Docker イメージを使用してローカルで AWS Glue ジョブを開発およびテストする
本番環境対応のデータプラットフォームの場合、AWS Glue ジョブ向けの開発プロセスや CI/CD パイプラインで検討すべきです。Docker コンテナでは、AWS Glue のジョブの開発やテストが柔軟に行えます。AWS Glue は Docker Hub に Docker イメージをホストすることで、追加のユーティリティを使用する開発環境をセットアップします。IDE、ノートブック、または、AWS Glue ETL ライブラリを使用する REPL などを、ご自分で選択して使用できます。このトピックでは、Docker コンテナ上で Docker イメージを使用して AWS Glue バージョン 5.0 のジョブを開発およびテストする方法について説明します。
利用可能な Docker イメージ
Amazon ECR
-
AWS Glue バージョン 5.0 の場合:
public.ecr.aws/glue/aws-glue-libs:5 -
AWS Glue バージョン 4.0 の場合:
public.ecr.aws/glue/aws-glue-libs:glue_libs_4.0.0_image_01 -
AWS Glue バージョン 3.0 の場合:
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 -
AWS Glue バージョン 2.0 の場合:
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
注記
AWS Glue Docker イメージは x86_64 と arm64 の両方と互換性があります。
この例では、ローカルマシン (Mac/Windows/Linux) での public.ecr.aws/glue/aws-glue-libs:5 の使用法とコンテナを実行するための方法を示します。このコンテナイメージは、AWS Glue バージョン 5.0 の Spark ジョブでテスト済みです。このイメージには、以下が含まれます。
-
Amazon Linux 2023
-
AWS Glue ETL ライブラリ
-
Apache Spark 3.5.4
-
オープンテーブル形式のライブラリ; Apache Iceberg 1.7.1、Apache Hudi 0.15.0、Delta Lake 3.3.0
-
AWS Glue データカタログクライアント
-
Amazon Redshift Apache Spark 用 コネクタ
-
Amazon DynamoDB Apache Hadoop 用 コネクタ
コンテナを設定するには、ECR Public Gallery からイメージを取得して、コンテナを実行します。このトピックでは、要件に応じて以下の各方法でコンテナを実行する方法を示します。
-
spark-submit -
REPL シェル
(pyspark) -
pytest -
Visual Studio Code
前提条件
作業を開始する前に、Docker がインストール済みであり、Docker デーモンが実行中であることを確認します。インストールの手順については、Mac
AWS Glue のコードをローカルで開発する際の制限については、「ローカル開発の制限」を参照してください。
AWS の設定
コンテナから AWS API コールを有効にするには、以下の手順に従って AWS 認証情報をセットアップします。以下のセクションでは、この AWS により名前が指定されたプロファイルを使用します。
-
Windows または Mac/Linux のターミナルで
cmdを開き、ターミナル上で次のコマンドを実行します。PROFILE_NAME="<your_profile_name>"
以下のセクションでは、この AWS の名前付きプロファイルを使用します。
Windows で Docker を実行している場合は、Docker アイコンを右クリックし、イメージを取得する前に [Switch to Linux containers] (Linux コンテナに切り替える) を選択します。
ECR Public からイメージを取得するには、次のコマンドを実行します。
docker pull public.ecr.aws/glue/aws-glue-libs:5
コンテナを実行する
ここまでの操作により、取得したイメージを使用してコンテナを実行できるようになります。ご自身の要件に応じて、以下のいずれかを選択できます。
spark-submit
コンテナで spark-submit コマンドを使用して、AWS Glue のジョブスクリプトを実行できます。
-
以下の例のようにスクリプトを記述して
sample.pyとして保存し、さらに以下のコマンドを使用して/local_path_to_workspace/src/ディレクトリに保存します。$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ mkdir -p ${WORKSPACE_LOCATION}/src $ vim ${WORKSPACE_LOCATION}/src/${SCRIPT_FILE_NAME} -
これらの変数は、以下の Docker 実行コマンドで使用されます。以下の spark-submit コマンドで使用されるサンプルコード (sample.py) は、このトピックの最後にある付録に含まれています。
以下のコマンドにより、コンテナで
spark-submitコマンドを使用して、新しい Spark アプリケーションをサブミットします。$ docker run -it --rm \ -v ~/.aws:/home /hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_spark_submit \ public.ecr.aws/glue/aws-glue-libs:5 \ spark-submit /home/hadoop/workspace/src/$SCRIPT_FILE_NAME -
(オプション) 環境に合わせて
spark-submitを構成します。たとえば、--jars設定を使用して依存関係を渡すことができます。詳細については、Spark ドキュメントの「Dynamically Loading Spark Properties (Spark プロパティの動的ロード)」を参照してください。
REPL シェル (Pyspark)
REPL (read-eval-print loops) シェルを実行すると、インタラクティブな開発を行うことができます。次のコマンドにより、コンテナ上で PySpark コマンドを実行し、REPL シェルを起動します。
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
この場合、次の出力が返されます。
Python 3.11.6 (main, Jan 9 2025, 00:00:00) [GCC 11.4.1 20230605 (Red Hat 11.4.1-2)] on linux Type "help", "copyright", "credits" or "license" for more information. Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.5.4-amzn-0 /_/ Using Python version 3.11.6 (main, Jan 9 2025 00:00:00) Spark context Web UI available at None Spark context available as 'sc' (master = local[*], app id = local-1740643079929). SparkSession available as 'spark'. >>>
この REPL シェルを使用することで、インタラクティブなコーディングとテストを実行できます。
Pytest
ユニットテストの場合、AWS Glue の Spark ジョブスクリプトで pytest を使用できます。以下のコマンドを実行し、準備を行います。
$ WORKSPACE_LOCATION=/local_path_to_workspace $ SCRIPT_FILE_NAME=sample.py $ UNIT_TEST_FILE_NAME=test_sample.py $ mkdir -p ${WORKSPACE_LOCATION}/tests $ vim ${WORKSPACE_LOCATION}/tests/${UNIT_TEST_FILE_NAME}
以下のコマンドの実行により、docker run を使用して pytest を実行します。
$ docker run -i --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pytest \ public.ecr.aws/glue/aws-glue-libs:5 \ -c "python3 -m pytest --disable-warnings"
pytest がユニットテストの実行を完了すると、出力は次のようになります。
============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-8.3.4, pluggy-1.5.0 rootdir: /home/hadoop/workspace plugins: integration-mark-0.2.0 collected 1 item tests/test_sample.py . [100%] ======================== 1 passed, 1 warning in 34.28s =========================
Visual Studio Code を使用するためのコンテナのセットアップ
Visual Studio Code でコンテナを設定するには、次の手順を実行します。
Visual Studio Code をインストールします。
Python
をインストールします。 Visual Studio Code Remote – コンテナ
をインストールします。 Visual Studio Code でワークスペースフォルダを開きます。
Ctrl+Shift+P(Windows/Linux) またはCmd+Shift+P(Mac) を押します。「
Preferences: Open Workspace Settings (JSON)」と入力します。Enter キーを押します。
次の JSON を貼り付け、保存します。
{ "python.defaultInterpreterPath": "/usr/bin/python3.11", "python.analysis.extraPaths": [ "/usr/lib/spark/python/lib/py4j-0.10.9.7-src.zip:/usr/lib/spark/python/:/usr/lib/spark/python/lib/", ] }
コンテナを設定するには:
-
Docker コンテナを実行します。
$ docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_pyspark \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark -
Visual Studio Code を起動します。
-
左側のメニューで [Remote Explorer] (リモートエクスプローラー) を選択した上で、
amazon/aws-glue-libs:glue_libs_4.0.0_image_01を選択します。 -
右クリックし、[Attach in Current Window] (現在のウィンドウにアタッチする) を選択します。
![右クリックすると、[Attach in Current Window] のオプションを含むウィンドウが表示されます。](images/vs-code-other-containers.png)
-
次のダイアログが表示されたら、[Got it] (取得しました) を選択します。
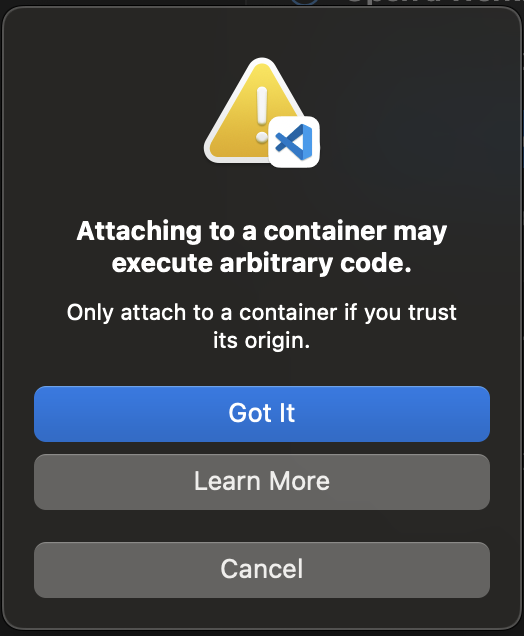
-
/home/handoop/workspace/を開きます。![[Workspace] (ワークスペース) オプションを含むウィンドウ ドロップダウンが強調表示されます。](images/vs-code-open-workspace.png)
-
AWS Glue PySpark スクリプトを作成し、[Run] (実行) を選択します。
このスクリプトは正常に実行されたことが表示されます。
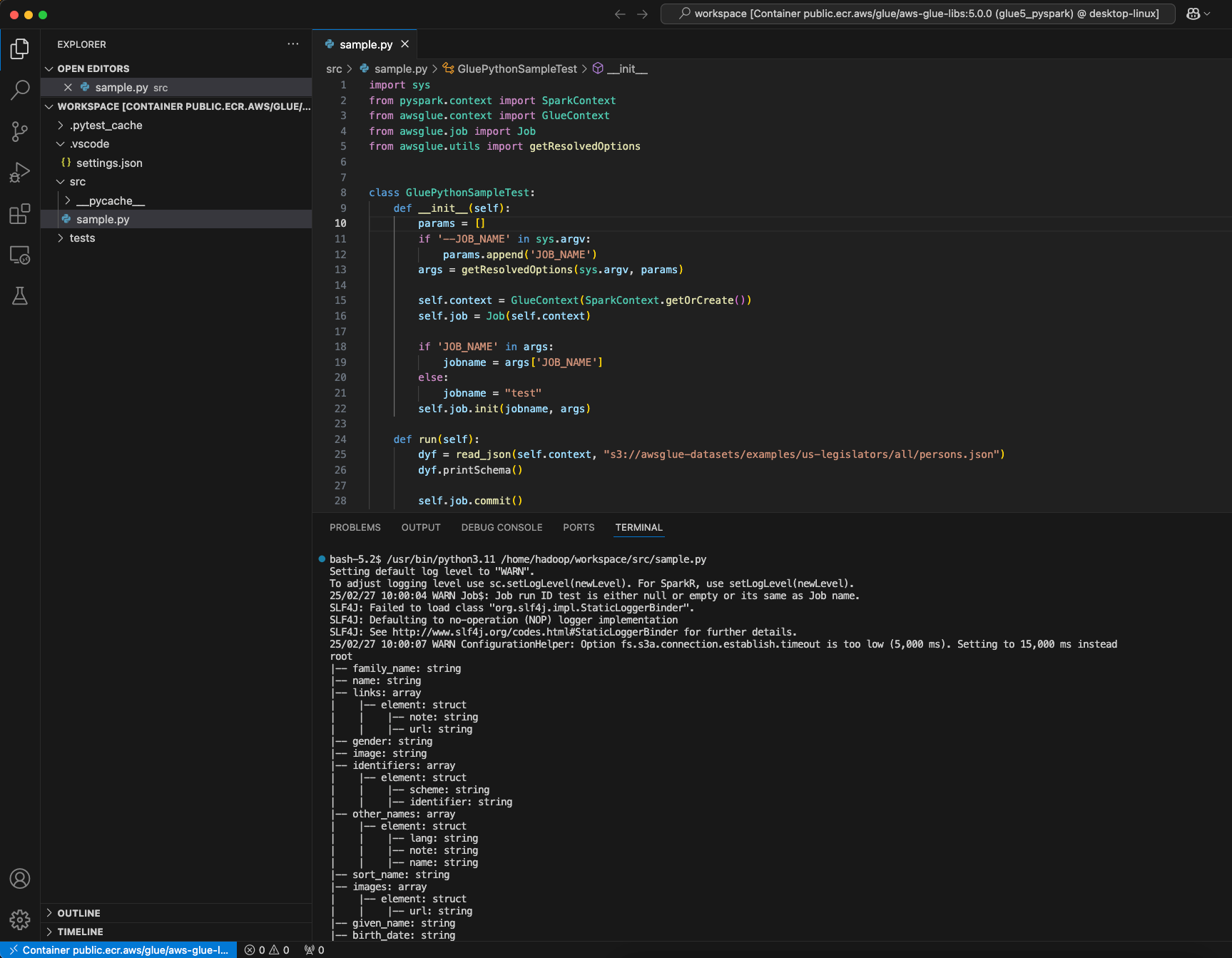
AWS Glue 4.0 と AWS Glue 5.0 の Docker イメージの変更点
AWS Glue 4.0 と AWS Glue 5.0 の Docker イメージの主な変更点:
-
AWS Glue 5.0 では、バッチジョブとストリーミングジョブの両方に 1 つのコンテナイメージがあります。これは、バッチ用とストリーミング用にそれぞれ別のイメージがあった Glue 4.0 とは異なります。
-
AWS Glue 5.0 では、コンテナのデフォルトのユーザー名は
hadoopです。AWS Glue 4.0 では、デフォルトのユーザー名はglue_userでした。 -
AWS Glue 5.0 では、JupyterLab や Livy など、いくつかの追加ライブラリがイメージから削除されています。これらのライブラリは手動でインストールできます。
-
AWS Glue 5.0 では、Iceberg、Hudi、Delta のすべてのライブラリがデフォルトでプリロードされるようになり、環境変数
DATALAKE_FORMATSは不要になりました。AWS Glue 4.0 以前は、環境変数DATALAKE_FORMATSを使用して、ロードする特定のテーブル形式を指定していました。
上記のリストは Docker イメージ固有のものです。AWS Glue 5.0 の更新の詳細については、「Introducing AWS Glue 5.0 for Apache Spark
考慮事項
AWS Glue コンテナイメージを使用してジョブスクリプトをローカルで開発する場合、以下の機能はサポートされていないことに注意してください。
-
AWS Glue Parquet ライター (AWS Glue で Parquet 形式を使用する場合)
-
Amazon S3 パスから JDBC ドライバーをロードする際の customJdbcDriverS3Path プロパティ
-
AWS Lake Formation アクセス許可ベースの認証情報供給
付録: JDBC ドライバーと Java ライブラリの追加
コンテナで現在使用できない JDBC ドライバーを追加するには、必要な JAR ファイルを使用してワークスペースの下に新しいディレクトリを作成し、Docker 実行コマンド内でディレクトリを /opt/spark/jars/ にマウントします。コンテナ内の /opt/spark/jars/ の下にある JAR ファイルは Spark Classpath に自動的に追加され、ジョブの実行中に使用できます。
たとえば、次の Docker 実行コマンドを使用して、PySpark REPL シェルに JDBC ドライバー jar を追加できます。
docker run -it --rm \ -v ~/.aws:/home/hadoop/.aws \ -v $WORKSPACE_LOCATION:/home/hadoop/workspace/ \ -v $WORKSPACE_LOCATION/jars/:/opt/spark/jars/ \ --workdir /home/hadoop/workspace \ -e AWS_PROFILE=$PROFILE_NAME \ --name glue5_jdbc \ public.ecr.aws/glue/aws-glue-libs:5 \ pyspark
「考慮事項」で強調されているように、customJdbcDriverS3Path 接続オプションを使用して Amazon S3 から AWS Glue コンテナイメージにカスタム JDBC ドライバーをインポートすることはできません。
