翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での EMR Serverless を使用したAWS Lake Formationきめ細かなアクセスコントロール
概要
Amazon EMR リリース 7.2.0 以降では、 AWS Lake Formationを活用して、S3 でバックアップされた Data Catalog テーブルにきめ細かなアクセスコントロールを適用します。この機能を使用すると、Amazon EMR Serverless Spark ジョブ内の read クエリにテーブル、行、列、セルレベルのアクセスコントロールを設定できます。Apache Spark バッチジョブとインタラクティブセッションできめ細かなアクセスコントロールを設定するには、EMR Studio を使用します。Lake Formation の詳細と EMR Serverless での使用方法については、以下のセクションを参照してください。
で Amazon EMR Serverless を使用すると、追加料金AWS Lake Formationが発生します。詳細については、「Amazon EMR の料金
EMR Serverless と の連携方法AWS Lake Formation
EMR Serverless と Lake Formation を使用すると、各 Spark ジョブにアクセス許可のレイヤーを適用して、EMR Serverless がジョブを実行するときに Lake Formation アクセス許可コントロールを適用できます。EMR Serverless は、Spark リソースプロファイル
Lake Formation で事前初期化された容量を使用する場合は、少なくとも 2 つの Spark ドライバーを使用することを提案します。Lake Formation 対応ジョブごとに 2 つの Spark ドライバー (1 つはユーザープロファイル用、1 つはシステムプロファイル用) を使用します。最高のパフォーマンスを得るには、Lake Formation を使用しない場合と比較して、Lake Formation 対応ジョブのドライバーの数を 2 倍にします。
EMR Serverless で Spark ジョブを実行するときは、リソース管理とクラスターパフォーマンスに対する動的割り当ての影響も考慮します。リソースプロファイルあたりのエグゼキュターの最大数である spark.dynamicAllocation.maxExecutors の設定は、ユーザーエグゼキュターとシステムエグゼキュターに適用されます。その数を最大許容エグゼキュター数と等しく設定すると、利用可能なすべてのリソースを使用する 1 つのタイプのエグゼキュターが原因でジョブの実行が停止し、ジョブの実行時に他のエグゼキュターが使用できなくなる可能性があります。
したがって、リソースが不足しないように、EMR Serverless はリソースプロファイルあたりのデフォルトの最大エグゼキュター数を spark.dynamicAllocation.maxExecutors 値の 90% に設定します。この設定は、spark.dynamicAllocation.maxExecutorsRatio を 0 から 1 までの値で指定すると上書きできます。さらに、リソースの割り当てと全体的なパフォーマンスを最適化するために、次のプロパティを設定します。
-
spark.dynamicAllocation.cachedExecutorIdleTimeout -
spark.dynamicAllocation.shuffleTracking.timeout -
spark.cleaner.periodicGC.interval
以下は、EMR Serverless が Lake Formation セキュリティポリシーで保護されたデータにアクセスする方法の概要を示します。
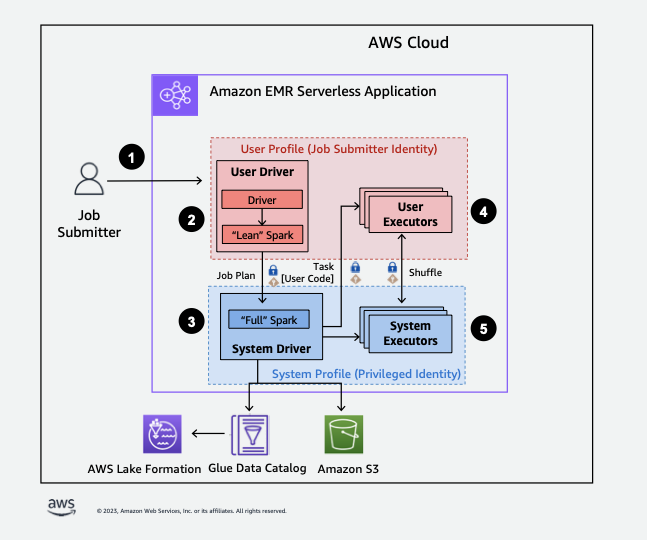
-
ユーザーは、Spark ジョブをAWS Lake Formation有効な EMR Serverless アプリケーションに送信します。
-
EMR Serverless はジョブをユーザードライバーに送信し、ユーザープロファイルでジョブを実行します。ユーザードライバーは、タスクの起動、エグゼキュターのリクエスト、S3 または Glue カタログへのアクセスができない Spark のリーンバージョンを実行します。ジョブプランを構築します。
-
EMR Serverless は、システムドライバーと呼ばれる 2 番目のドライバーを設定し、システムプロファイルで (特権 ID を使用して) 実行します。EMR Serverless は、通信用の 2 つのドライバー間に暗号化された TLS チャネルを設定します。ユーザードライバーはチャネルを使用して、ジョブプランをシステムドライバーに送信します。システムドライバーは、ユーザーが送信したコードを実行しません。フル Spark を実行して、データアクセスのために S3 およびデータカタログと通信します。エグゼキュターをリクエストし、ジョブプランを一連の実行ステージにコンパイルします。
-
次に、EMR Serverless はユーザードライバーまたはシステムドライバーを使用してエグゼキュターでステージを実行します。どのステージのユーザーコードも、ユーザープロファイルのエグゼキュターでのみ実行されます。
-
で保護された Data Catalog テーブルからデータを読み取るステージAWS Lake Formation、またはセキュリティフィルターを適用するステージは、システムエグゼキュターに委任されます。
Amazon EMR での Lake Formation の有効化
Lake Formation を有効にするには、EMR Serverless アプリケーションの作成時に、ランタイム設定パラメータの spark-defaults 分類で spark.emr-serverless.lakeformation.enabled を true に設定します。
aws emr-serverless create-application \ --release-label emr-7.13.0 \ --runtime-configuration '{ "classification": "spark-defaults", "properties": { "spark.emr-serverless.lakeformation.enabled": "true" } }' \ --type "SPARK"
EMR Studio で新しいアプリケーションを作成するときに Lake Formation を有効にすることもできます。[追加の設定] で利用可能な [Lake Formation のきめ細かなアクセスコントロールを使用する] を選択します。
EMR Serverless で Lake Formation を使用することにより、ワーカー間の暗号化がデフォルトで有効になるため、ワーカー間の暗号化を再度明示的に有効にする必要はありません。
Spark ジョブの Lake Formation の有効化
個々の Spark ジョブの Lake Formation を有効にするには、spark-submit の使用時に spark.emr-serverless.lakeformation.enabled を true に設定します。
--conf spark.emr-serverless.lakeformation.enabled=true
ジョブランタイムロールの IAM アクセス許可
Lake Formation のアクセス許可は、Glue Data Catalog AWSリソース、Amazon S3 ロケーション、およびそれらのロケーションの基盤となるデータへのアクセスを制御します。IAM アクセス許可は、Lake Formation および AWS Glue API とリソースへのアクセスを制御します。データカタログ内のテーブルにアクセスするための Lake Formation アクセス許可 (SELECT) を持っていても、glue:Get* API オペレーションに対する IAM アクセス許可がない場合、操作は失敗します。
以下は、S3 のスクリプトにアクセスするための IAM アクセス許可、S3 AWS へのログのアップロード、Glue API アクセス許可、Lake Formation へのアクセス許可を指定する方法のポリシー例です。
ジョブランタイムロールの Lake Formation アクセス許可の設定
まず、Hive テーブルの場所を Lake Formation に登録します。次に、目的のテーブルにジョブランタイムロールのアクセス許可を作成します。Lake Formation の詳細については、「What is?」を参照してくださいAWS Lake Formation。 「 AWS Lake Formationデベロッパーガイド」の「�
Lake Formation アクセス許可を設定したら、Amazon EMR Serverless で Spark ジョブを送信します。Spark ジョブの詳細については、「Spark example」を参照してください。
ジョブ実行の送信
Lake Formation 許可の設定が完了したら、EMR Serverless で Spark ジョブを送信できます。次のセクションでは、ジョブ実行プロパティを設定して送信する方法の例を示します。
アクセス許可の要件
に登録されていないテーブルAWS Lake Formation
に登録されていないテーブルの場合AWS Lake Formation、ジョブランタイムロールは AWSGlue データカタログと Amazon S3 の基盤となるテーブルデータの両方にアクセスします。これには、ジョブランタイムロールに Glue オペレーションと Amazon AWSS3 オペレーションの両方に対する適切な IAM アクセス許可が必要です。 Amazon S3
に登録されたテーブルAWS Lake Formation
に登録されたテーブルの場合AWS Lake Formation、ジョブランタイムロールは AWSGlue データカタログメタデータにアクセスし、Lake Formation によって提供された一時的な認証情報は Amazon S3 の基盤となるテーブルデータにアクセスします。オペレーションの実行に必要な Lake Formation のアクセス許可は、Spark ジョブが開始する AWSGlue データカタログと Amazon S3 API コールに依存し、次のように要約できます。
-
DESCRIBE アクセス許可により、ランタイムロールは Data Catalog 内のテーブルまたはデータベースメタデータを読み取ることができます。
-
ALTER アクセス許可により、ランタイムロールは Data Catalog のテーブルまたはデータベースメタデータを変更できます。
-
DROP アクセス許可により、ランタイムロールは Data Catalog からテーブルまたはデータベースメタデータを削除できます。
-
SELECT アクセス許可により、ランタイムロールは Amazon S3 からテーブルデータを読み取ることができます。
-
INSERT アクセス許可により、ランタイムロールは Amazon S3 にテーブルデータを書き込むことができます。
-
DELETE アクセス許可により、ランタイムロールは Amazon S3 からテーブルデータを削除できます。
注記
Lake Formation は、Spark ジョブが AWSGlue を呼び出してテーブルメタデータを取得し、Amazon S3 を呼び出してテーブルデータを取得するときに、アクセス許可を遅延的に評価します。アクセス許可が不十分なランタイムロールを使用するジョブは、Spark が欠落しているアクセス許可を必要とする AWSGlue または Amazon S3 呼び出しを行うまで失敗しません。
注記
次のサポートされているテーブルマトリックス:
-
サポート対象とマークされたオペレーションは、Lake Formation 認証情報のみを使用して、Lake Formation に登録されたテーブルのテーブルデータにアクセスします。Lake Formation のアクセス許可が不十分な場合、オペレーションはランタイムロールの認証情報にフォールバックしません。Lake Formation に登録されていないテーブルの場合、ジョブランタイムロールの認証情報はテーブルデータにアクセスします。
-
Amazon S3 ロケーションでの IAM アクセス許可でサポートとマークされたオペレーションは、Amazon S3 の基盤となるテーブルデータにアクセスするために Lake Formation 認証情報を使用しません。これらのオペレーションを実行するには、テーブルが Lake Formation に登録されているかどうかにかかわらず、ジョブランタイムロールにテーブルデータにアクセスするために必要な Amazon S3 IAM アクセス許可が必要です。
