AWS Glue と AWS Lake Formation を併用したきめ細かなアクセスコントロール
概要
AWS Glue バージョン 5.0 以降では、AWS Lake Formation を活用して、S3 でサポートされているデータカタログテーブルにきめ細かなアクセスコントロールを適用できます。この機能を使用すると、AWS Glue for Apache Spark ジョブ内の read クエリのテーブル、行、列、セルレベルのアクセスコントロールを設定できます。Lake Formation の詳細と AWS Glue での使用方法については、以下のセクションを参照してください。
Glue 4.0 以前でサポートされていた、AWS Lake Formation のアクセス許可を持つ GlueContext ベースのテーブルレベルのアクセスコントロールは、Glue 5.0 ではサポートされません。Glue 5.0 では新しい Spark ネイティブのきめ細かなアクセスコントロール (FGAC) を使用します。次の詳細情報に注意してください。
row/column/cell のアクセスコントロールにきめ細かなアクセスコントロール (FGAC) が必要な場合は、 Glue 4.0 の
GlueContext/Glue DynamicFrame から、 Glue 5.0 の Spark DataFrame より前に移行する必要があります。例については、「GlueContext/Glue DynamicFrame から Spark DataFrame への移行」を参照してください。フルテーブルアクセスコントロール (FTA) が必要な場合は、AWS Glue 5.0 の DynamicFrames を使って FTA を活用できます。また、ネイティブ Spark アプローチに移行して、障害耐性分散データセット (RDD)、カスタムライブラリ、AWS Lake Formation テーブルを含むユーザー定義関数 (UDF) などの追加機能を利用することもできます。例については、「AWS Glue 4.0 から AWS Glue 5.0 への移行」を参照してください。
FGAC が必要ない場合、Spark DataFrame への移行は不要で、ジョブのブックマークやプッシュダウン述語などの
GlueContext機能は引き続き機能します。FGAC を使用するジョブには、1 つのユーザードライバー、1 つのシステムドライバー、1 つのシステムエグゼキューター、1 つのスタンバイユーザーエグゼキューターの最低 4 つのワーカーが必要です。
AWS Lake Formation で AWS Glue を使用すると、追加料金が発生します。
AWS Glue と AWS Lake Formation の連携方法
AWS Glue と Lake Formation を使用すると、各 Spark ジョブにアクセス許可のレイヤーを適用して、AWS Glue がジョブを実行するときに Lake Formation アクセス許可コントロールを適用できます。AWSGlue は、Spark リソースプロファイル
以下は、AWS Glue が Lake Formation セキュリティポリシーで保護されたデータにアクセスする方法の概要を示します。
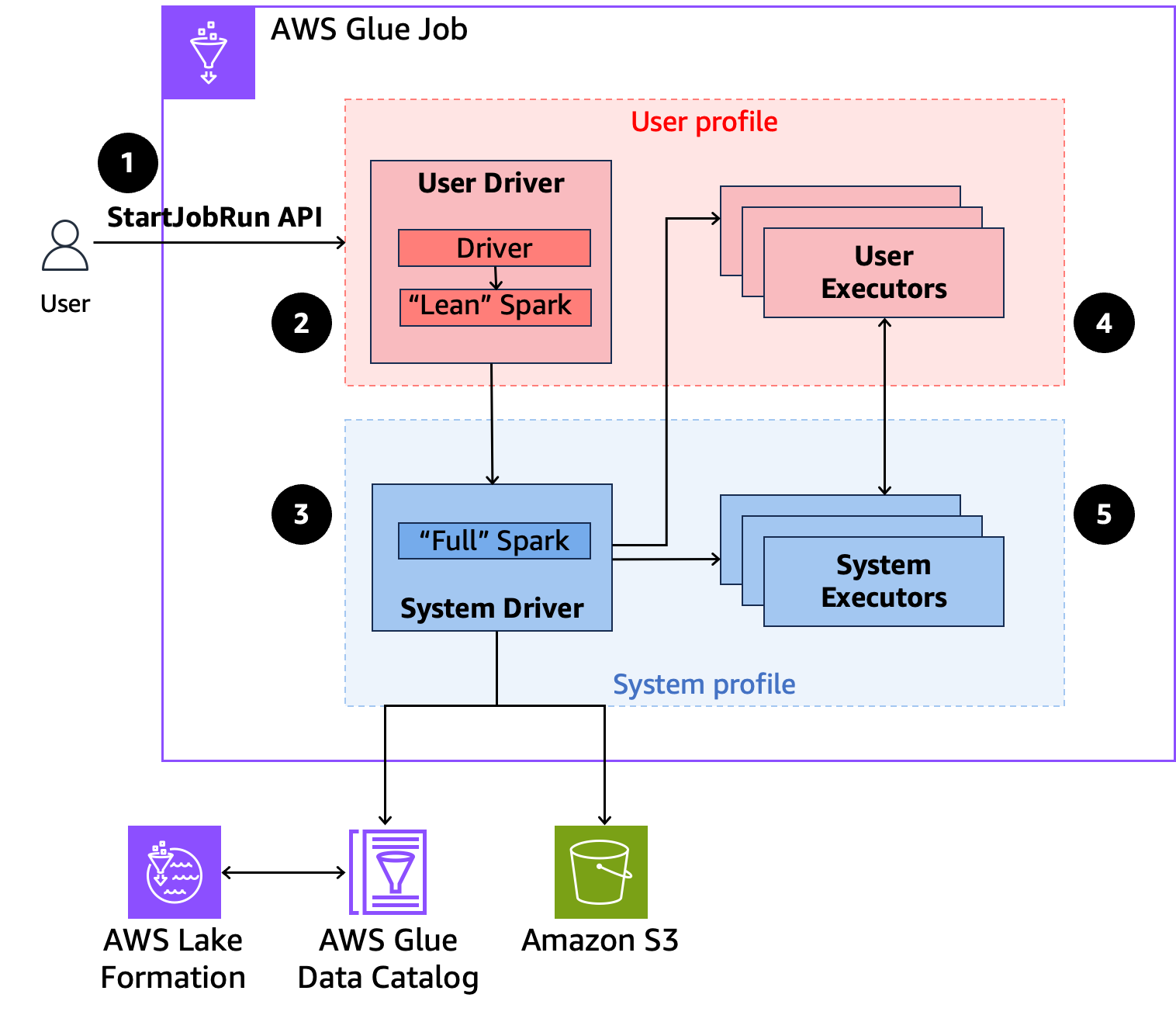
-
ユーザーは AWS Lake Formation が有効な AWS Glue ジョブで
StartJobRunAPI を呼び出します。 -
AWS Glue はジョブをユーザードライバーに送信し、ユーザープロファイルでジョブを実行します。ユーザードライバーは、タスクの起動、エグゼキュターのリクエスト、S3 または Glue カタログへのアクセスができない Spark のリーンバージョンを実行します。ジョブプランを構築します。
-
AWS Glue は、システムドライバーと呼ばれる 2 番目のドライバーを設定し、システムプロファイルで (特権 ID を使用して) 実行します。AWSGlue は、通信用の 2 つのドライバー間に暗号化された TLS チャネルを設定します。ユーザードライバーはチャネルを使用して、ジョブプランをシステムドライバーに送信します。システムドライバーは、ユーザーが送信したコードを実行しません。フル Spark を実行して、データアクセスのために S3 およびデータカタログと通信します。エグゼキュターをリクエストし、ジョブプランを一連の実行ステージにコンパイルします。
-
次に、AWS Glue はユーザードライバーまたはシステムドライバーを使用してエグゼキュターでステージを実行します。どのステージのユーザーコードも、ユーザープロファイルのエグゼキュターでのみ実行されます。
-
AWS Lake Formation で保護されたデータカタログテーブルからデータを読み取るステージ、またはセキュリティフィルターを適用するステージは、システムエグゼキュターに委任されます。
ワーカーの最小要件
AWS Glue の Lake Formation 対応ジョブには、1 つのユーザードライバー、1 つのシステムドライバー、1 つのシステムエグゼキューター、1 つのスタンバイユーザーエグゼキューターの最低 4 つのワーカーが必要です。これは、標準の AWS Glue ジョブに必要な最低 2 つのワーカーより多いです。
AWS Glue の Lake Formation 対応ジョブごとに 2 つの Spark ドライバー (1 つはユーザープロファイル用、もう 1 つはシステムプロファイル用) を使用します。同様に、エグゼキューターも 2 つのプロファイルに分割されます。
システムエグゼキューター: Lake Formation データフィルターが適用されるタスクを処理します。
ユーザーエグゼキューター: 必要に応じてシステムドライバーによってリクエストされます。
Spark ジョブは遅延する性質があるため、AWS Glue は 2 つのドライバーを差し引いたワーカー総数の 10% (最小 1) をユーザーエグゼキューター用に予約します。
すべての Lake Formation 対応ジョブで、自動スケーリングが有効になっています。つまり、ユーザーエグゼキューターは必要なときにのみ起動します。
設定例については、「考慮事項と制限」を参照してください。
ジョブランタイムロールの IAM アクセス許可
Lake Formation アクセス許可は、AWS Glue Data Catalog リソース、Amazon S3 ロケーション、およびこれらのロケーションにある基盤データへのアクセスを制御します。IAM アクセス許可は、Lake Formation および AWS Glue API とリソースへのアクセスを制御します。データカタログ内のテーブルにアクセスするための Lake Formation アクセス許可 (SELECT) を持っていても、glue:Get* API オペレーションに対する IAM アクセス許可がない場合、操作は失敗します。
以下は、S3 のスクリプトにアクセスするための IAM アクセス許可、S3 AWS へのログのアップロード、Glue API アクセス許可、Lake Formation へのアクセス許可を指定する方法のポリシー例です。
ジョブランタイムロールの Lake Formation アクセス許可の設定
まず、Hive テーブルの場所を Lake Formation に登録します。次に、目的のテーブルにジョブランタイムロールのアクセス許可を作成します。Lake Formation の詳細については、「AWS Lake Formation デベロッパーガイド」の「AWS Lake Formation とは」を参照してください。
Lake Formation のアクセス許可を設定したら、AWS Glue で Spark ジョブを送信できます。
ジョブ実行の送信
Lake Formation のアクセス許可の設定が完了したら、AWS Glue で Spark ジョブを送信できます。Iceberg ジョブを実行するには、次の Spark 設定を指定する必要があります。Glue ジョブパラメータを使用して設定するには、次のパラメータを入力します。
キー:
--conf値:
spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com
インタラクティブセッションの使用
AWS Lake Formation 許可の設定が完了したら、AWS Glue でインタラクティブセッションを使用できます。コードを実行する前に、%%configure マジックを使用して次の Spark 設定を提供する必要があります。
%%configure { "--enable-lakeformation-fine-grained-access": "true", "--conf": "spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.warehouse=<S3_DATA_LOCATION> --conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog --conf spark.sql.catalog.spark_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog.client.region=<REGION> --conf spark.sql.catalog.spark_catalog.glue.account-id=<ACCOUNT_ID> --conf spark.sql.catalog.spark_catalog.glue.endpoint=https://glue.<REGION>.amazonaws.com" }
AWS Glue 5.0 Notebook またはインタラクティブセッション用の FGAC
AWS Glue で「きめ細かなアクセスコントロール」 (FGAC) を有効にするには、最初のセルを作成する前に、%%configure マジックの一部として Lake Formation に必要な Spark confs を指定する必要があります。
後で呼び出し SparkSession.builder().conf("").get() または SparkSession.builder().conf("").create() を使用して指定するだけでは不十分です。これは AWS Glue 4.0 からの挙動変更となります。
オープンテーブル形式のサポート
AWS Glue バージョン 5.0 以降には、Lake Formation に基づくきめ細かなアクセスコントロールのサポートが含まれています。AWSGlue は、Hive テーブルタイプと Iceberg テーブルタイプをサポートしています。次の表で、サポートされているすべてのオペレーションについて説明します。
| オペレーション | [Hive] | Iceberg |
|---|---|---|
| DDL コマンド | IAM ロールのアクセス許可のみ | IAM ロールのアクセス許可のみ |
| 増分クエリ | 該当しない | 完全サポートされています |
| タイムトラベルクエリ | このテーブル形式には適用されません | 完全サポートされています |
| メタデータテーブル | このテーブル形式には適用されません | サポートされていますが、特定のテーブルは非表示になっています。詳細については、「考慮事項と制限事項」を参照してください。 |
DML INSERT |
IAM アクセス許可のみ | IAM アクセス許可のみ |
| DML UPDATE | このテーブル形式には適用されません | IAM アクセス許可のみ |
DML DELETE |
このテーブル形式には適用されません | IAM アクセス許可のみ |
| 読み込みオペレーション | 完全サポートされています | 完全サポートされています |
| ストアドプロシージャ | 該当しない | register_table および migrate の例外でサポートされます。詳細については、「考慮事項と制限事項」を参照してください。 |
