AWS Glue での Amazon Q データ統合によるコンテキスト認識の使用
Amazon Q データ統合で、クエリベースのコンテキスト認識と PySpark DataFrame コード生成を使用することで、データ処理ジョブをこれまでよりもさらに効率的に作成できるようになりました。例えば、次のプロンプトを使用することで PySpark コードを生成できます。「create a job to load sales data from Redshift table ‘analytics.salesorder’ using connection ‘erp_conn’, filter order_amount below 50 dollars, and save to Amazon S3 in parquet format.」
Amazon Q は、プロンプトに基づいてスクリプトを生成し、接続設定、スキーマの詳細、データベース/テーブル名、変換の列仕様など、質問の中で提示された情報を使用してデータ統合ワークフローを設定します。接続オプションのパスワードなどの機密情報は引き続き編集されます。
プロンプトから必要な情報が提供されていない場合、Amazon Q はプレースホルダーを配置します。プレースホルダーは、コードを実行する前に、生成されたコードを適切な値で更新する必要があります。
コンテキスト認識の使用方法の例を以下に紹介します。
インタラクションの例
プロンプト: Create an AWS Glue spark job that reads a file s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv and
saves it into the parquet file under directory s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("csv").load( "s3://amzn-s3-demo-bucket-input-bucket-name/input-filename.csv" ) # Script generated for node S3DataSink S3DataSource_dsource1.write.format("parquet").mode("append").save( "s3://amzn-s3-demo-bucket-output-bucket-name/output-s3-prefix/" )

プロンプト: write an ETL script to read from a Lakehouse table my-table in database my-database and write it to a RDS MySQL table
my-target-table
ユーザーが情報を提供しなかったフィールド (例えば connectionName が MySQL データシンクに必須であり、生成されたコードにデフォルトでプレースホルダー <connection-name> が付く場合) では、スクリプトを実行する前に必須の情報を入力するためのプレースホルダーが保持されます。
生成されたスクリプト:
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession from connectivity.adapter import CatalogConnectionHelper sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node S3DataSource S3DataSource_dsource1 = spark.read.format("parquet").load( "s3://amzn-lakehouse-demo-bucket/my-database/my-table" ) # Script generated for node ConnectionV2DataSink ConnectionV2DataSink_dsink1_additional_options = {"dbtable": "my-target-table"} CatalogConnectionHelper(spark).write( S3DataSource_dsource1, "mysql", "<connection-name>", ConnectionV2DataSink_dsink1_additional_options, )

以下は、次のプロンプトを使って、AWS Glue スクリプトを作成して完全な ETL ワークフローを完了するよう AWS Glue に指示する方法の例を示したものです。Create a AWS Glue ETL Script read from two AWS Glue Data Catalog tables venue and event in my database
glue_db_4fthqih3vvk1if, join the results on the field venueid, filter on venue state with condition as venuestate=='DC'
after joining the results and write output to an Amazon S3 S3 location s3://amz-s3-demo-bucket/output/ in CSV format
このワークフローには、異なるデータソース (AWS Glue データカタログの 2 つのテーブル) からの読み取りの他に、読み取り後のいくつかの変換が含まれ、2 つの読み取り結果を結合して何らかの条件に基づいてフィルター処理し、変換された出力を CSV 形式で Amazon S3 の宛先に書き込みます。
生成されたジョブは、データソース、変換、シンクオペレーションの詳細情報を、次のようにユーザーの質問から抽出された対応する情報で入力します。
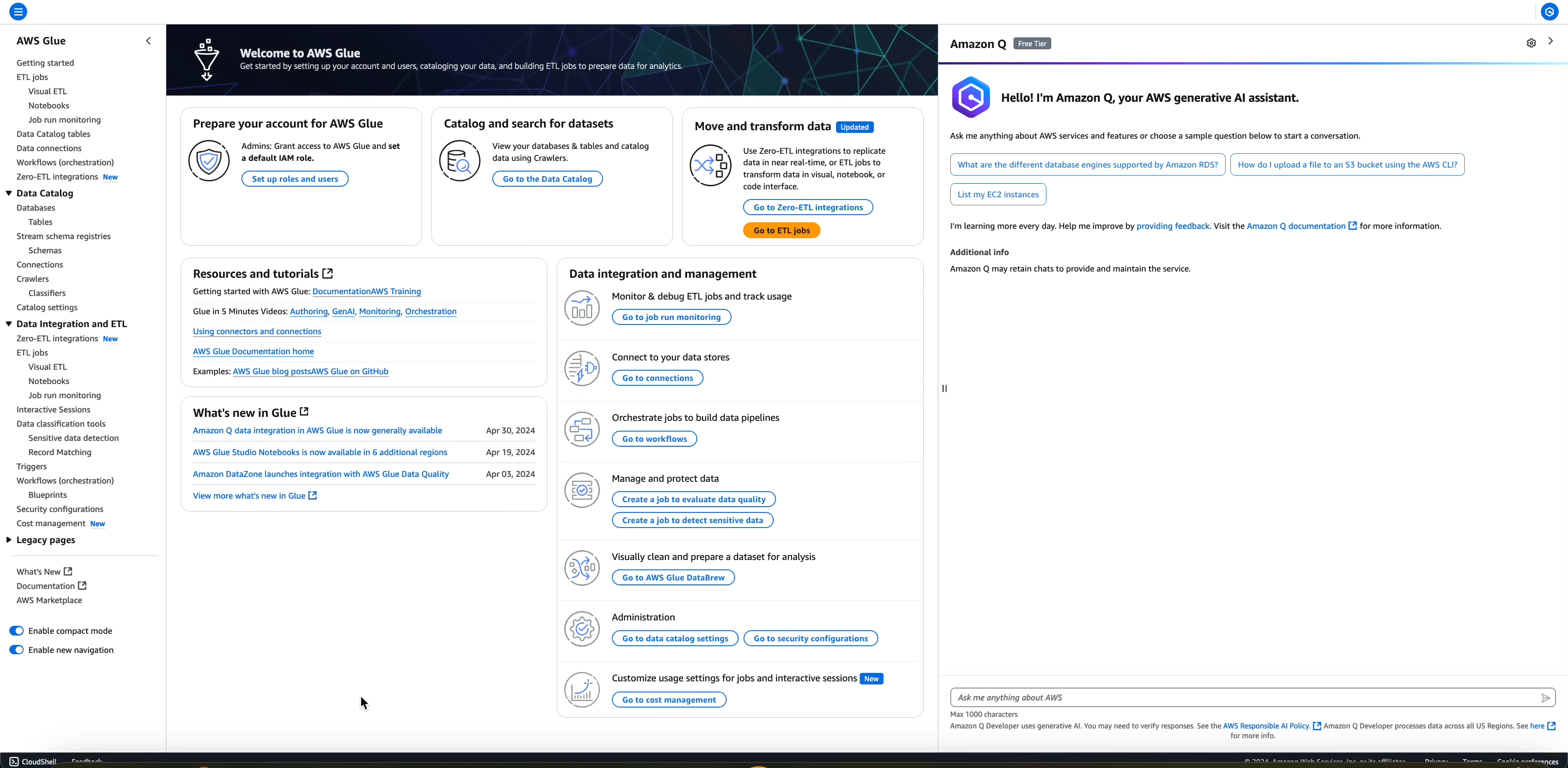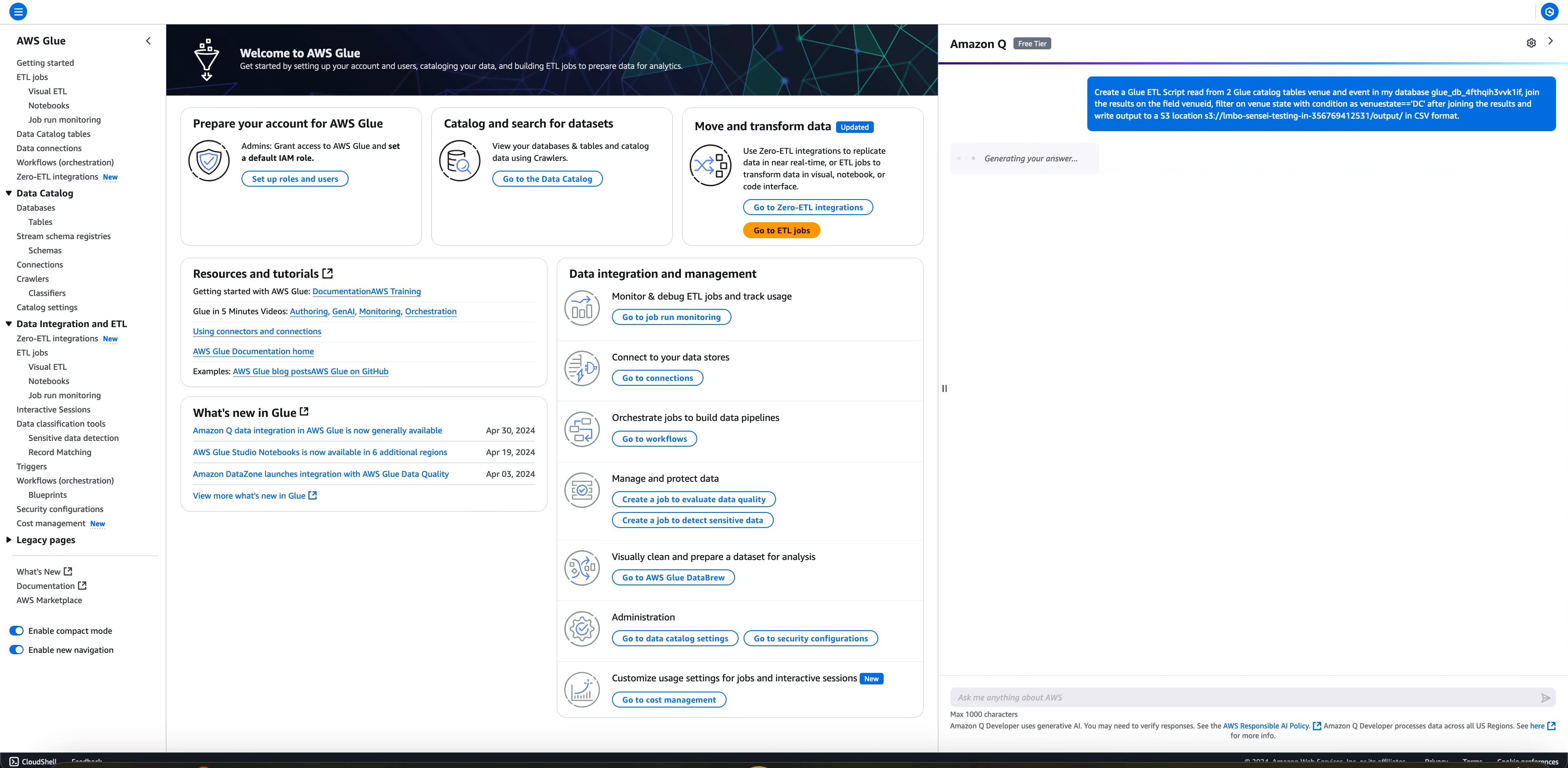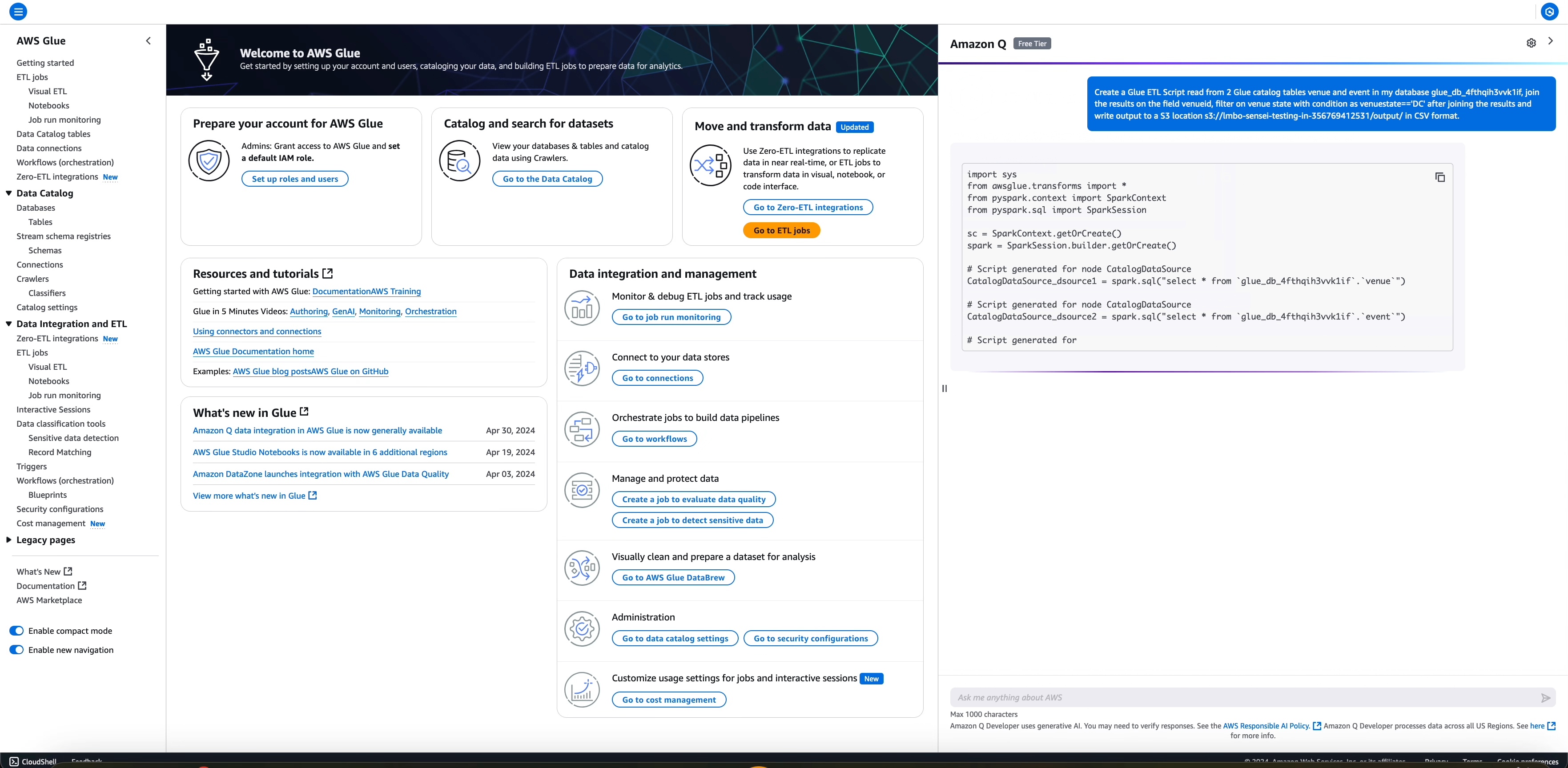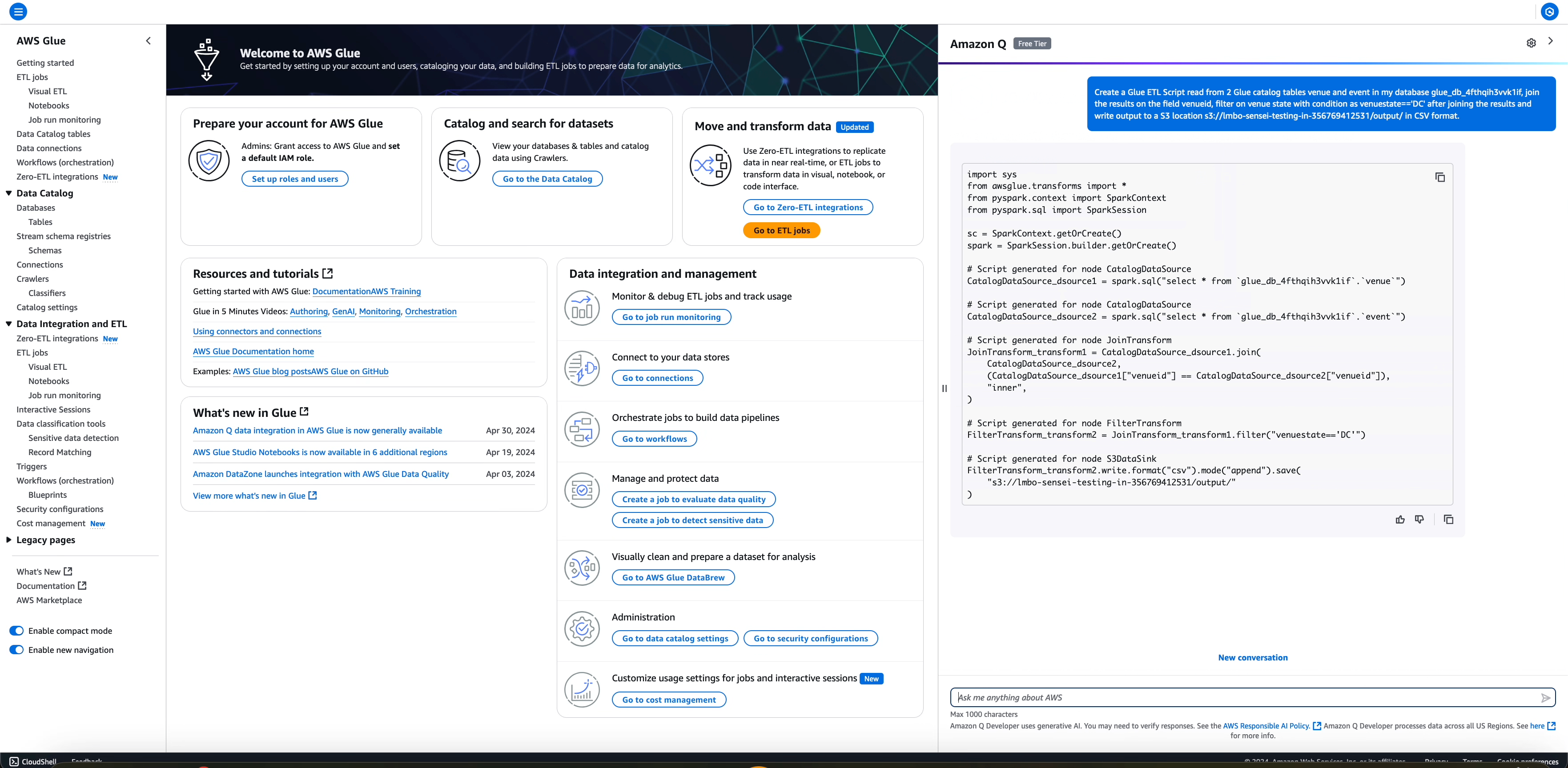
import sys from awsglue.transforms import * from pyspark.context import SparkContext from pyspark.sql import SparkSession sc = SparkContext.getOrCreate() spark = SparkSession.builder.getOrCreate() # Script generated for node CatalogDataSource CatalogDataSource_dsource1 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`venue`") # Script generated for node CatalogDataSource CatalogDataSource_dsource2 = spark.sql("select * from `glue_db_4fthqih3vvk1if`.`event`") # Script generated for node JoinTransform JoinTransform_transform1 = CatalogDataSource_dsource1.join( CatalogDataSource_dsource2, (CatalogDataSource_dsource1["venueid"] == CatalogDataSource_dsource2["venueid"]), "inner", ) # Script generated for node FilterTransform FilterTransform_transform2 = JoinTransform_transform1.filter("venuestate=='DC'") # Script generated for node S3DataSink FilterTransform_transform2.write.format("csv").mode("append").save( "s3://amz-s3-demo-bucket/output//output/" )
制限事項
-
コンテキストの持ち越し:
-
コンテキスト認識機能は、同じ会話内の以前のユーザークエリのコンテキストのみを継承します。直前のクエリ以外のコンテキストは保持されません。
-
-
ノード設定のサポート:
-
現在、コンテキスト認識はさまざまなノードの必須設定のサブセットのみをサポートしています。
-
オプションのフィールドのサポートは、今後のリリースで予定されています。
-
-
可用性:
-
コンテキスト認識と DataFrame サポートは、Q Chat および SageMaker Unified Studio ノートブックで利用できます。ただし、これらの機能は AWS Glue Studio ノートブックではまだ使用できません。
-
