翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Cluster Autoscaler
ヒント
Amazon EKS https://aws-experience.com/emea/smb/events/series/get-hands-on-with-amazon-eks?trk=4a9b4147-2490-4c63-bc9f-f8a84b122c8c&sc_channel=el
概要
Kubernetes Cluster Autoscaler .DesiredReplicasフィールドを制御します。
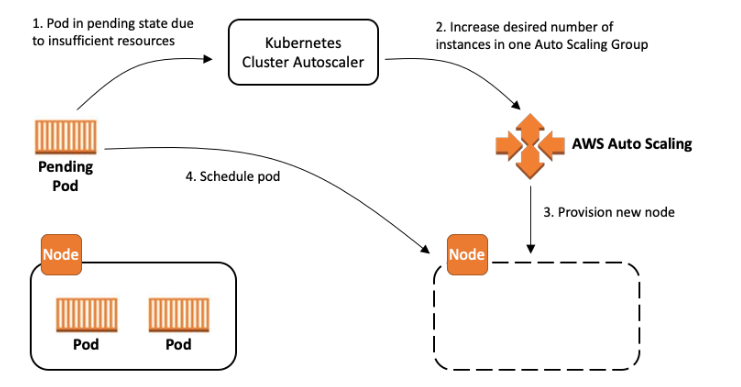
このガイドでは、Cluster Autoscaler を設定し、組織の要件を満たす最適なトレードオフのセットを選択するためのメンタルモデルを提供します。最適な設定は 1 つではありませんが、パフォーマンス、スケーラビリティ、コスト、可用性をトレードオフできる一連の設定オプションがあります。さらに、このガイドでは、AWS の設定を最適化するためのヒントとベストプラクティスを提供します。
用語集
以下の用語は、このドキュメント全体で頻繁に使用されます。これらの用語は幅広い意味を持つことができますが、本書の目的上、以下の定義に限定されます。
スケーラビリティとは、Kubernetes クラスターのポッドとノードの数が増えるにつれて Cluster Autoscaler がどの程度うまく機能するかを指します。スケーラビリティの制限に達すると、Cluster Autoscaler のパフォーマンスと機能が低下します。Cluster Autoscaler がスケーラビリティの制限を超えると、クラスター内のノードを追加または削除できなくなる可能性があります。
パフォーマンスとは、Cluster Autoscaler がスケーリングの決定を行い、実行できる速度を指します。完全にパフォーマンスの高い Cluster Autoscaler はすぐに決定を下し、ポッドがスケジュール不能になるなどの刺激に応じてスケーリングアクションをトリガーします。
可用性とは、ポッドを迅速かつ中断することなくスケジュールできることを意味します。これには、新しく作成されたポッドをスケジュールする必要がある場合や、スケールダウンされたノードがスケジュールされた残りのポッドを終了する場合が含まれます。
コストは、イベントのスケールアウトとスケールインの背後にある決定によって決まります。既存のノードが十分に活用されていない場合、または受信ポッドに対して大きすぎる新しいノードが追加された場合、リソースは浪費されます。ユースケースによっては、積極的なスケールダウン決定により、ポッドの早期終了に関連するコストが発生する可能性があります。
Node Groups は、クラスター内のノードのグループの抽象的な Kubernetes 概念です。これは真の Kubernetes リソースではありませんが、Cluster Autoscaler、Cluster API、およびその他のコンポーネントに抽象化として存在します。ノードグループ内のノードは、ラベルやテイントなどのプロパティを共有しますが、複数のアベイラビリティーゾーンまたはインスタンスタイプで構成される場合があります。
EC2 Auto Scaling Groups は、EC2 でのノードグループの実装として使用できます。EC2 Auto Scaling グループは、Kubernetes クラスターを自動的に結合し、Kubernetes API の対応するノードリソースにラベルとテイントを適用するインスタンスを起動するように設定されています。
EC2 マネージド型ノードグループはEC2 でのノードグループの別の実装です。EC2 Autoscaling Scaling Groups を手動で設定する複雑さを抽象化し、ノードバージョンのアップグレードや正常なノード終了などの追加の管理機能を提供します。
クラスターオートスケーラーの操作
Cluster Autoscaler は、通常、クラスター内のデプロイ
以下を確認してください。
-
Cluster Autoscaler のバージョンがクラスターのバージョンと一致します。クロスバージョン互換性はテストもサポートもされていません
。 -
このモードの使用を妨げる特定の高度なユースケースがない限り、自動検出
は有効です。
IAM ロールへの最小特権アクセスを採用する
Auto Discoveryautoscaling:SetDesiredCapacityと Auto Scaling グループを制限してautoscaling:TerminateInstanceInAutoScalingGroup、最小特権アクセスを採用することを強くお勧めします。
これにより、--node-group-auto-discovery引数がタグ ( など) を使用してクラスターのノードグループにスコープダウンされていない場合でも、1 つのクラスターで実行されている Cluster Autoscaler が別のクラスターのノードグループを変更できなくなりますk8s.io/cluster-autoscaler/<cluster-name>。
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "autoscaling:SetDesiredCapacity", "autoscaling:TerminateInstanceInAutoScalingGroup" ], "Resource": "*", "Condition": { "StringEquals": { "aws:ResourceTag/k8s.io/cluster-autoscaler/enabled": "true", "aws:ResourceTag/k8s.io/cluster-autoscaler/my-cluster": "owned" } } }, { "Effect": "Allow", "Action": [ "autoscaling:DescribeAutoScalingGroups", "autoscaling:DescribeAutoScalingInstances", "autoscaling:DescribeLaunchConfigurations", "autoscaling:DescribeScalingActivities", "autoscaling:DescribeTags", "ec2:DescribeImages", "ec2:DescribeInstanceTypes", "ec2:DescribeLaunchTemplateVersions", "ec2:GetInstanceTypesFromInstanceRequirements", "eks:DescribeNodegroup" ], "Resource": "*" } ] }
ノードグループの設定
効果的な自動スケーリングは、クラスターの一連のノードグループを正しく設定することから始まります。適切なノードグループのセットを選択することは、ワークロード全体の可用性を最大化し、コストを削減するために重要です。AWS は EC2 Auto Scaling Groups を使用してノードグループを実装します。これは、多数のユースケースに柔軟に対応します。ただし、Cluster Autoscaler はノードグループについていくつかの仮定を行います。EC2 Auto Scaling グループの設定をこれらの前提と一致させることで、望ましくない動作を最小限に抑えることができます。
以下を確認してください。
-
ノードグループ内の各ノードには、ラベル、テイント、リソースなどの同じスケジューリングプロパティがあります。
-
MixedInstancePolicies の場合、インスタンスタイプは CPU、メモリ、GPU で同じ形状である必要があります
-
ポリシーで指定された最初のインスタンスタイプは、スケジューリングをシミュレートするために使用されます。
-
ポリシーにより多くのリソースを持つ追加のインスタンスタイプがある場合、リソースはスケールアウト後に浪費される可能性があります。
-
ポリシーにリソースが少ない追加のインスタンスタイプがある場合、ポッドはインスタンスでスケジュールに失敗する可能性があります。
-
-
ノード数が多いノードグループは、ノード数が少ない多くのノードグループよりも優先されます。これはスケーラビリティに最も大きな影響を与えます。
-
可能な限り、両方のシステムがサポートを提供する場合、EC2 機能 ( リージョン、MixedInstancePolicy など) を優先します。
注記
EKS Managed Node Groups を使用することをお勧めします。マネージド型ノードグループには、EC2 Auto Scaling グループの自動検出や正常なノード終了などの Cluster Autoscaler の機能など、強力な管理機能があります。
パフォーマンスとスケーラビリティの最適化
Auto Scaling アルゴリズムのランタイムの複雑さを理解することで、Cluster Autoscaler を調整して、1,000
Cluster Autoscaler のスケーラビリティを調整するための主なつまみは、プロセスに提供されるリソース、アルゴリズムのスキャン間隔、クラスター内のノードグループの数です。このアルゴリズムの実際のランタイムの複雑さには、プラグインの複雑さやポッドの数のスケジューリングなど、他の要因があります。これらはクラスターのワークロードにとって自然であり、簡単に調整できないため、設定不可能なパラメータと見なされます。
Cluster Autoscaler は、ポッド、ノード、ノードグループなど、クラスターの状態全体をメモリにロードします。スキャン間隔ごとに、アルゴリズムはスケジュール不可能なポッドを識別し、各ノードグループのスケジューリングをシミュレートします。これらの要素の調整にはさまざまなトレードオフがあるため、ユースケースに合わせて慎重に検討する必要があります。
Cluster Autoscaler の垂直的自動スケーリング
Cluster Autoscaler を大規模なクラスタにスケーリングする最も簡単な方法は、デプロイのリソースに対するリクエストを増やすことです。大規模なクラスターでは、メモリと CPU の両方を増やす必要があります。ただし、この数値はクラスターのサイズによって大きく異なります。自動スケーリングアルゴリズムは、すべてのポッドとノードをメモリに保存するため、場合によっては 1 ギガバイトを超えるメモリフットプリントが発生する可能性があります。リソースの増加は通常、手動で行われます。定常的なリソース調整作業が運用上の負担となる場合には、Addon Resizer
ノードグループの数を減らす
ノードグループの数を最小限に抑えることは、Cluster Autoscaler が大規模なクラスターでも引き続き優れたパフォーマンスを発揮できるようにするための 1 つの方法です。これは、チームごとまたはアプリケーションごとにノードグループを構築する一部の組織では難しい場合があります。これは Kubernetes API で完全にサポートされていますが、スケーラビリティに影響する Cluster Autoscaler アンチパターンと見なされます。複数のノードグループ ( スポットや GPUs など) を使用する理由は多数ありますが、多くの場合、少数のグループを使用しながら同じ効果を実現する代替設計があります。
以下を確認してください。
-
ポッドの分離は、ノードグループではなく名前空間を使用して行われます。
-
この処理は、低信頼のマルチテナントクラスターでは不可能な場合があります。
-
Pod ResourceRequests と ResourceLimits は、リソースの競合を避けるために適切に設定されています。
-
インスタンスタイプが大きいほど、ビンパッキングがより最適化され、システムポッドのオーバーヘッドが削減されます。
-
-
NodeTaints または NodeSelectors は、ルールではなく例外としてポッドをスケジュールするために使用されます。
-
リージョンリソースは、複数のアベイラビリティーゾーンを持つ単一の EC2 Auto Scaling グループとして定義されます。
スキャン間隔の短縮
スキャン間隔を短くすると ( 10 秒など)、ポッドがスケジュールできなくなったときに Cluster Autoscaler ができるだけ早く応答します。ただし、各スキャンでは、Kubernetes API および EC2 Auto Scaling グループまたは EKS Managed Node Group API への多くの APIs コールが発生します。これらの API コールは、Kubernetes コントロールプレーンのレート制限やサービス利用不能につながる可能性があります。
デフォルトのスキャン間隔は 10 秒ですが、AWS では、ノードの起動に新しいインスタンスの起動にかなり時間がかかります。つまり、全体的なスケールアップ時間を大幅に増やすことなく、スキャン間隔を増やすことが可能だということです。たとえば、ノードの起動に 2 分かかる場合、間隔を 1 分に変更すると、API コールが 6 倍減少し、スケールアップが 38% 遅くなります。
ノードグループ間のシャーディング
Cluster Autoscaler は、特定のノードグループのセットで動作するように設定できます。この機能を使用すると、Cluster Autoscaler の複数のインスタンスをデプロイできます。それぞれが異なるノードグループのセットで動作するように設定されています。この戦略により、任意の数のノードグループを使用し、スケーラビリティのためにコストを取引できます。パフォーマンスを向上させるための最後の手段としてのみ、これを使用することをお勧めします。
Cluster Autoscaler はもともとこの設定用に設計されていないため、いくつかの副作用があります。シャードは通信しないため、複数のオートスケーラーがスケジュール不可能なポッドをスケジュールしようとする可能性があります。これにより、複数のノードグループから不要なスケールアウトが発生する可能性があります。これらの追加のノードは、 の後にスケールバックされますscale-down-delay。
metadata: name: cluster-autoscaler namespace: cluster-autoscaler-1 ... --nodes=1:10:k8s-worker-asg-1 --nodes=1:10:k8s-worker-asg-2 --- metadata: name: cluster-autoscaler namespace: cluster-autoscaler-2 ... --nodes=1:10:k8s-worker-asg-3 --nodes=1:10:k8s-worker-asg-4
以下を確認してください。
-
各シャードは、EC2 Auto Scaling グループの一意のセットを指すように設定されています。
-
リーダー選挙の競合を避けるため、各シャードは個別の名前空間にデプロイされます。
コストと可用性の最適化
スポットインスタンス
ノードグループでスポットインスタンスを使用し、オンデマンド料金から最大 90% を節約できます。EC2 で容量を戻す必要がある場合は、いつでもスポットインスタンスを中断できます。キャパシティ不足エラーは、EC2 Auto Scaling グループが使用可能なキャパシティ不足のためにスケールアップできない場合に発生します。多くのインスタンスファミリーを選択して多様性を最大化すると、多くのスポットキャパシティープールを活用して希望するスケールを達成できる可能性が高くなり、クラスターの可用性に対するスポットインスタンスの中断の影響が軽減されます。スポットインスタンスにより多種類のインスタンスポリシーを使用することは、ノードグループの数を増やすことなく多様性を高める優れた方法です。保証されたリソースが必要な場合は、スポットインスタンスの代わりにオンデマンドインスタンスを使用してください。
混合インスタンスポリシーを設定するときは、すべてのインスタンスタイプに同様のリソース容量があることが重要です。オートスケーラーのスケジューリングシミュレーターは、MixedInstancePolicy の最初の InstanceType InstanceType を使用します。後続のインスタンスタイプが大きい場合、スケールアップ後にリソースが浪費される可能性があります。後続がより小さい場合には、容量不足のために、ポッドは新しいインスタンスでのスケジュールに失敗することがあります。例えば、M4、M5、M5a、M5n インスタンスはすべて同じ量の CPU とメモリを持ち、MixedInstancePolicy の候補として最適です。EC2 Instance Selector
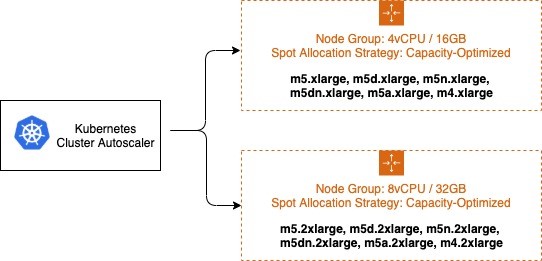
オンデマンドキャパシティとスポットキャパシティを別々の EC2 Auto Scaling グループに分離することをお勧めします。これは、スケジューリングプロパティが根本的に異なるため、基本容量戦略を使用するよりも優先されます。スポットインスタンスはいつでも中断されるため (EC2 が容量を戻す必要がある場合)、ユーザーは多くの場合、プリエンプション可能なノードをテイントし、プリエンプション動作に対するポッドの明示的な許容性を必要とします。これらのテイントはノードのスケジューリングプロパティが異なるため、複数の EC2 Auto Scaling グループに分割する必要があります。
Cluster Autoscaler には、スケーリングするノードグループを選択するためのさまざまな戦略を提供するエクスパンダー--expander=least-wasteは優れた汎用デフォルトであり、スポットインスタンスの分散に複数のノードグループを使用する場合 (上の図を参照)、スケーリングアクティビティの後に最もよく利用されるグループをスケーリングすることで、ノードグループをさらにコスト最適化できます。
ノードグループ/ASG の優先順位付け
Priority エクスパンダーを使用して優先度ベースの自動スケーリングを設定することもできます。 は、クラスターがノードグループ/ASG に優先順位を付けること--expander=priorityを可能にし、何らかの理由でスケーリングできない場合は、優先順位リストで次のノードグループを選択します。これは、GPU がワークロードに最適なパフォーマンスを提供するため、P3 インスタンスタイプを使用する場合などに便利ですが、2 番目のオプションとして P2 インスタンスタイプを使用することもできます。
apiVersion: v1 kind: ConfigMap metadata: name: cluster-autoscaler-priority-expander namespace: kube-system data: priorities: |- 10: - .*p2-node-group.* 50: - .*p3-node-group.*
Cluster Autoscaler は、名前 p3-node-group に一致する EC2 Auto Scaling グループをスケールアップしようとします。 このオペレーションが 内で成功しない場合--max-node-provision-time、名前 p2-node-group に一致する EC2 Auto Scaling グループのスケーリングを試みます。 この値のデフォルトは 15 分で、これを短くすることで、応答性の高いノードグループを選択することもできます。ただし、値を小さくしすぎると、不要なスケールアウトを発生させる可能性があります。
オーバープロビジョニング
Cluster Autoscaler は、必要性がある場合にのみノードがクラスタに追加され、使用されなくなった際には削除されるようにすることで、コストを最小限に抑えます。この構成では、スケジューリングされる前の多くのポッドが、ノードのスケールアップを待たせざるを得ないため、デプロイのレイテンシーに大きな影響を与えます。ノードが使用可能になるまでに数分かかることがあり、ポッドのスケジューリングのレイテンシーが桁違いに増加する可能性があります。
この問題は、オーバープロビジョニング
オーバープロビジョニングには、他にあまり明確でない利点があります。オーバープロビジョニングを行わない場合、使用率の高いクラスターの副作用の 1 つは、ポッドが Pod または Node Affinity のpreferredDuringSchedulingIgnoredDuringExecutionルールを使用して最適なスケジューリング決定を下さないことです。これの一般的なユースケースは、AntiAffinity を使用して可用性の高いアプリケーションのポッドをアベイラビリティーゾーン間で分離することです。オーバープロビジョニングは、正しいゾーンのノードが使用可能になる可能性を大幅に増やす可能性があります。
過剰にプロビジョニングされた容量の量は、組織にとって慎重なビジネス上の決定です。その中核となるのは、パフォーマンスとコストのトレードオフです。この決定を行う 1 つの方法は、平均スケールアップ頻度を決定し、それを新しいノードのスケールアップにかかる時間で割ることです。例えば、平均して 30 秒ごとに新しいノードが必要で、EC2 が新しいノードをプロビジョニングするのに 30 秒かかる場合、オーバープロビジョニングの 1 つのノードによって常に追加のノードが利用可能になり、1 つの EC2 インスタンスのコストでスケジューリングのレイテンシーが 30 秒短縮されます。ゾーンスケジューリングの決定を改善するには、EC2 Auto Scaling グループのアベイラビリティーゾーンの数と等しい数のノードをオーバープロビジョニングして、スケジューラが受信ポッドに最適なゾーンを選択できるようにします。
スケールダウンエビクションの防止
一部のワークロードでは、削除にコストがかかります。ビッグデータ分析、機械学習タスク、テストランナーは最終的に完了しますが、中断した場合は再起動する必要があります。Cluster Autoscaler は、scale-down-utilization-thresholdの下にあるノードをスケールダウンしようとします。これにより、ノード上の残りのポッドが中断されます。これは、削除にコストがかかるポッドが、Cluster Autoscaler によって認識されるラベルによって保護されるようにすることで防止できます。
以下を確認してください。
-
ポッドの削除にコストがかかると、 注釈が付けられます。
cluster-autoscaler.kubernetes.io/safe-to-evict=false
高度なユースケース
EBS ボリューム
データベースや分散キャッシュなどのステートフルアプリケーションを構築するには、永続的ストレージが不可欠です。EBS ボリュームは
以下を確認してください。
-
balance-similar-node-groups=trueを設定することで、ノードグループのバランシングが有効化されている。 -
ノードグループは、異なるアベイラビリティーゾーンと EBS ボリュームを除いて、同じ設定で設定されます。
共同スケジューリング
機械学習の分散型トレーニングジョブでは、共通のゾーンを使用するノード構成によりレイテンシーを最小化できるので、大きなメリットが得られます。これらのワークロードは、複数のポッドを特定のゾーンにデプロイします。これは、 を使用して、すべての共同スケジュールされたポッドまたは Node Affinity に Pod Affinity を設定することで実現できますtopologyKey: failure-domain.beta.kubernetes.io/zone。その後、Cluster Autoscaler は需要に合わせて特定のゾーンをスケールアウトします。複数の EC2 Auto Scaling グループをアベイラビリティーゾーンごとに 1 つずつ割り当てて、共同スケジュールされたワークロード全体のフェイルオーバーを有効にできます。
以下を確認してください。
-
balance-similar-node-groups=falseを設定することで、ノードグループのバランシングが有効化されている。 -
Node Affinity
や Pod Preemption は、クラスターにリージョンノードグループとゾーンノードグループの両方が含まれている場合に使用されます。 -
Node Affinity
を使用して、ゾーンノードグループを回避するためにリージョンポッドを強制または奨励します。その逆も同様です。 -
ゾーンポッドがリージョン別ノードグループにスケジュールされると、リージョン別ポッドの容量が不均衡になります。
-
ゾーンワークロードが中断と再配置を許容できる場合は、リージョン別にスケーリングされたポッドが競合の少ないゾーンでプリエンプションと再スケジュールを強制できるように Pod Preemption
を設定します。
-
アクセラレータ
一部のクラスターでは、GPU などの特殊なハードウェアアクセラレーターを利用しています。スケールアウトが行われた場合、アクセラレーターデバイスのプラグインがリソースをクラスターにアドバタイズするのに、数分かかることがあります。Cluster Autoscaler は、このノードにアクセラレーターがあることをシミュレートしましたが、アクセラレーターの準備が整い、ノードの使用可能なリソースが更新されるまで、保留中のポッドをノードでスケジュールすることはできません。これは、不要なスケールアウトが繰り返される
さらに、アクセラレーターがあり、CPU またはメモリ使用率が高いノードは、アクセラレーターが未使用であってもスケールダウンの対象として考慮されません。この動作は、アクセラレーターの相対コストのため、高価になる可能性があります。代わりに、Cluster Autoscaler は特別なルールを適用して、占有されていないアクセラレーターがある場合にスケールダウンするノードを考慮できます。
このような場合の正しい動作を確保するために、アクセラレーターノードで kubelet を設定して、クラスターに参加する前にノードにラベルを付けることができます。Cluster Autoscaler は、このラベルセレクタを使用してアクセラレーターに最適化された動作をトリガーします。
以下を確認してください。
-
GPU ノードの Kubelet は で設定されます。
--node-labels k8s.amazonaws.com/accelerator=$ACCELERATOR_TYPE -
Accelerator を使用するノードは、上記の同じスケジューリングプロパティルールに従います。
0 からのスケーリング
Cluster Autoscaler は、ゼロとの間でノードグループをスケーリングできるため、大幅なコスト削減につながります。LaunchConfiguration または LaunchTemplate で指定された InstanceType を調べることで、Auto Scaling グループの CPU、メモリ、GPU リソースを検出します。一部のポッドには、LaunchConfiguration から検出できない PrivateIPv4Address WindowsENIや特定の NodeSelectors や Taints などの追加のリソースが必要です。Cluster Autoscaler はEC2 Auto Scaling グループのタグから検出することで、これらの要因を考慮できます。例えば、次のようになります。
Key: k8s.io/cluster-autoscaler/node-template/resources/$RESOURCE_NAME Value: 5 Key: k8s.io/cluster-autoscaler/node-template/label/$LABEL_KEY Value: $LABEL_VALUE Key: k8s.io/cluster-autoscaler/node-template/taint/$TAINT_KEY Value: NoSchedule
注記
ゼロにスケーリングすると、容量は EC2 に返され、将来使用できなくなる可能性があることに注意してください。
追加のパラメータ
Cluster Autoscaler には、動作とパフォーマンスを調整するために使用できる多くの設定オプションが用意されています。パラメータの完全なリストは、GitHub
| パラメータ | 説明 | デフォルト |
|---|---|---|
|
スキャン間隔 |
スケールアップまたはスケールダウンのためにクラスターが再評価される頻度 |
10 秒 |
|
max-empty-bulk-delete |
同時に削除できる空のノードの最大数。 |
10 |
|
scale-down-delay-after-add |
スケールアップ後のスケールダウン評価の再開時間 |
10 分 |
|
scale-down-delay-after-delete |
評価をスケールダウンするノードの削除が再開されてから、デフォルトではスキャン間隔になります。 |
スキャン間隔 |
|
scale-down-delay-after-failure |
スケールダウン失敗後にスケールダウン評価が再開される期間 |
3 分 |
|
scale-down-unneeded-time |
スケールダウンの対象となるまでにノードが必要でない期間 |
10 分 |
|
scale-down-unready-time |
スケールダウンの対象となるまでに、準備されていないノードが不要になる期間 |
20 分 |
|
scale-down-utilization-threshold |
リクエストされたリソースの合計を容量で割ったノード使用率。これを下回ると、ノードのスケールダウンを検討できます。 |
0.5 |
|
scale-down-non-empty-candidates-count |
ドレインによるスケールダウンの候補として 1 回の反復で考慮される空でないノードの最大数。値が低いほど、CA の応答性は向上しますが、スケールダウンレイテンシーが遅くなる可能性があります。値を大きくすると、大きなクラスター (数百のノード) の CA パフォーマンスに影響する可能性があります。このヒューリスティックをオフにするには、非正の値に設定します。CA は考慮するノードの数を制限しません。 |
30 |
|
scale-down-candidates-pool-ratio |
以前のイテレーションの一部の候補が有効でなくなった場合に、スケールダウンのための追加の空でない候補と見なされるノードの比率。値が低いほど、CA の応答性は向上しますが、スケールダウンレイテンシーが遅くなる可能性があります。値を大きくすると、大きなクラスター (数百のノード) の CA パフォーマンスに影響する可能性があります。このヒューリスティックをオフにするには 1.0 に設定します。CA はすべてのノードを追加候補として受け取ります。 |
0.1 |
|
scale-down-candidates-pool-min-count |
以前のイテレーションの一部の候補が有効でなくなった場合に、スケールダウンの空の候補ではない追加のノードの最小数。追加の候補のプールサイズを計算する場合 |
50 |
その他のリソース
このページには、Cluster Autoscaler のプレゼンテーションとデモのリストが含まれています。ここでプレゼンテーションやデモを追加する場合は、プルリクエストを送信してください。
| プレゼンテーション/デモ | プレゼンター |
|---|---|
|
Guy Templeton、Skyscanner & Jiaxin Shan、Amazon |
|
|
Maciek Pytel & Marcin Wielgus |
リファレンス
-
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md
-
https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
-
https://github.com/aws/amazon-ec2-instance-selector
-
https://github.com/aws/aws-node-termination-handler
