翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ノードとワークロードの効率
ワークロードとノードを効率的に使用すると、パフォーマンスとスケールを向上させながら、複雑さとコストを削減できます。この効率を計画するときは多くの要素を考慮する必要があり、トレードオフと各機能に対する 1 つのベストプラクティス設定の観点から考えるのが最も簡単です。これらのトレードオフについては、次のセクションで詳しく見てみましょう。
ノードの選択
ノードサイズをわずかに大きく (4~12xlarge) 使用すると、システムコンポーネントの DaemonSets
注記
k8s は一般的なルールとして水平方向にスケールするため、ほとんどのアプリケーションでは NUMA サイズノードのパフォーマンスへの影響を考慮することは意味がないため、そのノードサイズを下回る範囲を推奨します。
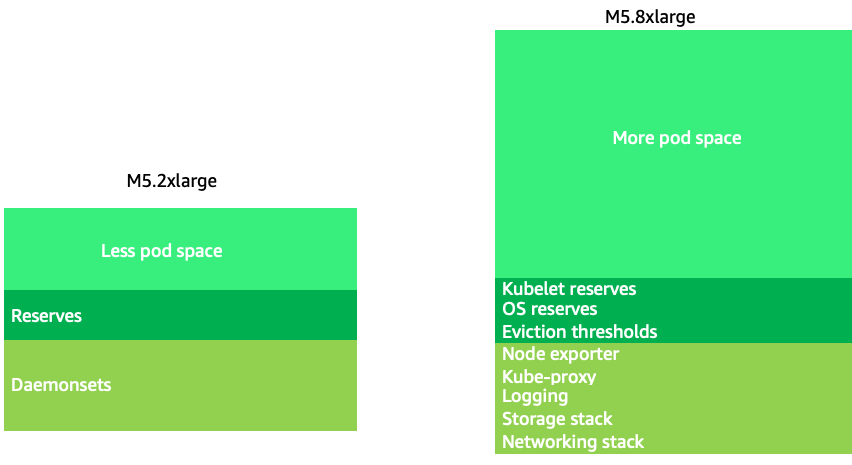
ノードサイズが大きいと、ノードあたりの使用可能なスペースの割合が高くなります。ただし、このモデルを極端に処理するには、ノードを非常に多くのポッドでパッキングし、エラーが発生したり、ノードを飽和させたりします。ノード飽和度のモニタリングは、より大きなノードサイズを正常に使用する上で重要です。
ノードの選択がone-size-fits-all提案になることはほとんどありません。多くの場合、解約率が劇的に異なるワークロードを異なるノードグループに分割するのが最善です。チャーンレートが高い小規模なバッチワークロードは 4xlarge ファミリーのインスタンスが最適です。一方、8 vCPU を使用し、チャーンレートが低い Kafka などの大規模なアプリケーションは 12xlarge ファミリーが最適です。

注記
非常に大きなノードサイズで考慮すべきもう 1 つの要因は、CGROUPS がコンテナ化されたアプリケーションから vCPU の総数を非表示にしないことです。動的ランタイムでは、意図しない数の OS スレッドが発生し、トラブルシューティングが困難なレイテンシーが発生することがよくあります。これらのアプリケーションでは、CPU ピン留め
ノードビンのパッキング
Kubernetes ルールと Linux ルール
Kubernetes でワークロードを処理するときに注意する必要があるルールは 2 つあります。Kubernetes スケジューラのルール。リクエスト値を使用してノードでポッドをスケジュールし、ポッドがスケジュールされた後に何が起こるかを示します。これは Kubernetes ではなく Linux の領域です。
Kubernetes スケジューラが完了すると、新しいルールセットが Linux Completely Fair Scheduler (CFS) を引き継ぎます。重要な点は、Linux CFS にはコアの概念がないということです。コアでの思考が、スケールに合わせてワークロードを最適化する際の大きな問題につながる理由について説明します。
コアでの思考
Kubernetes スケジューラにはコアの概念があるため、混乱が始まります。Kubernetes スケジューラの観点から見ると、それぞれが 1 つのコアセットのリクエストを持つ 4 つの NGINX ポッドを持つノードを見ると、ノードは次のようになります。

ただし、Linux CFS の観点から、これがどの程度異なるかについて考えてみましょう。Linux CFS システムを使用する際に覚えておくべき最も重要なことは、共有システムにカウントされるコンテナはビジーコンテナ (CGROUPS) のみです。この場合、最初のコンテナのみがビジー状態であるため、ノード上の 4 つのコアすべてを使用できます。

なぜこれが重要なのですか? NGINX アプリケーションがそのノードで唯一のビジーコンテナであった開発クラスターでパフォーマンステストを実行したとします。アプリケーションを本番環境に移行すると、NGINX アプリケーションは 4 つの vCPU のリソースを必要としますが、ノード上の他のすべてのポッドがビジー状態であるため、アプリケーションのパフォーマンスは制限されます。

このような状況では、アプリケーションが「スイートスポット」にスケールできないため、不必要にコンテナを追加することになります。の重要な概念"sweet spot"をもう少し詳しく見てみましょう。
アプリケーションの適切なサイジング
各アプリケーションには、トラフィックを取ることができない特定のポイントがあります。このポイントを超えると、処理時間が長くなり、このポイントを大幅に超えてプッシュするとトラフィックがドロップされる可能性があります。これは、アプリケーションの飽和ポイントと呼ばれます。スケーリングの問題を回避するには、飽和ポイントに達する前にアプリケーションのスケーリングを試みる必要があります。これをスイートスポットと呼びましょう。

各アプリケーションをテストして、そのスイートスポットを理解する必要があります。アプリケーションごとに異なるため、ここでは一般的なガイダンスはありません。このテストでは、アプリケーションの飽和ポイントを示す最適なメトリクスを理解しようとしています。多くの場合、使用率メトリクスはアプリケーションが飽和していることを示すために使用されますが、これはすぐにスケーリングの問題につながる可能性があります (このトピックについては、後のセクションで詳しく説明します)。この「スイートスポット」を取得したら、これを使用してワークロードを効率的にスケーリングできます。
逆に、スイートスポットのかなり前にスケールアップして不要なポッドを作成した場合はどうなりますか? これについては、次のセクションで説明します。
ポッドスプロール
不要なポッドをすばやく作成する方法を確認するには、左側の最初の例を見てみましょう。このコンテナの正しい垂直スケールは、1 秒あたり 100 件のリクエストを処理するときに、約 2 つの vCPUs の使用率を占めます。ただし、リクエストを半分のコアに設定してリクエスト値をプロビジョニング不足にした場合、実際に必要な 1 つのポッドごとに 4 つのポッドが必要になります。この問題をさらに悪化させると、HPA

この問題を拡大すると、この問題がどのように機能しなくなるかをすばやく確認できます。スウィートスポットが正しく設定されていない 10 個のポッドをデプロイすると、80 個のポッドと、それらを実行するために必要な追加のインフラストラクチャにすばやくスパイラルされる可能性があります。

アプリケーションがスウィートスポットで動作できないことによる影響を理解したところで、ノードレベルに戻り、Kubernetes スケジューラと Linux CFS の違いがなぜそれほど重要なのかを尋ねてみましょう。
HPA でスケールアップまたはスケールダウンする場合、より多くのポッドを割り当てるのに十分なスペースがあるシナリオが考えられます。左に示されているノードはすでに 100% の CPU 使用率であるため、これは不適切な決定です。非現実的ではあるが理論的に可能なシナリオでは、ノードが完全に満杯であっても CPU 使用率がゼロであるという極端なシナリオが発生する可能性があります。

リクエストの設定
そのアプリケーションの「スイートスポット」値にリクエストを設定しようとしますが、次の図に示すように非効率になります。ここでは、リクエスト値を 2 vCPU に設定していますが、これらのポッドの平均使用率はほとんどの場合 1 CPU しか実行されません。この設定により、CPU サイクルの 50% が無駄になるため、許容できません。

これにより、問題に対する複雑な回答が得られます。コンテナ使用率はバキュームでは考慮できません。ノードで実行されている他のアプリケーションを考慮する必要があります。次の例では、本質的にバースト性のコンテナは、メモリが制限されている可能性のある 2 つの CPU 使用率の低いコンテナと で混合されます。このようにして、コンテナがノードに課税することなくスイートスポットに到達できるようにします。

これらすべてから取り除く重要な概念は、Kubernetes スケジューラのコアの概念を使用して Linux コンテナのパフォーマンスを理解することで、関連性のない意思決定が下りる可能性があることです。
注記
Linux CFS には強力なポイントがあります。これは特に I/O ベースのワークロードに当てはまります。ただし、アプリケーションがサイドカーなしでフルコアを使用し、I/O 要件がない場合、CPU ピン留めはこのプロセスからかなりの複雑さを取り除く可能性があるため、これらの注意点をお勧めします。
使用率と飽和度
アプリケーションスケーリングでよくある間違いは、スケーリングメトリクスに CPU 使用率のみを使用することです。複雑なアプリケーションでは、これはほとんどの場合、アプリケーションが実際にリクエストで飽和していることを示す不適切な指標です。左側の例では、すべてのリクエストが実際にウェブサーバーにヒットしているため、CPU 使用率は飽和とともに適切に追跡されています。
実際のアプリケーションでは、これらのリクエストの一部がデータベースレイヤーや認証レイヤーなどによって処理される可能性があります。このより一般的なケースでは、リクエストが他のエンティティによって処理されているため、CPU が飽和状態で追跡されていないことに注意してください。この場合、CPU は飽和度を示す非常に低い指標です。

アプリケーションのパフォーマンスに間違ったメトリクスを使用することが、Kubernetes での不要で予測不可能なスケーリングの最大の理由です。使用しているアプリケーションの種類に適した飽和メトリクスを選択するには、細心の注意が必要です。指定できるすべてのレコメンデーションに適合するサイズは 1 つではないことに注意してください。使用する言語と問題のアプリケーションの種類に応じて、飽和度に関するさまざまなメトリクスのセットがあります。
この問題は CPU 使用率でのみ発生する可能性がありますが、1 秒あたりのリクエスト数などの他の一般的なメトリクスも、上記で説明したのとまったく同じ問題になる可能性があります。リクエストは DB レイヤー、認証レイヤーにも送信され、ウェブサーバーによって直接サービスされないため、ウェブサーバー自体の真の飽和度のメトリクスとしては不十分なことに注意してください。

残念ながら、適切な飽和メトリクスを選択する場合、簡単な回答はありません。考慮すべきガイドラインをいくつか示します。
-
言語ランタイムを理解する - 複数の OS スレッドを持つ言語は、シングルスレッドアプリケーションと反応が異なるため、ノードへの影響は異なります。
-
正しい垂直スケールを理解します。新しいポッドをスケーリングする前に、アプリケーションの垂直スケールにどのくらいのバッファが必要ですか?
-
アプリケーションの飽和度を真に反映するメトリクス - Kafka プロデューサーの飽和メトリクスは、複雑なウェブアプリケーションとは大きく異なります。
-
ノード上の他のすべてのアプリケーションが相互にどのような影響を与えるか - アプリケーションのパフォーマンスは、ノード上の他のワークロードが大きな影響を与えるバキュームでは行われません。
このセクションを終了するには、上記を過度に複雑で不要なものとして却下するのが簡単です。多くの場合、問題が発生していますが、間違ったメトリクスを調べているため、問題の本質に気付いていません。次のセクションでは、それがどのように行われるかを見ていきます。
ノードの飽和度
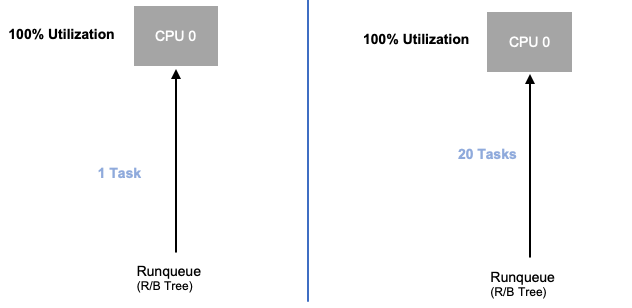
アプリケーションの飽和度を調べたので、ノードの観点からこの同じ概念を見てみましょう。使用率と飽和度の違いを確認するために 100% が使用されている 2 つの CPUs を考えてみます。
左側の vCPU は 100% 使用されていますが、この vCPU で実行するのを待っているタスクは他にないため、純粋に理論的な意味では、これは非常に効率的です。一方、2 番目の例では、vCPU によって処理されるのを待っているシングルスレッドアプリケーションが 20 個あります。20 個のアプリケーションすべてが、vCPU によって処理されるターンを待っている間に、何らかのレイテンシーが発生するようになりました。つまり、右側の vCPU は飽和状態です。
使用率だけを見ると、この問題は発生しませんが、このレイテンシーはネットワークなど無関係なものが原因である可能性があり、誤った道をたどる可能性があります。
ノードで実行されているポッドの総数をいつでも増やすときは、使用率メトリクスだけでなく、飽和メトリクスを表示することが重要です。これは、ノードが過剰飽和しているという事実を簡単に見逃す可能性があるためです。このタスクでは、次のグラフに示すように、プレッシャーストール情報メトリクスを使用できます。
PromQL - I/O の停止
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))

注記
圧力ストールメトリクスの詳細については、https://facebookmicrosites.github.io/psi/docs/overview* を参照してください。
これらのメトリクスを使用すると、スレッドが CPU を待っているかどうか、またはボックスのすべてのスレッドがメモリや I/O などのリソースを待っているときに停止しているかどうかを確認できます。 例えば、1 分間にインスタンス上のすべてのスレッドが I/O を待つのが停止した割合を確認できます。
topk(3, ((irate(node_pressure_io_stalled_seconds_total[1m])) * 100))
このメトリクスを使用すると、上記のグラフでボックス上のすべてのスレッドがハイウォーターマークで I/O を待っている時間の 45% 停止していたことがわかります。つまり、その 1 分間にこれらの CPU サイクルをすべて破棄していました。これが起こっていることを理解することで、vCPU のかなりの時間を再利用できるため、スケーリングがより効率的になります。
HPA V2
HPA API の Auto Scaling/v2 バージョンを使用することをお勧めします。HPA API の古いバージョンでは、特定のエッジケースでスケーリングが停止する可能性があります。また、各スケーリングステップ中にポッドが 2 倍になるだけでした。これにより、迅速なスケーリングが必要な小規模なデプロイに問題が発生しました。
Auto Scaling/v2 を使用すると、スケールオンする複数の基準を含める柔軟性が向上し、カスタムメトリクスと外部メトリクス (K8s 以外のメトリクス) を使用する際に非常に柔軟性があります。
例として、3 つの値のうち最も高い値でスケーリングできます (以下を参照)。すべてのポッドの平均使用率が 50% を超える場合、カスタムメトリクスの Ingress の 1 秒あたりのパケット数が平均 1,000 を超える場合、または Ingress オブジェクトが 1 秒あたりのリクエスト数が 10K000 を超える場合にスケーリングされます。
注記
これは、Auto Scaling API の柔軟性を示すためだけに、本番環境でのトラブルシューティングが困難な、過度に複雑なルールには反対することをお勧めします。
apiVersion: autoscaling/v2 kind: HorizontalPodAutoscaler metadata: name: php-apache spec: scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: php-apache minReplicas: 1 maxReplicas: 10 metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 50 - type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k - type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io/v1 kind: Ingress name: main-route target: type: Value value: 10k
ただし、このようなメトリクスを複雑なウェブアプリケーションに使用する危険性について学びました。この場合、アプリケーションの飽和度と使用率を正確に反映したカスタムメトリクスまたは外部メトリクスを使用することで、より適切に対応できます。HPAv2 では、任意のメトリクスに従ってスケーリングできますが、そのメトリクスを見つけて Kubernetes にエクスポートして使用する必要があります。
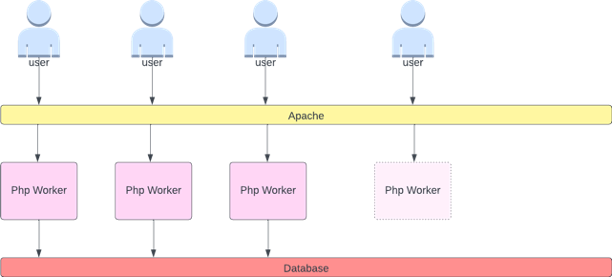
例えば、Apache でアクティブなスレッドキュー数を確認できます。これにより、「スムーズ」なスケーリングプロファイルが作成されることがよくあります (近い将来、さらに詳しく説明します)。スレッドがアクティブな場合、そのスレッドがデータベースレイヤーを待っているか、リクエストをローカルで処理しているかは関係ありません。すべてのアプリケーションスレッドが使用されている場合は、アプリケーションが飽和していることがわかります。
このスレッドの枯渇をシグナルとして使用して、完全に利用可能なスレッドプールを持つ新しいポッドを作成できます。これにより、トラフィックが多い時間帯にアプリケーションが吸収するバッファの大きさも制御できます。たとえば、スレッドプールの合計が 10 の場合、4 つのスレッドを使用したスケーリングと 8 つのスレッドを使用したスケーリングは、アプリケーションのスケーリング時に使用できるバッファに大きな影響を与えます。4 の設定は、負荷の高い状況で迅速にスケーリングする必要があるアプリケーションにとって理にかなっています。この場合、リクエストの数が時間の経過とともに急激に増加するのに対して、スケーリングに十分な時間があれば、リソースに対して 8 の設定の方が効率的です。
スケーリングとは、「スムーズ」という意味ですか? CPU をメトリクスとして使用している次のグラフに注意してください。このデプロイのポッドは、すぐに再びスケールダウンするために、50 個のポッドから最大 250 個のポッドまで短時間でスパイクします。これは非常に非効率的なスケーリングであり、クラスターのチャーンの主な原因です。

アプリケーションの正しいスウィートスポット (グラフの中間) を反映するメトリクスに変更した後、どのようにスムーズにスケールできるかに注目してください。スケーリングが効率的になり、ポッドはリクエスト設定を調整することで指定したヘッドルームに合わせて完全にスケーリングできるようになりました。現在、ポッドの小規模なグループは、数百のポッドが以前に実行していた作業を行っています。実世界のデータは、これが Kubernetes クラスターのスケーラビリティの最も重要な要素であることを示しています。

重要な点は、CPU 使用率はアプリケーションとノードの両方のパフォーマンスの 1 つのディメンションにすぎないことです。ノードとアプリケーションの唯一のヘルス指標として CPU 使用率を使用すると、スケーリング、パフォーマンス、コストに問題が生じます。これらはすべて密接にリンクされた概念です。アプリケーションとノードのパフォーマンスが高いほど、スケーリングの必要が少なくなり、コストが削減されます。
特定のアプリケーションのスケーリングに正しい飽和メトリクスを見つけて使用すると、そのアプリケーションの真のボトルネックをモニタリングしてアラームを設定することもできます。この重要なステップをスキップすると、不可能ではないにしても、パフォーマンスの問題のレポートを理解するのは困難になります。
CPU 制限の設定
誤解されたトピックについてこのセクションをまとめるために、CPU 制限について説明します。つまり、制限は、100 ミリ秒ごとにリセットされるカウンターを持つコンテナに関連付けられたメタデータです。これにより、Linux は 100 ミリ秒の期間に特定のコンテナによってノード全体で使用されている CPU リソースの数を追跡できます。
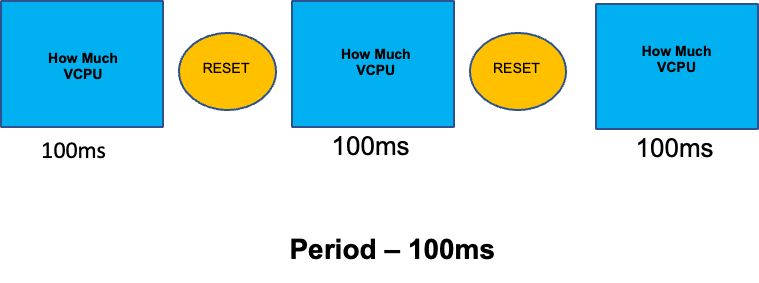
制限の設定に関する一般的なエラーは、アプリケーションがシングルスレッドであり、そのアプリケーションで「」割り当てられた「」vCPU でのみ実行されていると仮定することです。上のセクションでは、CFS がコアを割り当てず、実際には大きなスレッドプールを実行しているコンテナがボックス上の使用可能なすべての vCPU でスケジュールされることを学習しました。
64 個の OS スレッドが 64 個の使用可能なコアで実行されている場合 (Linux ノードの観点から見ると)、これら 64 個のコアすべてで実行されている時間が追加された後、100 ミリ秒の期間の合計使用 CPU 時間料金が発生します。これはガベージコレクションプロセス中にのみ発生する可能性があるため、このようなことを見逃すのは非常に簡単です。そのため、制限を設定する前に、メトリクスを使用して、時間の経過とともに正しい使用量を確保する必要があります。
幸い、アプリケーション内のすべてのスレッドで使用されている vCPU の量を正確に確認する方法があります。container_cpu_usage_seconds_total この目的のために メトリクスを使用します。
スロットリングロジックは 100 ミリ秒ごとに発生し、このメトリクスは 1 秒あたりのメトリクスであるため、この 100 ミリ秒の期間に一致するように PromQL を使用します。この PromQL ステートメントの仕組みについて詳しく知りたい場合は、次のブログ
PromQL クエリ:
topk(3, max by (pod, container)(rate(container_cpu_usage_seconds_total{image!="", instance="$instance"}[$__rate_interval]))) / 10

適切な値があるとわかったら、制限を本稼働環境に置くことができます。その後、予期しない理由でアプリケーションがスロットリングされているかどうかを確認する必要があります。これを行うには、 container_cpu_throttled_seconds_total
topk(3, max by (pod, container)(rate(container_cpu_cfs_throttled_seconds_total{image!=``""``, instance=``"$instance"``}[$__rate_interval]))) / 10

メモリ
メモリ割り当ては、Linux CGroup 動作の Kubernetes スケジューリング動作を混乱させやすい別の例です。これは、CGroup v2 が Linux と Kubernetes でメモリを処理する方法に大きな変更があったため、より微妙なトピックです。詳細については、このブログ
CPU リクエストとは異なり、スケジューリングプロセスが完了すると、メモリリクエストは使用されません。これは、CPU と同じ方法で CGroup v1 のメモリを圧縮できないためです。これにより、メモリ制限だけで済みます。メモリ制限は、ポッドを完全に終了することでメモリリークのフェイルセーフとして機能するように設計されています。これはオールスタイルまたはノースタイルの提案ですが、この問題に対処する新しい方法が提供されました。
まず、コンテナに適切な量のメモリを設定することは、表示されるとおり簡単なことではないことを理解することが重要です。Linux のファイルシステムは、パフォーマンスを向上させるためにメモリをキャッシュとして使用します。このキャッシュは時間の経過とともに増加し、キャッシュに必要なメモリ量を知るのは難しい場合がありますが、アプリケーションのパフォーマンスに大きな影響を与えることなく再利用できます。これにより、多くの場合、メモリ使用量が誤って解釈されます。
メモリを「圧縮」する機能は、CGroup v2 の背後にある主要なドライバーの 1 つです。CGroup V2 が必要だった理由の詳細については、LISA21 での Chris Down のプレゼンテーション
幸い、Kubernetes は memory.highの下に memory.minおよび の概念を持つようになりましたrequests.memory。これにより、このキャッシュされたメモリを積極的に解放して、他のコンテナを使用できるようになります。コンテナがメモリの上限に達すると、カーネルはコンテナのメモリを に設定された値まで積極的に再利用できますmemory.min。したがって、ノードがメモリ負荷にさらされるときの柔軟性が向上します。
重要な質問は になり、どの値を memory.minに設定しますか? これは、メモリプレッシャーのストールメトリクスが関係する場所です。これらのメトリクスを使用して、コンテナレベルでメモリの「スラッシュ」を検出できます。その後、fbtaxmemory.minして の正しい値を検出し、memory.min値をこの設定に動的に設定できます。
概要
セクションを要約すると、以下の概念を簡単にまとめることができます。
-
使用率と飽和度
-
Kubernetes スケジューラロジックを使用した Linux パフォーマンスルール
これらの概念を分離するには、細心の注意が必要です。パフォーマンスとスケールはディープレベルでリンクされます。不要なスケーリングによりパフォーマンスの問題が発生し、スケーリングの問題が発生します。
