翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ネットワーク切断による Kubernetes ポッドのフェイルオーバー
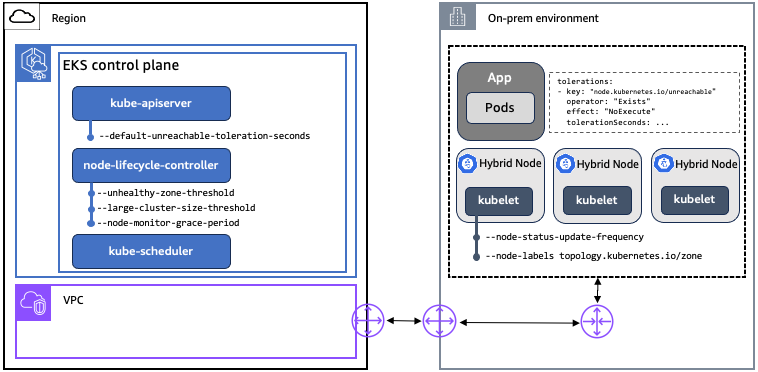
まず、ノードと Kubernetes コントロールプレーン間のネットワーク切断時の Kubernetes の動作に影響する主要な概念、コンポーネント、設定を確認します。EKS はアップストリーム Kubernetes に準拠しているため、ここで説明するすべての Kubernetes の概念、コンポーネント、設定は、EKS および EKS Hybrid Nodes のデプロイに適用されます。
ネットワーク切断中のポッドフェイルオーバー動作を改善するために、特に EKS が改善されました。詳細については、アップストリーム Kubernetes リポジトリのGitHub の問題 #131294
概念
テイントと許容範囲: テイントと許容範囲は、ノードへのポッドのスケジュールを制御するために Kubernetes で使用されます。テイントは node-lifecycle-controller によって設定され、ノードがスケジューリングの対象ではないか、それらのノードのポッドを削除する必要があることを示します。ネットワーク切断が原因でノードに到達できない場合、node-lifecycle-controller は NoSchedule 効果で node.kubernetes.io/unreachable テイントを適用し、特定の条件が満たされた場合は NoExecute 効果を適用します。node.kubernetes.io/unreachable テイントは、NodeCondition Ready が不明であることに対応します。ユーザーは、PodSpec のアプリケーションレベルでテイントの許容範囲を指定できます。
-
NoSchedule: 許容値が一致しない限り、テイントされたノードに新しいポッドはスケジュールされません。ノードで既に実行されているポッドは削除されません。
-
NoExecute: テイントを許容しないポッドはすぐに削除されます。(tolerationSeconds を指定せずに) テイントを許容するポッドは、永久にバインドされます。tolerationSeconds が指定されたテイントを許容するポッドは、指定された時間バインドされたままになります。その時間が経過すると、ノードライフサイクルコントローラーはノードからポッドを削除します。
ノードリース: Kubernetes は、リース API を使用して kubelet ノードハートビートを Kubernetes API サーバーに通信します。ノードごとに、一致する名前の Lease オブジェクトがあります。内部的には、各 kubelet ハートビートは Lease オブジェクトの spec.renewTime フィールドを更新します。Kubernetes コントロールプレーンは、このフィールドのタイムスタンプを使用してノードの可用性を判断します。ノードが Kubernetes コントロールプレーンから切断されている場合、リースの spec.renewTime を更新できず、コントロールプレーンはそれを NodeCondition Ready が不明であると解釈します。
コンポーネント
| コンポーネント | サブコンポーネント | 説明 |
|---|---|---|
|
Kubernetes コントロールプレーン |
kube-api-server |
API サーバーは、Kubernetes API を公開する Kubernetes コントロールプレーンのコアコンポーネントです。 |
|
Kubernetes コントロールプレーン |
node-lifecycle-controller |
kube-controller-manager が実行するコントローラーの 1 つ。ノードの問題を検出して対応します。 |
|
Kubernetes コントロールプレーン |
kube-scheduler |
ノードが割り当てられていない新しく作成された Pod を監視し、実行するノードを選択するコントロールプレーンコンポーネント。 |
|
Kubernetes ノード |
kubelet |
クラスター内の各ノードで実行されるエージェント。kubelet は PodSpecs を監視し、それらの PodSpecs で説明されているコンテナが実行中で正常であることを確認します。 |
構成設定
| コンポーネント | 設定 | 説明 | K8s デフォルト | EKS デフォルト | EKS で設定可能 |
|---|---|---|---|---|---|
|
kube-api-server |
default-unreachable-toleration-seconds |
このような許容範囲がまだないすべてのポッドにデフォルトで追加 |
300 |
300 |
いいえ |
|
node-lifecycle-controller |
node-monitor-grace-period |
ノードが異常とマークされるまでに応答しない時間。kubelet の の N 倍にする必要があります。N は |
40 |
40 |
いいえ |
|
node-lifecycle-controller |
large-cluster-size-threshold |
node-lifecycle-controller がクラスターをエビクションロジック用に大規模として扱うノードの数。このサイズ以下のクラスターでは、 |
50 |
100,000 |
いいえ |
|
node-lifecycle-controller |
unhealthy-zone-threshold |
そのゾーンを異常として扱うために準備中である必要があるゾーン内のノードの割合。 |
55% |
55% |
いいえ |
|
kubelet |
node-status-update-frequency |
kubelet がノードステータスをコントロールプレーンに投稿する頻度。node-lifecycle-controller |
10 |
10 |
[Yes (はい)] |
|
kubelet |
ノードラベル |
クラスターにノードを登録するときに追加するラベル。ラベルはハイブリッドノードで指定して、ノードをゾーンにグループ化 |
なし |
なし |
はい |
ネットワーク切断による Kubernetes ポッドのフェイルオーバー
ここで説明する動作は、ポッドがデフォルト設定で Kubernetes デプロイとして実行されており、EKS が Kubernetes プロバイダーとして使用されていることを前提としています。実際の動作は、環境、ネットワーク切断のタイプ、アプリケーション、依存関係、クラスター設定によって異なる場合があります。このガイドのコンテンツは、特定のアプリケーション、クラスター設定、プラグインのサブセットを使用して検証されました。本番環境に移行する前に、独自の環境と独自のアプリケーションで動作をテストすることを強くお勧めします。
ノードと Kubernetes コントロールプレーンの間にネットワーク切断がある場合、切断された各ノードの kubelet は Kubernetes コントロールプレーンと通信できません。したがって、kubelet は接続が復元されるまでそれらのノード上のポッドを削除できません。つまり、ネットワークの切断前にそれらのノードで実行されているポッドは、切断中に引き続き実行され、他の障害が原因でシャットダウンされないと仮定します。つまり、ノードと Kubernetes コントロールプレーン間のネットワーク切断中に静的安定性を実現できますが、接続が復元されるまでノードまたはワークロードで変更オペレーションを実行することはできません。
ネットワーク切断の性質に基づいて異なるポッドフェイルオーバー動作を生成する主なシナリオは 5 つあります。すべてのシナリオで、ノードが Kubernetes コントロールプレーンに再接続されると、クラスターはオペレーターの介入なしで再び正常になります。以下のシナリオでは、観測結果に基づいて期待される結果を概説しますが、これらの結果は、考えられるすべてのアプリケーションおよびクラスター設定に適用されるとは限りません。
シナリオ 1: クラスターの完全な中断
期待される結果: 到達できないノードのポッドは削除されず、それらのノードで実行され続けます。
クラスターの完全な中断とは、クラスター内のすべてのノードが Kubernetes コントロールプレーンから切断されることを意味します。このシナリオでは、コントロールプレーンの node-lifecycle-controller は、クラスター内のすべてのノードに到達できないことを検出し、ポッドの削除をキャンセルします。
クラスター管理者は、切断Not Ready中にステータスが のすべてのノードを表示します。Pod のステータスは変更されず、切断後の再接続中にノードに新しいポッドがスケジュールされることはありません。
シナリオ 2: フルゾーンの中断
期待される結果: 到達できないノードのポッドは削除されず、それらのノードで実行され続けます。
フルゾーン中断とは、ゾーン内のすべてのノードが Kubernetes コントロールプレーンから切断されることを意味します。このシナリオでは、コントロールプレーンの node-lifecycle-controller は、ゾーン内のすべてのノードに到達できないことを検出し、ポッドの削除をキャンセルします。
クラスター管理者は、切断Not Ready中にステータスが のすべてのノードを表示します。Pod のステータスは変更されず、切断後の再接続中にノードに新しいポッドがスケジュールされることはありません。
シナリオ 3: マジョリティゾーンの中断
期待される結果: 到達できないノードのポッドは削除されず、それらのノードで実行され続けます。
マジョリティーゾーンの中断とは、特定のゾーンのほとんどのノードが Kubernetes コントロールプレーンから切断されることを意味します。Kubernetes のゾーンは、同じtopology.kubernetes.io/zoneラベルを持つノードによって定義されます。クラスターにゾーンが定義されていない場合、大部分の中断は、クラスター全体のノードの大部分が切断されることを意味します。デフォルトでは、過半数は node-lifecycle-controller の によって定義されunhealthy-zone-threshold、Kubernetes と EKS の両方で 55% に設定されます。EKS では large-cluster-size-thresholdが 100,000 に設定されているため、ゾーン内のノードの 55% 以上に到達できない場合、ポッドの削除はキャンセルされます (ほとんどのクラスターが 100,000 ノードよりはるかに小さい場合)。
クラスター管理者は、切断Not Ready中にゾーン内のほとんどのノードのステータスが になりますが、ポッドのステータスは変更されず、他のノードでも再スケジュールされません。
上記の動作は、3 ノードを超えるクラスターにのみ適用されます。3 つ以下のノードのクラスターでは、到達できないノード上のポッドは削除がスケジュールされ、新しいポッドは正常なノードでスケジュールされます。
テスト中に、ゾーンのノードの大部分に到達できない場合でも、ネットワーク切断中にポッドが 1 つの到達不可能なノードから完全に削除されたことが確認されることがあります。この動作の原因として、Kubernetes node-lifecycle-controller で考えられる競合状態をまだ調査中です。
シナリオ 4: マイノリティゾーンの中断
期待される結果: ポッドは到達不可能なノードから削除され、新しいポッドは利用可能な適格なノードでスケジュールされます。
少数中断とは、ゾーン内のノードのごく一部が Kubernetes コントロールプレーンから切断されることを意味します。クラスターにゾーンが定義されていない場合、少数中断とは、クラスター全体のノードの少数が切断されることを意味します。前述のように、少数は、デフォルトで 55% の node-lifecycle-controller unhealthy-zone-thresholdの設定によって定義されます。このシナリオでは、ネットワークの切断が default-unreachable-toleration-seconds (5 分) および node-monitor-grace-period (40 秒) より長く、ゾーン内のノードの 55% 未満に到達できない場合、新しいポッドは正常なノードでスケジュールされ、到達できないノードのポッドは削除対象としてマークされます。
クラスター管理者は正常なノードで作成された新しいポッドを表示し、切断されたノードのポッドは として表示されますTerminating。切断されたノードのポッドTerminatingのステータスは ですが、ノードが Kubernetes コントロールプレーンに再接続されるまで完全には削除されないことに注意してください。
シナリオ 5: ネットワーク中断中のノードの再起動
期待される結果: 到達不可能なノードのポッドは、ノードが Kubernetes コントロールプレーンに再接続されるまで開始されません。ポッドフェイルオーバーは、到達できないノードの数に応じて、シナリオ 1~3 で説明されているロジックに従います。
ネットワーク中断中のノードの再起動は、ネットワーク切断と同時にノードで別の障害 (電源サイクル、out-of-memoryイベント、その他の問題など) が発生したことを意味します。ネットワーク切断の開始時にそのノードで実行されていたポッドは、kubelet も再起動した場合、切断中に自動的に再起動されません。kubelet は、起動時に Kubernetes API サーバーにクエリを実行して、実行するポッドを確認します。kubelet がネットワークの切断により API サーバーに到達できない場合、ポッドの起動に必要な情報を取得できません。
このシナリオでは、CLI crictl などのローカルトラブルシューティングツールを使用して、ポッドを「ブレークグラス」メジャーとして手動で起動することはできません。Kubernetes は通常、失敗したポッドを削除し、既存のポッドを再起動するのではなく、新しいポッドを作成します (詳細については、containerd GitHub リポジトリの #10213
