このページの改善にご協力ください
このユーザーガイドに貢献するには、すべてのページの右側のペインにある「GitHub でこのページを編集する」リンクを選択してください。
クイックスタート: Amazon EKS での vLLM を使用した高スループット LLM 推論
序章
このクイックスタートガイドでは、テキストベースのリアルタイム推論アプリケーション向けに、vLLM と GPU を使用して Amazon EKS 上に大規模言語モデル (LLM) をデプロイするためのチュートリアルを提供します。
このソリューションでは、コンテナオーケストレーションに Amazon EKS を、効率的なモデルサービングに vLLM を活用し、GPU アクセラレーションと高スループットの推論サービングにより、スケーラブルな AI アプリケーションを構築できます。Llama 3.1 8B Instruct モデルはデモンストレーションに使用しますが、vLLM がサポートする他の LLM もデプロイできます (サポートされているモデルのリストについては、vLLM ドキュメント
EKS での vLLM アーキテクチャ

この手順を完了すると、スループットと低レイテンシーに最適化された vLLM 推論エンドポイントが作成され、チャットフロントエンドアプリケーションを介して Llama モデルとやり取りできるようになります。これにより、チャットボットアシスタントやその他の LLM ベースのアプリケーションにおける一般的なユースケースを示します。
追加のガイダンスと高度なデプロイリソースについては、「AI/ML ワークロード用の EKS ベストプラクティスガイド」と本番環境に対応した「AI on EKS inference charts
[開始する前に]
開始する前に、次のものがあることを確認します。
-
次の主要なコンポーネントを備えた Amazon EKS クラスター。G5 または G6 EC2 インスタンスファミリーを使用する Karpenter ノードプール、GPU 対応ワーカーノードにインストールされた NVIDIA Device Plugin、および S3 Mountpoint CSI ドライバーがインストールされていること。このベースライン設定を作成するには、「Amazon EKS でのリアルタイム推論のベストプラクティスクラスターセットアップガイド」のステップに従い、ステップ #4 の完了まで行います。
-
Hugging Face アカウント。サインアップするには、https://huggingface.co/login を参照してください。
Amazon S3 でモデルストレージをセットアップする
大規模な LLM ファイルを Amazon S3 に効率的に保存して、コンピューティングリソースからストレージを分離します。このアプローチにより、モデル更新が効率化され、コストが削減され、本番環境のセットアップにおける管理が簡素化されます。S3 は大量のファイルを確実に処理しますが、Mountpoint CSI ドライバーを介して Kubernetes と統合することで、ポッドはローカルストレージのようにモデルへアクセスできます。起動時に時間のかかるダウンロードは必要ありません。以下の手順に従って、S3 バケットを作成し、LLM をアップロードし、推論サービングコンテナでボリュームとしてマウントします。
EFS や FSx for Lustre など、モデルキャッシュ用の他のストレージソリューションも EKS で利用できます。詳しくは「EKS ベストプラクティス」をご確認ください。
環境変数を設定する
このガイドの後半で作成する新しい Amazon S3 バケットの一意の名前を作成します。作成したら、すべてのステップで同じバケット名を使用します。例えば、次のようになります。
MY_BUCKET_NAME=model-store-$(date +%s)
環境変数を定義し、ファイルに保存します。
cat << EOF > .env-quickstart-vllm export BUCKET_NAME=${MY_BUCKET_NAME} export AWS_REGION=us-east-1 export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) EOF
シェル環境に環境変数をロードします。現在のシェル環境を閉じて新しいシェル環境を開く場合は、次の同じコマンドを使用して環境変数を再度ソースしてください。
source .env-quickstart-vllm
モデルファイルを保存する S3 バケットを作成する
モデルファイルを保存する S3 バケットを作成します。
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}
Hugging Face からモデルをダウンロードする
Hugging Face は、LLM モデルにアクセスするための主要なモデルハブの 1 つです。Llama モデルをダウンロードするには、モデルライセンスを承諾し、トークン認証を設定する必要があります。
-
https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct で Llama 3.1 8B Instruct モデルのライセンスを承諾します。
-
アクセストークンを生成します ([プロファイル] > [設定] > [アクセストークン] に移動し、[読み取り] トークンタイプを使用して新しいトークンを作成します)。
Hugging Face トークンを使用して環境変数を設定します。
export HF_TOKEN=your_token_here
環境にまだインストールされていない場合は、pip3 パッケージをインストールします。Amazon Linux 2023 でのコマンド例を次に示します。
sudo dnf install -y python3-pip
Hugging Face CLI
pip install huggingface-hub
--exclude フラグを使用して Hugging Face から Llama-3.1-8B-Instruct モデル (~15 GB) をダウンロードします。のフラグにより、レガシーな PyTorch 形式をスキップし、最適化された safetensors 形式のファイルのみがダウンロードされるため、一般的な推論エンジンとの完全な互換性を維持しながら、ダウンロードサイズを削減できます。
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct \ --exclude "original/*" \ --local-dir ./llama-3.1-8b-instruct \ --token $HF_TOKEN
ダウンロードしたファイルを検証します。
$ ls llama-3.1-8b-instruct
正常な出力は次の例のようになります。
LICENSE config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json README.md generation_config.json model-00003-of-00004.safetensors special_tokens_map.json USE_POLICY.md model-00001-of-00004.safetensors model-00004-of-00004.safetensors tokenizer.json
モデルファイルをアップロードする
S3 転送パフォーマンスを向上させるために、AWS 共通ランタイム (CRT) を有効にします。CRT ベースの転送クライアントは、大規模なファイルオペレーションのスループットと信頼性を向上させます。
aws configure set s3.preferred_transfer_client crt
モデルをアップロードします。
aws s3 cp ./llama-3.1-8b-instruct s3://$BUCKET_NAME/llama-3.1-8b-instruct \ --recursive
正常な出力は次の例のようになります。
... upload: llama-3.1-8b-instruct/tokenizer.json to s3://model-store-1753EXAMPLE/llama-3.1-8b-instruct/tokenizer.json upload: llama-3.1-8b-instruct/model-00004-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00004-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00002-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00002-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00003-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00003-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00001-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00001-of-00004.safetensors
S3 Mountpoint CSI のアクセス許可を設定する
S3 Mountpoint CSI ドライバーを使用すると、Kubernetes と S3 のネイティブな統合が可能になり、ポッドがローカルストレージであるかのようにモデルファイルに直接アクセスできるため、コンテナの起動時にローカルコピーが不要になります。
S3 マウントポイントが S3 バケットから読み取れるように IAM ポリシーを作成します。
aws iam create-policy \ --policy-name S3BucketAccess-${BUCKET_NAME} \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:GetObjectVersion\", \"s3:ListBucket\", \"s3:GetBucketLocation\"], \"Resource\": [\"arn:aws:s3:::${BUCKET_NAME}\", \"arn:aws:s3:::${BUCKET_NAME}/*\"]}]}"
S3 Mountpoint CSI ドライバーのサービスアカウントの注釈を確認して、S3 Mountpoint CSI ドライバーで使用される IAM ロール名を見つけます。
ROLE_NAME=$(kubectl get serviceaccount s3-csi-driver-sa -n kube-system -o jsonpath='{.metadata.annotations.eks\.amazonaws\.com/role-arn}' | cut -d'/' -f2)
IAM ポリシーを S3 Mountpoint CSI ロールにアタッチします。
aws iam attach-role-policy \ --role-name ${ROLE_NAME} \ --policy-arn arn:aws:iam::${AWS_ACCOUNT_ID}:policy/S3BucketAccess-${BUCKET_NAME}
S3 Mountpoint CSI がクラスターにインストールされていない場合は、「Amazon EKS でのリアルタイム推論のベストプラクティスクラスターセットアップガイド」のデプロイ手順に従ってください。
S3 バケットを Kubernetes ボリュームとしてマウントする
永続ボリューム (PV) と永続ボリュームクレーム (PVC) を作成して、複数の推論ポッド間で S3 バケットへの読み取り専用アクセスを提供します。ReadOnlyMany アクセスモードでは、モデルファイルへの同時アクセスが保証され、CSI ドライバーが S3 バケットのマウントを処理します。
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: model-store spec: storageClassName: "" capacity: storage: 100Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain mountOptions: - region ${AWS_REGION} csi: driver: s3.csi.aws.com volumeHandle: model-store volumeAttributes: bucketName: ${BUCKET_NAME} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-store spec: storageClassName: "" volumeName: model-store accessModes: - ReadOnlyMany resources: requests: storage: 100Gi EOF
GPU インフラストラクチャのセットアップ
クラスターノード
「Amazon EKS でのリアルタイム推論のベストプラクティスクラスターセットアップガイド」で作成された EKS クラスターを使用しています。このクラスターには、vLLM コンテナイメージをダウンロードするのに十分なノードストレージを備えた GPU 対応ノードをプロビジョニングできる Karpenter ノードプールが含まれています。カスタム EKS クラスターを使用する場合は、GPU 対応ノードを起動できることを確認してください。
インスタンスの選択
LLM 推論に適したインスタンスを選択するには、使用可能な GPU メモリがモデルの重みをロードするのに十分であることを確認する必要があります。Llama 3.1 8B Instruct のモデル重みは約 16 GB (.safetensor モデルファイルのサイズ) であるため、モデルをロードするには、vLLM プロセスに少なくともこの量のメモリを提供する必要があります。
A10G GPU を搭載した Amazon G5 EC2 インスタンス
NVIDIA デバイスドライバー
NVIDIA ドライバーは、コンテナが GPU リソースに効率的にアクセスするために必要なランタイム環境を提供します。これにより、Kubernetes 内で GPU リソースの割り当てと管理が可能になり、GPU をスケジュール可能なリソースとして利用できるようになります。
クラスターは EKS Bottlerocket AMI を使用します。これには、すべての GPU 対応ノードに必要な NVIDIA デバイスドライバーとプラグインがすべて含まれており、追加のセットアップなしでコンテナ化されたワークロードの GPU アクセシビリティがすぐに確保されます。他のタイプの EKS ノードを使用している場合は、必要なすべてのドライバーとプラグインがインストールされていることを確認する必要があります。
GPU インフラストラクチャをテストする
以下の手順を実行してクラスターの GPU 機能をテストし、ポッドが NVIDIA GPU リソースにアクセスし、GPU 対応ノードで正しくスケジュールできることを確認します。
Nvidia SMI テストポッドをデプロイします。
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-nvidia-smi-test spec: restartPolicy: OnFailure tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker # Matches GPU NodePool's label containers: - name: cuda-container image: nvidia/cuda:12.9.1-base-ubuntu20.04 command: ["nvidia-smi"] resources: requests: memory: "24Gi" limits: nvidia.com/gpu: 1 EOF
ポッドログを確認して、GPU の詳細が以下の出力と同様にリストされていることを確認します (必ずしも同じ GPU モデルではありません)。
$ kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-nvidia-smi-test $ kubectl logs gpu-nvidia-smi-test
Wed Jul 30 15:39:58 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 | | 0% 30C P8 9W / 300W | 0MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
この出力は、ポッドが GPU リソースに正常にアクセスできることを示しています。
重要: このポッドは、「Amazon EKS でのリアルタイム推論のベストプラクティスクラスターセットアップガイド」の Karpenter ノードプールと一致する nodeSelector 設定を使用します。異なるノードプールを使用している場合は、それに応じて、ポッドが nodeSelector と Tolerations と一致することを確認してください。
推論コンテナをデプロイする
サービングスタックは、推論インフラストラクチャのパフォーマンスとスケーラビリティの両方の機能を決定します。vLLM は、本番環境向けデプロイにおける主要なソリューションとして位置付けられています。vLLM のアーキテクチャは、動的リクエスト処理のための継続的なバッチ処理、より高速な推論のためのカーネル最適化、および PagedAttention による効率的な GPU メモリ管理を提供します。これらの機能は、本番環境に対応した REST API および一般的なモデル形式のサポートと組み合わせることで、高性能な推論デプロイに最適な選択肢となります。
AWS 深層学習コンテナイメージを選択する
AWS 深層学習コンテナ
このデプロイでは、vLLM 0.9 用の AWS DLC を使用します。これには、NVIDIA ライブラリと、AWS GPU インスタンスでのトランスフォーマーモデル推論に特化して調整され、最適化された GPU パフォーマンス設定が含まれます。
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2
vLLM Kubernetes マニフェストを適用する
EKS に vLLM をデプロイする方法は複数あります。このガイドでは、Kubernetes ネイティブであり、開始しやすい方法である、Kubernetes デプロイを使用した vLLM デプロイについて説明します。高度なデプロイオプションについては、vLLM ドキュメント
Kubernetes マニフェストを使用してデプロイパラメータを定義し、リソースの割り当て、ノードの配置、ヘルスプローブ、サービスの公開などを制御します。vLLM の AWS 深層学習コンテナイメージを使用して GPU 対応ポッドを実行するようにデプロイを設定します。LLM 推論に最適化されたパラメータを設定し、AWS Load Balancer サービスを介して vLLM の OpenAPI 互換エンドポイントを公開します。
cat <<EOF | envsubst | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker containers: - name: vllm-inference image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2 ports: - containerPort: 8000 env: - name: MODEL_PATH value: "/mnt/models/llama-3.1-8b-instruct" args: - "--model=/mnt/models/llama-3.1-8b-instruct" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" readinessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 resources: limits: nvidia.com/gpu: 1 requests: memory: "24Gi" cpu: "4" ephemeral-storage: "25Gi" # Ensure enough node storage for vLLM container image volumeMounts: - name: models mountPath: /mnt/models readOnly: true volumes: - name: models persistentVolumeClaim: claimName: model-store --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: type: LoadBalancer ports: - port: 80 targetPort: 8000 protocol: TCP selector: app: vllm-inference-app EOF
vLLM ポッドが Ready 1/1 状態であることを確認します。
kubectl get pod -l app=vllm-inference-app -w
正常な出力:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
コンテナイメージがプルされ、vLLM がモデルファイルを GPU メモリにロードするまでに数分かかる場合があります。ポッドが準備完了で使用可能である場合にのみ続行します。
サービスを公開する
Kubernetes のポート転送を使用して、ローカル開発およびテスト向けに推論エンドポイントをローカルで公開します。このコマンドは、別のターミナルウィンドウで実行したままにしておきます。
export POD_NAME=$(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') kubectl port-forward pod/$POD_NAME 8000:8000
AWS Load Balancer Controller は、vLLM サービスエンドポイントを外部に公開する Network Load Balancer を自動的に作成します。以下を実行して NLB エンドポイントを取得します。
NLB=$(kubectl get service vllm-inference-svc -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
AWS Load Balancer Controller をインストールする必要がある場合は、「AWS Load Balancer Controller を使用してインターネットトラフィックをルーティングする」に記載されているデプロイのステップに従います。
推論の実行
推論ポッドを検証する
転送されたポートを使用して、推論コンテナの機能をローカルで検証します。接続リクエストを送信し、レスポンスに HTTP コード 200 が含まれていることを確認します。
$ curl -IX GET "http://localhost:8000/v1/models"
HTTP/1.1 200 OK date: Mon, 13 Oct 2025 23:24:57 GMT server: uvicorn content-length: 516 content-type: application/json
NLB エンドポイント経由で LLM に完了リクエストを送信して、推論機能をテストし、外部接続を検証します。
curl -X POST "http://$NLB:80/v1/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/models/llama-3.1-8b-instruct", "prompt": "Explain artificial intelligence:", "max_tokens": 512, "temperature": 0.7 }'
このエンドポイントは OpenAI API 形式に従っており、既存のアプリケーションと互換性を保ちながら、応答長や温度など、出力の多様性を制御するための生成パラメータを設定できます。
チャットボットアプリを実行する
このガイドでは、デモンストレーションとして、プロジェクト nextjs-vllm-ui
ポート 3000 を localhost にマッピングし、vLLM NLB エンドポイントに接続する Docker コンテナとして、チャットボット UI を実行します。
docker run --rm \ -p 3000:3000 \ -e VLLM_URL="http://${NLB}:80" \ --name nextjs-vllm-ui-demo \ ghcr.io/yoziru/nextjs-vllm-ui:latest
ウェブブラウザを開き、http://localhost:3000/ に移動します。
Llama モデルを操作できるチャットインターフェイスが表示されます。
チャット UI インターフェイス

推論パフォーマンスを最適化する
vLLM などの特化型推論エンジンは、継続的なバッチ処理、効率的な KV キャッシュ、最適化されたメモリ注意メカニズムなど、推論パフォーマンスを大幅に向上させる高度な機能を提供します。vLLM 設定パラメータを調整することで、特定のユースケース要件とワークロードパターンを満たしながら、推論パフォーマンスを向上させることができます。GPU の飽和を達成するには適切な設定が不可欠です。これにより、高スループット、低レイテンシー、費用対効果の高いオペレーションを実現しながら、高価な GPU リソースを最大限に活用できます。以下の最適化は、EKS での vLLM デプロイのパフォーマンスを最大化するのに役立ちます。
vLLM 設定をベンチマークする
ユースケースに合わせて vLLM の設定パラメータを調整するために、GuideLLM
vLLM 設定のベースラインを確立する
これは、vLLM の実行に使用されたベースライン設定です。
| vLLM パラメータ | 説明 |
|---|---|
|
tensor_parallel_size: 1 |
モデルを 1 GPU に分散します。 |
|
gpu_memory_utilization: 0.90 |
システムオーバーヘッド用として GPU メモリの 10% を予約します。 |
|
max_sequence_length: 8192 |
最大合計シーケンス長 (入力 + 出力) |
|
max_num_seqs: 1 |
GPU あたりの最大同時リクエスト数 (バッチ処理) |
このベースライン設定で GuideLLM を実行して、パフォーマンのスベースラインを確立します。このテストでは、GuideLLM は 1 秒あたり 1 リクエストを生成し、256 トークンのリクエストと 128 トークンのレスポンスを使用するように設定されています。
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
正常な出力:
ベースラインベンチマークの結果

調整された vLLM 設定
GPU リソースと並列化をより有効に活用するために、vLLM パラメータを調整します。
| vLLM パラメータ | 説明 |
|---|---|
|
tensor_parallel_size: 1 |
GPU は 1 基のままとします。テンソル並列化は、vLLM が使用する GPU 数と一致している必要があります。 |
|
gpu_memory_utilization: 0.92 |
可能な場合はオーバーヘッド用の GPU メモリを削減します。ただし、vLLM がエラーなく引き続き実行されることを確認します。 |
|
max_sequence_length: 4096 |
ユースケースの要件に応じて最大シーケンスを調整します。最大シーケンス長を小さくすると、並列化の増加に使用できるリソースが解放されます。 |
|
max_num_seqs: 8 |
最大シーケンス長を増やすとスループットは向上しますが、レイテンシーも増加します。スループットを最大化しつつ、レイテンシーがユースケースの要件内に収まるように、この値を増加させます。 |
kubectl パッチコマンドを使用して、実行中のデプロイにこれらの変更を適用します。
kubectl patch deployment vllm-inference-app --type='json' -p='[ {"op": "replace", "path": "/spec/template/spec/containers/0/args/4", "value": "--gpu-memory-utilization=0.92"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/5", "value": "--max-model-len=4096"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/6", "value": "--max-num-seqs=8"} ]'
vLLM ポッドが Ready 1/1 状態であることを確認します。
kubectl get pod -l app=vllm-inference-app -w
正常な出力:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
次に、以前と同じベンチマーク値を使用して GuideLLM を再度実行します。
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
正常な出力:
最適化ベンチマークの結果
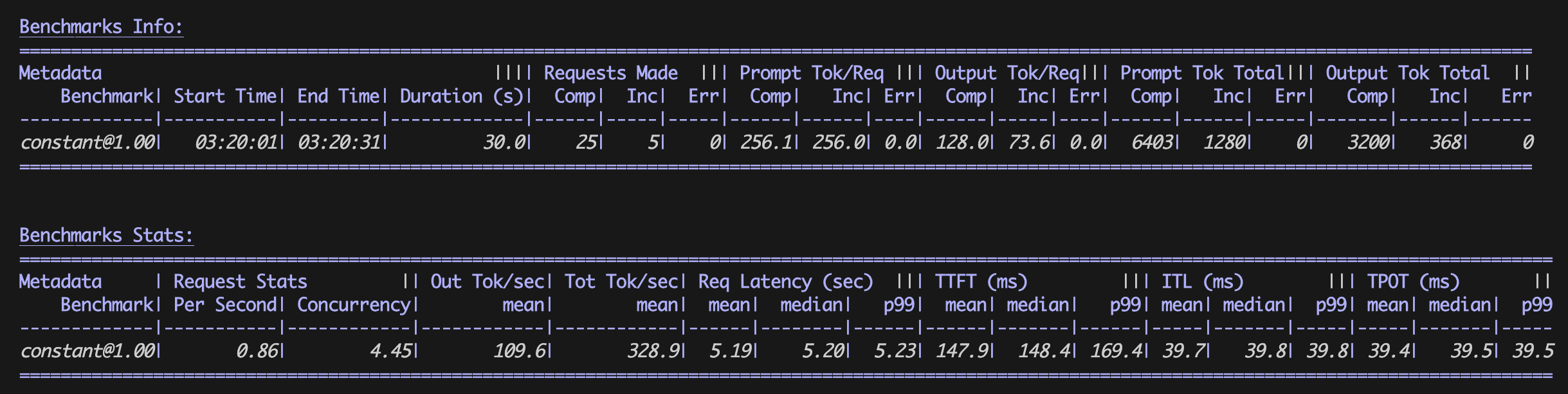
ベンチマーク結果
ベースラインの vLLM 設定と最適化された vLLM 設定の両方について、表形式でベンチマーク結果が算出されます。
| 平均値 | ベースライン設定 | 最適化設定 |
|---|---|---|
|
RPS |
0.23 リクエスト/秒 |
0.86 リクエスト/秒 |
|
E2E |
12.99 s |
5.19 s |
|
TTFT |
8637.2 ms |
147.9 ms |
|
TPOT |
34.0 ms |
39.5 ms |
最適化された vLLM 設定により、推論スループット (RPS) が大幅に向上し、レイテンシー (E2E、TTFT) が低減しました。一方で、出力トークンあたりの時間 (TPOT) はわずかに数ミリ秒増加しました。これらの結果は、vLLM が推論パフォーマンスを大幅に改善する仕組み、すなわち各コンテナがより短時間でより多くのリクエストを処理できるようになることで、コスト効率の高いオペレーションを実現できることを示しています。
