翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
高度なルールタイプを使用したルールベースのマッチングワークフローの作成
前提条件
ルールベースのマッチングワークフローを作成する前に、以下を行う必要があります。
-
スキーママッピングを作成します。詳細については、「スキーママッピングの作成」を参照してください。
-
Connect Customer Profiles を出力先として使用する場合は、適切なアクセス許可が設定されていることを確認してください。
次の手順では、 AWS Entity Resolution コンソールまたは CreateMatchingWorkflow API を使用して、高度なルールタイプでルールベースのマッチングワークフローを作成する方法を示します。
- Console
-
コンソールを使用してアドバンストルールタイプでルールベースのマッチングワークフローを作成するには
-
にサインイン AWS マネジメントコンソール し、https://console.aws.amazon.com/entityresolution/
で AWS Entity Resolution コンソールを開きます。 -
左側のナビゲーションペインのワークフローで、一致を選択します。
-
一致するワークフローページの右上隅で、一致するワークフローの作成を選択します。
-
ステップ 1: 一致するワークフローの詳細を指定するには、以下を実行します。
-
一致するワークフロー名とオプションの 説明を入力します。
-
データ入力で、、AWS リージョンAWS Glue データベース、AWS Glue テーブルを選択し、対応するスキーママッピングを選択します。
最大 19 個のデータ入力を追加できます。
注記
高度なルールを使用するには、スキーママッピングが次の要件を満たしている必要があります。
-
各入力フィールドは、フィールドがグループ化されていない限り、一意の一致キーにマッピングする必要があります。
-
入力フィールドがグループ化されている場合、同じ一致キーを共有できます。
たとえば、次のスキーママッピングはアドバンストルールで有効です。
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }この場合、
firstNameフィールドとlastNameフィールドはグループ化され、同じ名前一致キーを共有します。これは許可されます。高度なルールを使用するには、フィールドが適切にグループ化されていない限り、スキーママッピングを確認し、この one-to-oneの一致ルールに従うように更新します。
-
データテーブルに DELETE 列がある場合、スキーママッピングのタイプは でなければならず
String、matchKeyと を持つことはできませんgroupName。
-
-
データの正規化オプションはデフォルトで選択され、一致する前にデータ入力が正規化されます。データを正規化しない場合は、データの正規化オプションの選択を解除します。
注記
正規化は、スキーママッピングの作成で以下のシナリオでのみサポートされています。
-
名前サブタイプがグループ化されている場合: 名、ミドルネーム、姓。
-
住所サブタイプがグループ化されている場合: 住所 1、住所 2、住所 3、市区町村、州、国、郵便番号。
-
電話番号サブタイプがグループ化されている場合: 電話番号、電話番号の国コード。
-
-
サービスアクセス許可を指定するには、 オプションを選択し、推奨アクションを実行します。
オプション 推奨されるアクション 新しいサービスロールを作成して使用 -
AWS Entity Resolution は、このテーブルに必要なポリシーを持つサービスロールを作成します。
-
デフォルトの [サービスロール名] は
entityresolution-matching-workflow-<timestamp>です。 -
ロールを作成してポリシーをアタッチするアクセス許可が必要です。
-
入力データが暗号化されている場合、このデータは KMS キーオプションで暗号化され、データ入力の復号に使用される AWS KMS キーを入力できます。
既存のサービスロールを使用 -
ドロップダウンリストから [既存のサービスロール名] を選択します。
ロールを一覧表示するアクセス許可がある場合は、ロールのリストが表示されます。
ロールを一覧表示するアクセス許可がない場合は、使用するロールの Amazon リソースネーム (ARN) を入力できます。
既存のサービスロールがない場合、[既存のサービスロールを使用] オプションは使用できません。
-
[IAM で表示] 外部リンクを選択してサービスロールを表示します。
デフォルトでは、 AWS Entity Resolution は既存のロールポリシーを更新して必要なアクセス許可を追加しようとしません。
-
-
(オプション) リソースのタグを有効にするには、新しいタグを追加を選択し、キーと値のペアを入力します。
-
[次へ] を選択します。
-
-
ステップ 2: 一致する手法を選択するには:
-
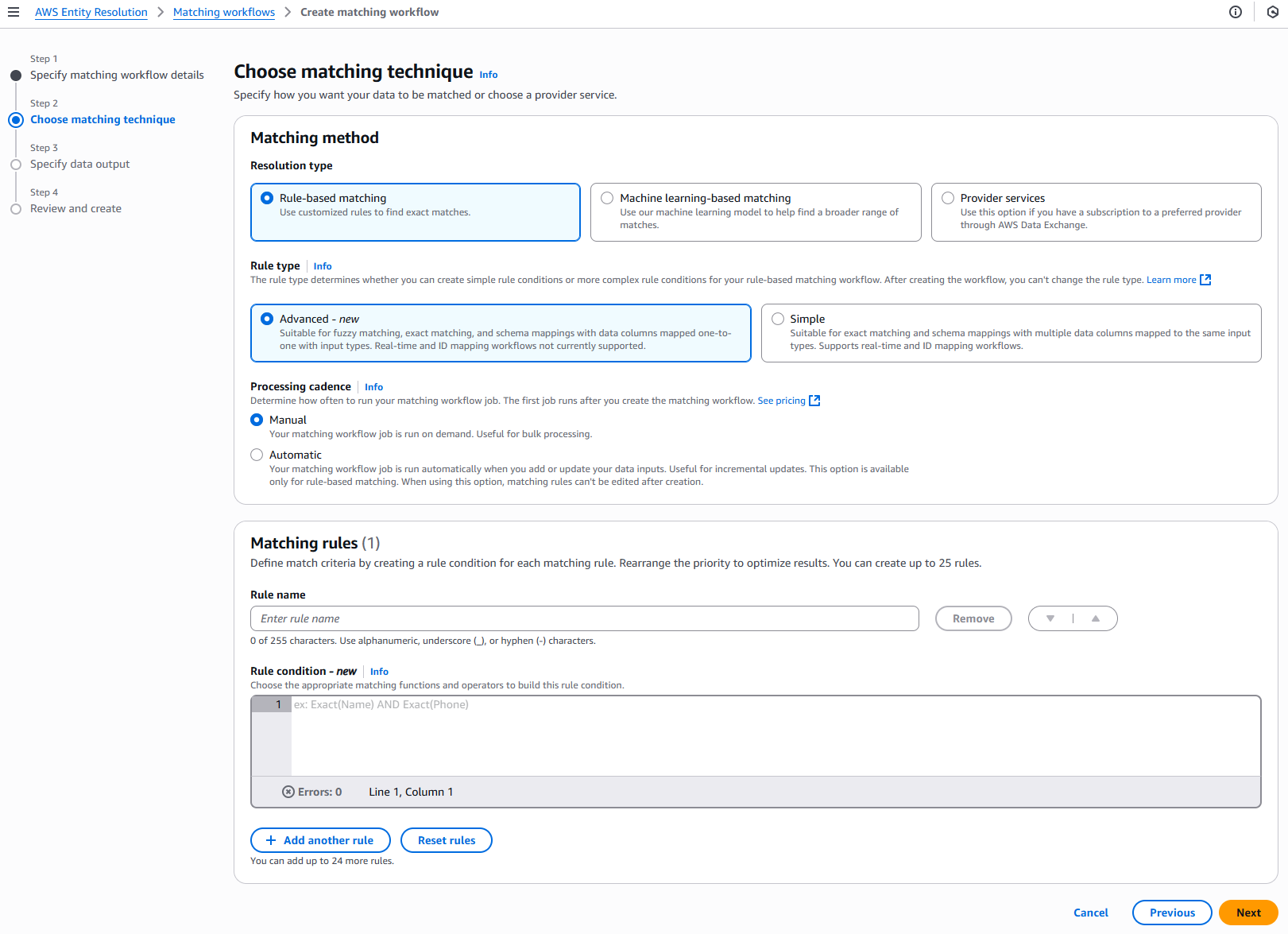
マッチングメソッドで、ルールベースのマッチングを選択します。
-
ルールタイプで、詳細 を選択します。
-
Processing cadence で、次のいずれかのオプションを選択します。
-
手動を選択して、一括更新のワークフローをオンデマンドで実行する
-
自動 を選択して、新しいデータが S3 バケットに保存されたらすぐにワークフローを実行します。
注記
自動 を選択した場合は、S3 バケットに対して Amazon EventBridge 通知が有効になっていることを確認します。S3 コンソールを使用して Amazon EventBridge を有効にする手順については、「Amazon S3 ユーザーガイド」の「Amazon EventBridge の有効化」を参照してください。 Amazon S3
-
-
一致するルールには、ルール名を入力し、目標に基づいてドロップダウンリストから適切な一致する関数と演算子を選択してルール条件を構築します。
最大 25 個のルールを作成できます。
注記
AWS Entity Resolution は、すべてのルールレベルのレコードを処理してマッチグループを推移的に接続する推移的マッチングもサポートしています。推移的マッチングは API のみの機能として使用できます。推移的マッチングが有効になっている場合、EmptyValues=Ignore 修飾子はサポートされていません。詳細については、「推移的マッチングの使用」を参照してください。
AND 演算子を使用して、あいまい一致関数 (Cosine、Levenshtein、または Soundex) と完全に一致する関数 (Exact、ExactManyToMany) を組み合わせる必要があります。
以下の表を使用して、目標に応じて使用する関数または演算子のタイプを決定できます。
目標 推奨される関数または演算子 推奨されるオプションの修飾子 メリット 正確なデータでは同じ文字列を一致させますが、空の値では一致しません。 完全一致 EmptyValues=Process 正確なデータで同じ文字列を一致させ、空の値を無視します。 Exact( matchKey)EmptyValues=無視 一致キー間で複数のレコードを一致させます。柔軟なペアリングに適しています。制限: 15 個の一致キー ExactManyToMany( matchKey、matchKey、...)該当なし データの数値表現間の類似性を測定しますが、空の値では一致しません。テキスト、数字、またはその両方の組み合わせに適しています。 コサイン EmptyValues=Process シンプルで効率的です。
TF-IDF 重み付けと組み合わせると、ロングテキストでうまく機能します。
単語ベースの完全一致に適しています。
データの数値表現間の類似性を測定し、空の値を無視します。 Cosine( matchKey、しきい値など)EmptyValues=無視 誤字、スペルエラー、転置を適切に処理します。
幅広い PII タイプに有効です。
短い文字列 (名前や電話番号など) に適しています。
ある単語を別の単語に変更するために必要な変更の最小数をカウントしますが、空の値では一致しません。スペルにわずかな違いがあるテキストに適しています。 レベンシュテイン EmptyValues=Process ある単語を別の単語に変更するために必要な変更の最小数をカウントし、空の値を無視します。 Levenshtein( matchKey、しきい値など)EmptyValues=無視 テキスト文字列は、どの程度類似しているが、空の値では一致しないかに基づいて比較およびマッチングします。スペルや発音のバリエーションがあるテキストに適しています。 Soundex EmptyValues=Process 音声マッチングに有効で、類似する単語を識別します。
高速で計算コストが低くなります。
発音は似ていますが、スペルが異なる名前を一致させるのに適しています。
テキスト文字列をどの程度類似しているかに基づいて比較して一致させ、空の値を無視します。 Soundex( matchKey)EmptyValues=無視 関数を結合します。 AND 該当なし 関数を区切ります。 または 該当なし 条件をグループ化してネストされた条件を作成します。 (…) 該当なし 例電話番号と E メールに一致するルール条件
以下は、電話番号 (電話一致キー) と E メールアドレス (E メールアドレス一致キー) のレコードに一致するルール条件の例です。
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)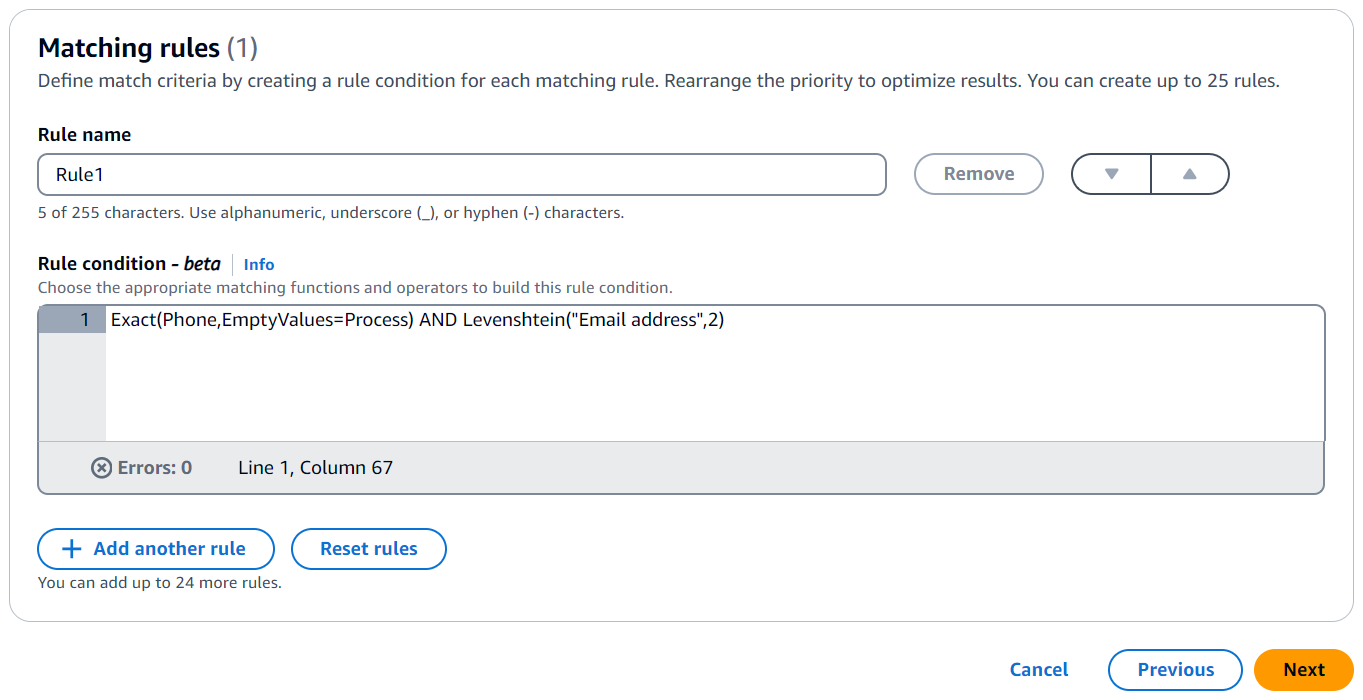
電話一致キーは、完全一致関数を使用して同一の文字列を一致させます。電話一致キーは、EmptyValues=Process 修飾子を使用して、一致の空の値を処理します。
E メールアドレス一致キーは、Levenshtein マッチング関数を使用して、デフォルトの Levenshtein Distance アルゴリズムしきい値 2 を使用してデータをスペルミスと照合します。E メール一致キーは、オプションの修飾子を使用しません。
AND 演算子は、完全一致関数と Levenshtein 一致関数を組み合わせます。
例 ExactManyToMany を使用してマッチキーマッチングを実行するルール条件
以下は、3 つのアドレスフィールド (HomeAddress 一致キー、BillingAddress 一致キー、および ShippingAddress 一致キー) のレコードを照合するルール条件の例です。いずれかのレコードに同じ値があるかどうかをチェックして、一致する候補を見つけます。
ExactManyToMany演算子は、指定されたアドレスフィールドの可能なすべての組み合わせを評価して、2 つ以上のアドレス間の完全一致を特定します。たとえば、 がBillingAddressまたはHomeAddressに一致するかどうかShippingAddress、または 3 つのアドレスすべてが正確に一致するかどうかを検出します。ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)例クラスタリングを使用するルール条件
あいまいな条件での高度なルールベースのマッチングでは、システムは完全一致に基づいて最初にレコードをクラスターにグループ化します。これらの初期クラスターが作成されると、システムはあいまい一致フィルターを適用して、各クラスター内の追加の一致を特定します。最適なパフォーマンスを得るには、データパターンに基づいて完全一致条件を選択して、明確に定義された初期クラスターを作成する必要があります。
以下は、複数の完全一致とあいまい一致要件を組み合わせたルール条件の例です。
AND演算子を使用して、、生年月日 (DOB)FullName、およびAddressの 3 つのフィールドがレコード間で正確に一致することをチェックします。また、 の Levenshtein 距離を使用して、InternalIDフィールドのわずかなバリエーションも可能です1。Levenshtein の距離は、ある文字列を別の文字列に変更するために必要な 1 文字の編集の最小数を測定します。距離が 1 の場合、一致するInternalIDs文字は 1 文字だけ異なります (1 つのタイプミス、削除、挿入など)。この条件の組み合わせは、識別子にわずかな不一致がある場合でも、同じエンティティを表す可能性が非常に高いレコードを識別するのに役立ちます。Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
[次へ] を選択します。
-
-
ステップ 3: データ出力と形式を指定するには:
-
データ出力の送信先と形式については、データ出力の Amazon S3 の場所と、データ形式を正規化データまたは元のデータのどちらにするかを選択します。
-
暗号化 で、暗号化設定をカスタマイズする場合は、AWS KMS キー ARN を入力します。
-
システム生成出力を表示します。
-
データ出力では、含める、非表示にする、またはマスクするフィールドを決定し、目標に基づいて推奨アクションを実行します。
目標 推奨されるアクション フィールドを含める 出力状態をインクルードのままにします。 フィールドを非表示 (出力から除外) Output フィールドを選択し、Hide を選択します。 マスクフィールド 出力フィールドを選択し、ハッシュ出力を選択します。 以前の設定をリセットする [リセット] を選択します。 -
[次へ] を選択します。
-
-
ステップ 4: 確認して作成する:
-
前のステップで行った選択内容を確認し、必要に応じて編集します。
-
Create and run を選択します。
一致するワークフローが作成され、ジョブが開始されたことを示すメッセージが表示されます。
-
-
一致するワークフローの詳細ページのメトリクスタブで、「最後のジョブメトリクス」で以下を表示します。
-
ジョブ ID。
-
一致するワークフロージョブのステータス: Queued、In progress、Completed、Failed
-
ワークフロージョブの完了時刻。
-
処理されたレコードの数。
-
処理されていないレコードの数。
-
生成された一意の一致 IDs。
-
入力レコードの数。
ジョブ履歴で以前に実行された一致するワークフロージョブのジョブメトリクスを表示することもできます。
-
-
一致するワークフロージョブが完了したら (ステータスが完了)、データ出力タブに移動し、Amazon S3 の場所を選択して結果を表示できます。
-
(手動処理タイプのみ) 手動処理タイプを使用してルールベースのマッチングワークフローを作成した場合は、一致するワークフローの詳細ページでワークフローの実行を選択して、一致するワークフローをいつでも実行できます。
-
(自動処理タイプのみ) データテーブルに DELETE 列がある場合:
-
DELETE 列で
trueに設定されたレコードは削除されます。 -
DELETE 列で
falseに設定されたレコードは S3 に取り込まれます。
詳細については、「ステップ 1: ファーストパーティーデータテーブルを準備する」を参照してください。
-
-
- API
-
API を使用してアドバンストルールタイプでルールベースのマッチングワークフローを作成するには
注記
デフォルトでは、ワークフローは標準 (バッチ) 処理を使用します。増分 (自動処理) を使用するには、明示的に設定する必要があります。
-
ターミナルまたはコマンドプロンプトを開いて API リクエストを行います。
-
次のエンドポイントへの POST リクエストを作成します。
/matchingworkflows -
リクエストヘッダーで、Content-type を application/json に設定します。
注記
サポートされているプログラミング言語の完全なリストについては、 AWS Entity Resolution API リファレンスを参照してください。
-
リクエスト本文には、次の必須 JSON パラメータを指定します。
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "string説明は以下のとおりです。
-
workflowName(必須) – 一意で、パターン [a-zA-Z_0-9-] に一致する 1~255 文字である必要があります* -
inputSourceConfig(必須) – 1~20 個の入力ソース設定のリスト -
outputSourceConfig(必須) — 正確に 1 つの出力ソース設定 -
resolutionTechniques(必須) – ルールベースのマッチングの resolutionType として「RULE_MATCHING」に設定する -
roleArn(必須) – ワークフロー実行用の IAM ロール ARN -
ruleConditionProperties(必須) – ルール条件のリストと一致するルールの名前。
オプションパラメータは次のとおりです。
-
description– 最大 255 文字 -
incrementalRunConfig– 増分実行タイプ設定 -
tags— 最大 200 個のキーと値のペア
-
-
(オプション) デフォルトの標準 (バッチ) 処理の代わりに増分処理を使用するには、リクエスト本文に次のパラメータを追加します。
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
リクエストを送信します。
-
成功すると、ステータスコード 200 と以下を含む JSON 本文を含むレスポンスを受け取ります。
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
呼び出しが失敗すると、次のいずれかのエラーが表示されることがあります。
-
400 – ワークフロー名が既に存在する場合の ConflictException
-
400 – 入力が検証に失敗した場合の ValidationException
-
402 – ExceedsLimitException
-
403 – 十分なアクセスがない場合の AccessDeniedException
-
429 – リクエストがスロットリングされた場合の ThrottlingException
-
500 – 内部サービスに障害が発生した場合の InternalServerException
-
-
