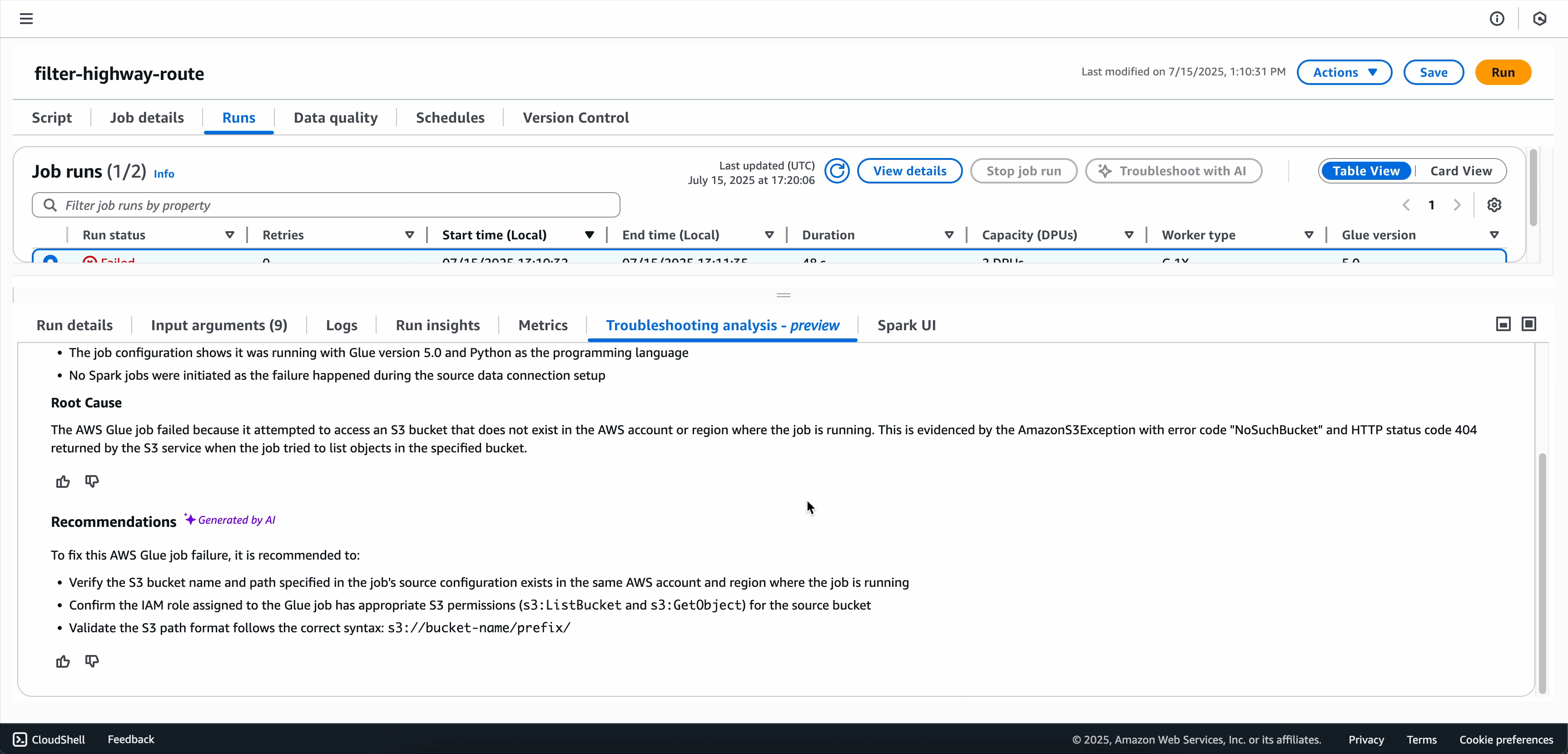
トラブルシューティング分析が完了したら、画面の下部にある [トラブルシューティング分析] タブで根本原因分析と推奨事項を表示できます。
オプション 2: [ジョブ実行モニタリング] ページの使用
-
[ジョブ実行のモニタリング] ページに移動します。
-
失敗したジョブ実行を見つけます。
-
ドロップダウンメニューで [アクション] を選択します。
-
[AI によるトラブルシューティング] を選択します。
オプション 3: [ジョブ実行の詳細] ページから
-
失敗したジョブ実行の詳細ページに移動するには、[実行] タブから失敗した実行の [詳細を表示] をクリックするか、[ジョブ実行のモニタリング] ページからジョブ実行を選択します。
-
ジョブ実行の詳細ページで、[トラブルシューティング分析] タブを見つけます。
サポートされているトラブルシューティングカテゴリ
このサービスは、データエンジニアとデベロッパーが Spark アプリケーションで頻繁に遭遇する問題の 3 つの主要なカテゴリに焦点を当てています。
-
リソースのセットアップとアクセスエラー: AWS Glue で Spark アプリケーションを実行する場合、リソースのセットアップとアクセスエラーは、診断するのが最も一般的でありながら難しい問題の 1 つです。これらのエラーは、Spark アプリケーションが、AWS リソースとやり取りしようとしても、アクセス許可の問題、リソースの欠落、または設定の問題が発生した場合によく発生します。
-
Spark ドライバーとエグゼキュターのメモリの問題: Apache Spark ジョブのメモリ関連のエラーは、診断と解決が複雑なものである場合があります。これらのエラーは、多くの場合、データ処理要件がドライバーノードまたはエグゼキューターノードで使用可能なメモリリソースを超えたときに発生します。
-
Spark ディスク容量の問題: AWS Glue Spark ジョブのストレージ関連のエラーは、シャッフル操作、データスピル、または大規模なデータ変換の処理中に発生することがよくあります。これらのエラーは、ジョブがしばらく実行されるまで表示されない可能性があり、貴重なコンピューティング時間とリソースを浪費する可能性があります。
-
クエリ実行エラー: Spark SQL および DataFrame オペレーションのクエリエラーは、エラーメッセージが根本原因を明確に指さない可能性があり、小さなデータセットで正常に機能するクエリが突然大規模に失敗する可能性があるため、トラブルシューティングが困難になる可能性があります。これらのエラーは、複雑な変換パイプラインの深い段階で発生すると、特定がさらに困難になります。実際の原因は、クエリロジック自体ではなく、前段階におけるデータ品質の問題に起因する場合があります。
注記
本番環境に提案された変更を実装する前に、提案された変更を徹底的に確認してください。このサービスは、パターンとベストプラクティスに基づいてレコメンデーションを提供しますが、特定のユースケースでは追加の考慮事項が必要になる場合があります。
サポート対象のリージョン
Apache Spark の生成 AI トラブルシューティングは、次のリージョンで利用できます。
-
アフリカ: ケープタウン (af-south-1)
-
アジアパシフィック: 香港 (ap-east-1)、東京 (ap-northeast-1)、ソウル (ap-northeast-2)、大阪 (ap-northeast-3)、ムンバイ (ap-south-1)、シンガポール (ap-southeast-1)、シドニー (ap-southeast-2)、ジャカルタ (ap-southeast-3)
-
欧州: フランクフルト (eu-central-1)、ストックホルム (eu-north-1)、ミラノ (eu-south-1)、アイルランド (eu-west-1)、ロンドン (eu-west-2)、パリ (eu-west-3)
-
中東: バーレーン (me-south-1)、UAE (me-central-1)
-
北米: カナダ (ca-central-1)
-
南米: サンパウロ (sa-east-1)
-
米国: バージニア北部 (us-east-1)、オハイオ (us-east-2)、北カリフォルニア (us-west-1)、オレゴン (us-west-2)
