翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Amazon EMR on EKS での Lake Formation の有効化
Amazon EMR リリース 7.7 以降では、 AWS Lake Formation を活用して、Amazon S3 がサポートする Data Catalog テーブルにきめ細かなアクセスコントロールを適用できます。この機能を使用することにより、Amazon EMR on EKS Spark ジョブ内の読み取りクエリのテーブル、行、列、セルレベルのアクセスコントロールを設定できます。
このセクションでは、セキュリティ設定を作成し、Amazon EMR と連携するように Lake Formation を設定する方法について説明します。Lake Formation 用に作成したセキュリティ設定を使用してクラスターを作成する方法についても説明します。これらのセクションは順番に完了することを目的としています。
ステップ 1: Lake Formation ベースの列、行、セルレベルのアクセス許可を設定する
まず、Lake Formation で行レベルおよび列レベルのアクセス許可を適用するには、データレイク管理者が LakeFormationAuthorizedCaller セッションタグを設定します。Lake Formation は、このセッションタグを使用して発信者を承認し、データレイクへのアクセス権限を付与します。
AWS Lake Formation コンソールに移動し、サイドバーの管理セクションからアプリケーション統合設定オプションを選択します。その後、[外部エンジンが、Lake Formation に登録された Amazon S3 ロケーション内のデータをフィルタリングすることを許可する] チェックボックスをオンにします。Spark ジョブが実行されているであろう AWS アカウント ID とセッションタグの値を追加します。
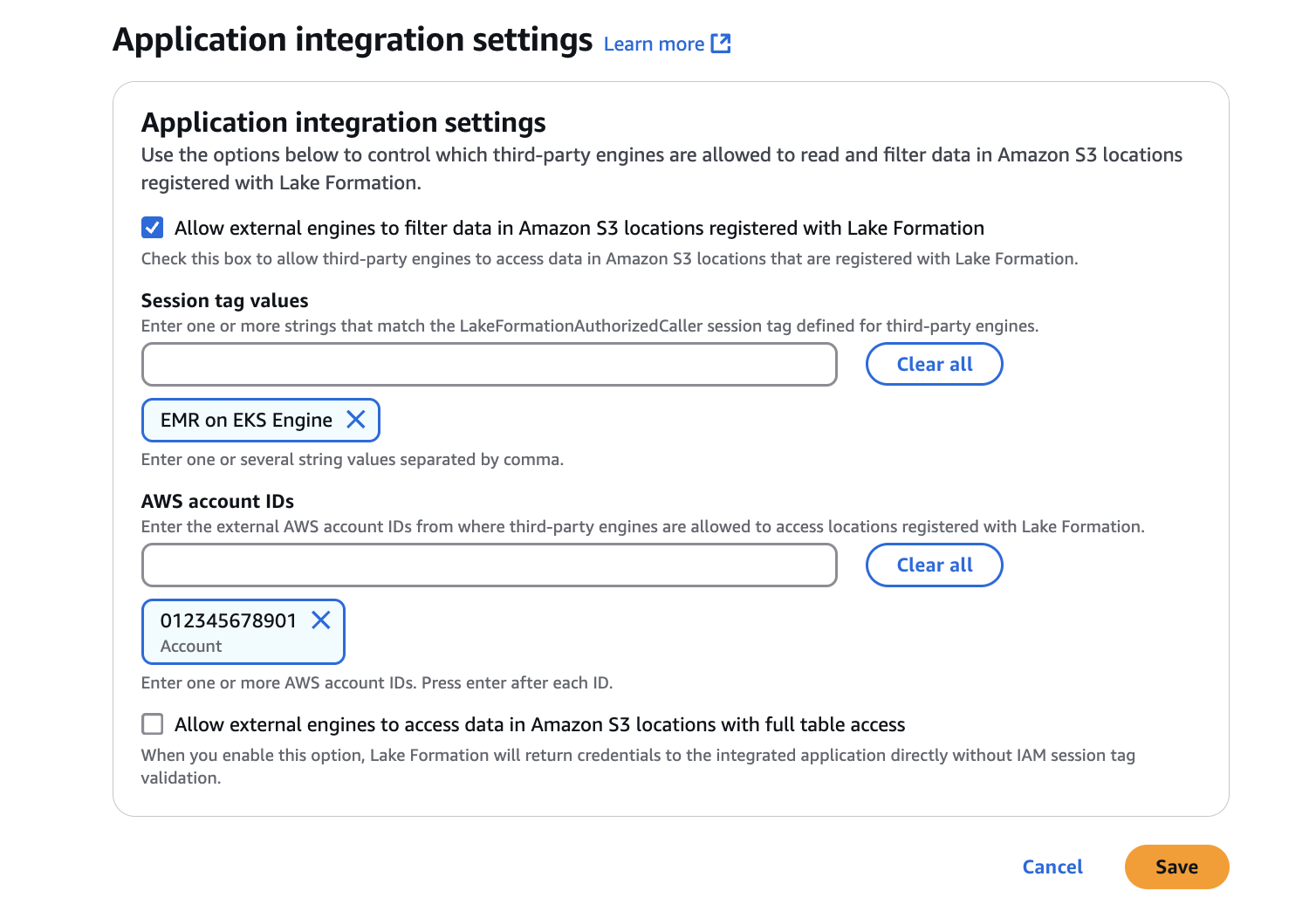
ここで渡された LakeFormationAuthorizedCalle セッションタグは、後ほどセクション 3 で IAM ロールを設定するときに SecurityConfiguration に渡されることに注意してください。
ステップ 2: EKS RBAC アクセス許可を設定する
次に、ロールベースのアクセスコントロールのアクセス許可を設定します。
Amazon EMR on EKS サービスに EKS クラスターのアクセス許可を付与する
Amazon EMR on EKS Service には EKS クラスターロールのアクセス許可が必要です。これにより、システムドライバーがユーザー名前空間のユーザーエグゼキュターをスピンオフするためのクロス名前空間アクセス許可を作成できます。
クラスターのロールの作成
このサンプルでは、リソースのコレクションに対するアクセス許可を定義します。
vim emr-containers-cluster-role.yaml --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: emr-containers rules: - apiGroups: [""] resources: ["namespaces"] verbs: ["get"] - apiGroups: [""] resources: ["serviceaccounts", "services", "configmaps", "events", "pods", "pods/log"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: [""] resources: ["secrets"] verbs: ["create", "patch", "delete", "watch"] - apiGroups: ["apps"] resources: ["statefulsets", "deployments"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["batch"] resources: ["jobs"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["extensions", "networking.k8s.io"] resources: ["ingresses"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "annotate", "patch", "label"] - apiGroups: ["rbac.authorization.k8s.io"] resources: ["clusterroles","clusterrolebindings","roles", "rolebindings"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: [""] resources: ["persistentvolumeclaims"] verbs: ["get", "list", "watch", "describe", "create", "edit", "delete", "deletecollection", "annotate", "patch", "label"] - apiGroups: ["kyverno.io"] resources: ["clusterpolicies"] verbs: ["create", "delete"] ---
kubectl apply -f emr-containers-cluster-role.yaml
クラスターロールバインディングの作成
vim emr-containers-cluster-role-binding.yaml --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: emr-containers subjects: - kind: User name: emr-containers apiGroup: rbac.authorization.k8s.io roleRef: kind: ClusterRole name: emr-containers apiGroup: rbac.authorization.k8s.io ---
kubectl apply -f emr-containers-cluster-role-binding.yaml
Amazon EMR on EKS サービスへの名前空間アクセスを提供する
2 つの Kubernetes 名前空間を作成します。1 つは User ドライバーとエグゼキュター用、もう 1 つは System ドライバーとエグゼキュター用で、Amazon EMR on EKS サービスアクセスを有効にして User と System の名前空間の両方でジョブを送信します。既存のガイドに従って、 「aws-auth を使用してクラスターアクセスを有効にする」で利用可能な各名前空間へのアクセスを提供します。
ステップ 3: ユーザーおよびシステムプロファイルコンポーネントの IAM ロールを設定する
3 つ目は、特定のコンポーネントのロールを設定することです。Lake Formation 対応の Spark ジョブには、ユーザーとシステムの 2 つのコンポーネントがあります。ユーザードライバーとエグゼキュターは User 名前空間で実行され、StartJobRun API で渡される JobExecutionRole に関連付けられます。システムドライバーとエグゼキュターはシステム名前空間で実行され、QueryEngine ロールに関連付けられます。
クエリエンジンロールを設定する
QueryEngine ロールはシステムスペースコンポーネントに関連付けられており、LakeFormationAuthorizedCaller セッションタグを持つ JobExecutionRole を引き受けるアクセス許可を持ちます。クエリエンジンロールの IAM アクセス許可ポリシーは以下のとおりです:
クエリエンジンロールの信頼ポリシーを設定して、Kubernetes System 名前空間を信頼します。
aws emr-containers update-role-trust-policy \ --cluster-nameeks cluster\ --namespaceeks system namespace\ --role-namequery_engine_iam_role_name
詳細については、「ロール信頼ポリシーの更新」を参照してください。
ジョブ実行ロールを設定する
Lake Formation のアクセス許可は、Glue Data Catalog AWS リソース、Amazon S3 ロケーション、およびそれらのロケーションの基盤となるデータへのアクセスを制御します。IAM アクセス許可は、Lake Formation および AWS Glue APIs とリソースへのアクセスを制御します。データカタログ内のテーブルにアクセスするための Lake Formation アクセス許可 (SELECT) を持っていても、glue:Get* API オペレーションに対する IAM アクセス許可がない場合、操作は失敗します。
JobExecutionRole の IAM アクセス許可ポリシー: JobExecution ロールには、アクセス許可ポリシーにポリシーステートメントが必要です。
JobExecutionRole の IAM 信頼ポリシー:
Kubernetes ユーザー名前空間を信頼するようにジョブ実行ロールの信頼ポリシーを設定します:
aws emr-containers update-role-trust-policy \ --cluster-nameeks cluster\ --namespaceeks User namespace\ --role-namejob_execution_role_name
詳細については、「Update the trust policy of the job execution role」を参照してください。
ステップ 4: セキュリティ設定をセットアップする
Lake Formation 対応ジョブを実行するには、セキュリティ設定を作成しなければなりません。
aws emr-containers create-security-configuration \ --name 'security-configuration-name' \ --security-configuration '{ "authorizationConfiguration": { "lakeFormationConfiguration": { "authorizedSessionTagValue": "SessionTag configured in LakeFormation", "secureNamespaceInfo": { "clusterId": "eks-cluster-name", "namespace": "system-namespace-name" }, "queryEngineRoleArn": "query-engine-IAM-role-ARN" } } }'
authorizedSessionTagValue フィールドに渡されたセッションタグが Lake Formation を認可できることを確認します。ステップ 1: Lake Formation ベースの列、行、セルレベルのアクセス許可を設定する の値を Lake Formation で設定された値に設定します。
ステップ 5: 仮想クラスターを作成する
セキュリティ設定を使用して Amazon EMR on EKS 仮想クラスターを作成します。
aws emr-containers create-virtual-cluster \ --name my-lf-enabled-vc \ --container-provider '{ "id": "eks-cluster", "type": "EKS", "info": { "eksInfo": { "namespace": "user-namespace" } } }' \ --security-configuration-idSecurityConfiguraionId
Lake Formation 認可設定が仮想クラスターで実行されているすべてのジョブに適用されるように、前のステップの SecurityConfiguration ID が渡されていることを確認します。詳細については、「Register the Amazon EKS cluster with Amazon EMR」を参照してください。
ステップ 6: FGAC 対応 VirtualCluster でジョブを送信する
ジョブ送信プロセスは、Lake Formation 以外のジョブでも Lake Formation ジョブでも同じです。詳細については、「Submit a job run StartJobRun」を参照してください。
システムドライバーの Spark ドライバー、エグゼキュター、イベントログは、デバッグのために AWS サービスアカウントの S3 バケットに保存されます。ジョブ実行でカスタマー管理の KMS キーを設定して、 AWS サービスバケットに保存されているすべてのログを暗号化することをお勧めします。ログ暗号化の有効化の詳細については、「Encrypting Amazon EMR on EKS logs」を参照してください。
