翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
高可用性アプリケーションの実行
お客様は、変更を行う場合や特にトラフィックの急増時など、アプリケーションを常に利用できることを期待しています。スケーラブルで回復力のあるアーキテクチャにより、アプリケーションやサービスを中断することなく実行し、ユーザーを満足させます。スケーラブルなインフラストラクチャは、ビジネスのニーズに基づいて増減します。単一障害点を排除することは、アプリケーションの可用性を向上させ、回復力を高めるための重要なステップです。
Kubernetes を使用すると、アプリケーションを運用し、可用性と回復力に優れた方法で実行できます。宣言型管理により、アプリケーションを設定すると、Kubernetes は引き続き現在の状態を目的の状態と照合しようとします
推奨事項
Pod Disruption Budgets を設定する
Pod Disruption Budgets
シングルトンポッドの実行を避ける
アプリケーション全体が 1 つの Pod で実行されている場合、その Pod が終了するとアプリケーションは使用できなくなります。個々のポッドを使用してアプリケーションをデプロイする代わりに、デプロイ
複数のレプリカを実行する
デプロイを使用してアプリケーションの複数のレプリカポッドを実行すると、可用性の高い方法で実行できます。1 つのレプリカが失敗しても、残りのレプリカは機能します。ただし、Kubernetes が損失を補うために別の Pod を作成するまで、容量は減ります。さらに、Horizontal Pod Autoscaler
ノード間でレプリカをスケジュールする
複数のレプリカを実行することは、すべてのレプリカが同じノードで実行されていて、ノードが使用できなくなった場合にはあまり役に立ちません。ポッドアンチアフィニティまたはポッドトポロジの分散制約を使用して、デプロイのレプリカを複数のワーカーノードに分散することを検討してください。
複数の AZs で実行することで、一般的なアプリケーションの信頼性をさらに向上させることができます。
Pod アンチアフィニティルールの使用
以下のマニフェストは、ポッドを別々のノードと AZ に配置することを Kubernetes スケジューラに指示します。 AZs 個別のノードや AZ は必要ありません。そうすると、各 AZ でポッドが実行されると、Kubernetes はポッドをスケジュールできなくなります。アプリケーションに必要なレプリカが 3 つしかない場合は、 requiredDuringSchedulingIgnoredDuringExecutionに を使用できます。Kubernetes topologyKey: topology.kubernetes.io/zoneスケジューラは同じ AZ で 2 つのポッドをスケジュールしません。
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 4 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: topology.kubernetes.io/zone weight: 100 - podAffinityTerm: labelSelector: matchExpressions: - key: app operator: In values: - web-server topologyKey: kubernetes.io/hostname weight: 99 containers: - name: web-app image: nginx:1.16-alpine
ポッドトポロジの分散制約の使用
ポッドのアンチアフィニティルールと同様に、ポッドトポロジの分散制約により、ホストや AZs などのさまざまな障害 (またはトポロジ) ドメインでアプリケーションを使用できるようになります。このアプローチは、異なるトポロジドメインのそれぞれに複数のレプリカがあることで、耐障害性と可用性を確保しようとする場合に非常に効果的です。一方、ポッドのアンチアフィニティルールは、互いにアンチアフィニティを持つポッドが反発効果を持つため、トポロジドメインに 1 つのレプリカがある場合に簡単に結果を生成できます。このような場合、専用ノード上の 1 つのレプリカは耐障害性には適していません。また、リソースの適切な使用にも適していません。トポロジの分散制約を使用すると、スケジューラがトポロジドメイン全体に適用しようとするスプレッドまたはディストリビューションをより細かく制御できます。このアプローチで使用する重要なプロパティを以下に示します。
-
maxSkewは、トポロジドメイン間でモノが不均等になる最大ポイントを制御または決定するために使用します。たとえば、アプリケーションに 10 個のレプリカがあり、3 つの AZs にデプロイされている場合、均等に分散することはできませんが、ディストリビューションの不均等さに影響を与えることができます。この場合、 は 1~10 のいずれかmaxSkewになります。値 1 は、 のようなスプレッド4,3,3、3,4,3または 3 つの AZs3,3,4にまたがるスプレッドになる可能性があることを意味します。対照的に、値が 10 の場合、 のようなスプレッド10,0,0、0,10,0または 3 つの AZs0,0,10にまたがるスプレッドになる可能性があります。 -
topologyKeyはノードラベルの 1 つのキーであり、ポッドディストリビューションに使用するトポロジドメインのタイプを定義します。たとえば、ゾーンスプレッドには次のキーと値のペアがあります。topologyKey: "topology.kubernetes.io/zone" -
whenUnsatisfiableプロパティは、必要な制約が満たされない場合にスケジューラがどのように応答するかを決定するために使用されます。 -
labelSelectorは、指定した制約に従ってポッドを配置する場所を決定するときにスケジューラがポッドを認識できるように、一致するポッドを見つけるために使用されます。
上記に加えて、Kubernetes ドキュメント
ポッドトポロジーが 3 つの AZs
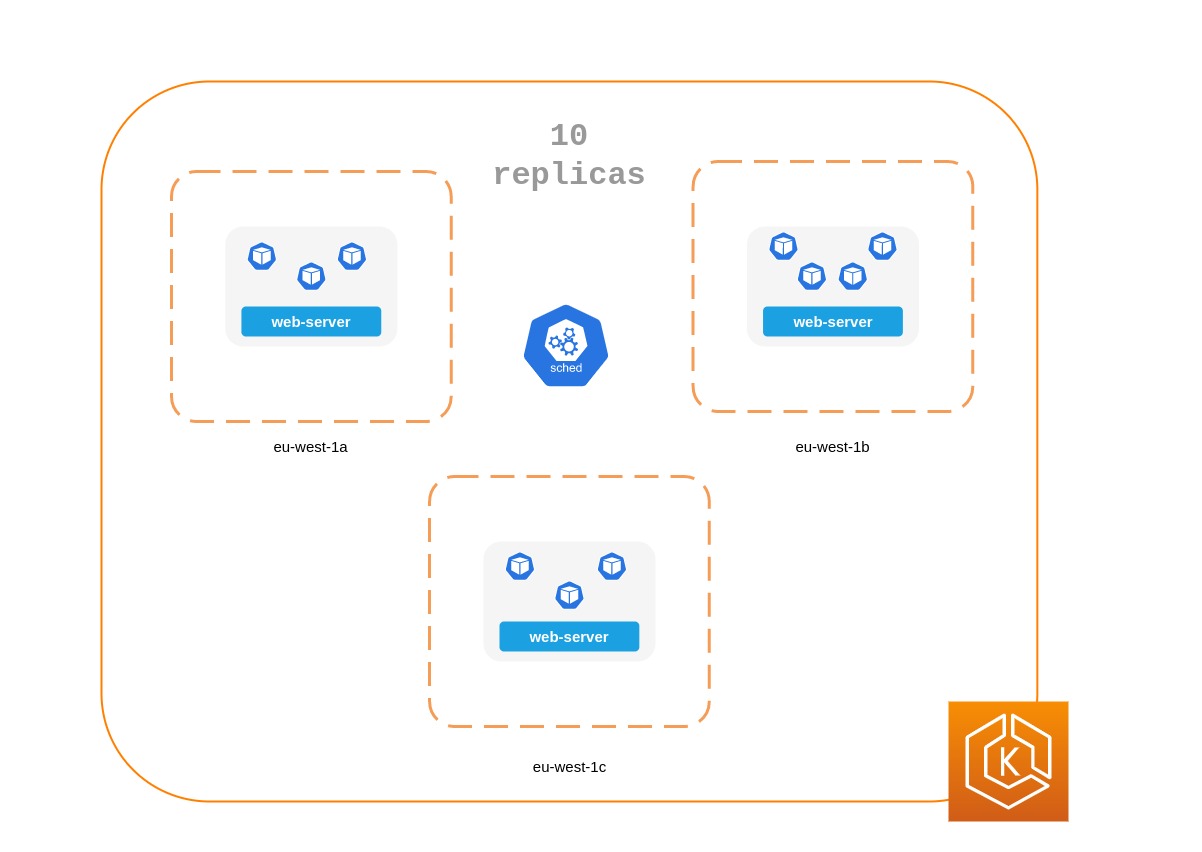
apiVersion: apps/v1 kind: Deployment metadata: name: spread-host-az labels: app: web-server spec: replicas: 10 selector: matchLabels: app: web-server template: metadata: labels: app: web-server spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: "topology.kubernetes.io/zone" whenUnsatisfiable: ScheduleAnyway labelSelector: matchLabels: app: express-test containers: - name: web-app image: nginx:1.16-alpine
Kubernetes メトリクスサーバーを実行する
Kubernetes メトリクスサーバー
メトリクスサーバーはデータを保持せず、モニタリングソリューションではありません。その目的は、CPU とメモリの使用状況メトリクスを他のシステムに公開することです。アプリケーションの状態を経時的に追跡する場合は、Prometheus や Amazon CloudWatch などのモニタリングツールが必要です。
EKS ドキュメントに従って、EKS クラスターに metrics-server をインストールします。
水平ポッドオートスケーラー (HPA)
HPA は、需要に応じてアプリケーションを自動的にスケーリングし、ピークトラフィック中に顧客に影響を与えないようにできます。これは、リソースメトリクスを提供する APIsする Kubernetes のコントロールループとして実装されます。
HPA は、次の APIs からメトリクスを取得できます。1. Resource Metrics API metrics.k8s.io とも呼ばれる — ポッド 2 の CPU とメモリの使用量を提供します。 custom.metrics.k8s.io— Prometheus などの他のメトリクスコレクターからのメトリクスを提供します。これらのメトリクスは Kubernetes クラスターの内部にあります。3. external.metrics.k8s.io — Kubernetes クラスターの外部にあるメトリクスを提供します (SQS キューの深さ、ELB レイテンシーなど)。
これら 3 つの APIs のいずれかを使用して、アプリケーションをスケールするための メトリクスを指定する必要があります。
カスタムメトリクスまたは外部メトリクスに基づくアプリケーションのスケーリング
カスタムメトリクスまたは外部メトリクスを使用して、CPU またはメモリ使用率以外のメトリクスでアプリケーションをスケーリングできます。カスタムメトリクスcustom-metrics.k8s.io API を提供します。
Prometheus Adapter for Kubernetes Metrics APIs
Prometheus Adapter をデプロイしたら、kubectl を使用してカスタムメトリクスをクエリできます。 kubectl get —raw /apis/custom.metrics.k8s.io/v1beta1/
外部メトリクスは、名前が示すように、Kubernetes クラスターの外部にあるメトリクスを使用してデプロイをスケールする機能を Horizontal Pod Autoscaler に提供します。たとえば、バッチ処理ワークロードでは、SQS キューで処理中のジョブの数に基づいてレプリカの数をスケールするのが一般的です。
Kubernetes ワークロードをオートスケーリングするには、KEDA (Kubernetes Event-driven Autoscaling) を使用できます。これは、多数のカスタムイベントに基づいてコンテナスケーリングを駆動できるオープンソースプロジェクトです。この AWS ブログ
垂直ポッドオートスケーラー (VPA)
VPA は、アプリケーションの「適切なサイズ」に役立つように、Pod の CPU とメモリの予約を自動的に調整します。リソース割り当てを増やすことで実行される垂直スケーリングが必要なアプリケーションの場合、VPA
VPA の現在の実装ではポッドにインプレース調整が実行されないため、VPA がスケーリングする必要がある場合、アプリケーションは一時的に使用できなくなる可能性があります。代わりに、スケーリングする必要があるポッドを再作成します。
EKS ドキュメントには、VPA を設定するためのチュートリアルが含まれています。
Fairwinds Goldilocks
アプリケーションの更新
最新のアプリケーションには、高い安定性と可用性を備えた迅速なイノベーションが必要です。Kubernetes は、顧客を中断することなくアプリケーションを継続的に更新するためのツールを提供します。
可用性を犠牲にすることなく変更を迅速にデプロイできるようにするベストプラクティスをいくつか見てみましょう。
ロールバックを実行するメカニズムがある
元に戻すボタンがあると、災害を回避できます。本番環境クラスターを更新する前に、別の下位環境 (テスト環境または開発環境) でデプロイをテストするのがベストプラクティスです。CI/CD パイプラインを使用すると、デプロイの自動化とテストに役立ちます。継続的なデプロイパイプラインを使用すると、アップグレードに欠陥が発生した場合に、古いバージョンにすばやく戻ることができます。
デプロイを使用して、実行中のアプリケーションを更新できます。これは通常、コンテナイメージを更新することによって行われます。kubectl を使用して、次のようなデプロイを更新できます。
kubectl --record deployment.apps/nginx-deployment set image nginx-deployment nginx=nginx:1.16.1
--record 引数はデプロイの変更を記録し、ロールバックを実行する必要がある場合に役立ちます。 は、クラスター内のデプロイに記録された変更kubectl rollout history deploymentを表示します。を使用して変更をロールバックできますkubectl rollout undo deployment <DEPLOYMENT_NAME>。
デフォルトでは、ポッドの再作成を必要とするデプロイを更新すると、デプロイはローリング更新RollingUpdateStrategyプロパティを使用してローリング更新を実行する方法を制御できます。
デプロイのローリング更新を実行する場合、 Max UnavailableMax Surgeプロパティを使用すると、必要な数のポッドに対して作成できるポッドの最大数を設定できます。
ロールアウトが顧客max unavailableを混乱させないように調整することを検討してください。例えば、Kubernetes max unavailableはデフォルトで 25% を設定します。つまり、100 個のポッドがある場合、ロールアウト中にアクティブに動作しているポッドは 75 個のみです。アプリケーションで最低 80 個の Pod が必要な場合は、このロールアウトが中断される可能性があります。代わりに、 を 20% max unavailableに設定して、ロールアウト全体で少なくとも 80 個の機能ポッドがあることを確認できます。
Blue/Green デプロイを使用する
変更には本質的にリスクが伴いますが、元に戻すことができない変更は致命的になる可能性があります。ロールバックを通じて時間を効果的に戻すことができる変更手順により、機能強化と実験の安全性が向上します。ブルー/グリーンデプロイでは、問題が発生した場合に変更をすばやく取り消すことができます。このデプロイ戦略では、新しいバージョンの環境を作成します。この環境は、更新されるアプリケーションの最新バージョンと同じです。新しい環境がプロビジョニングされると、トラフィックは新しい環境にルーティングされます。新しいバージョンがエラーを発生させずに必要な結果を生成する場合、古い環境は終了します。それ以外の場合、トラフィックは古いバージョンに復元されます。
Kubernetes でブルー/グリーンデプロイを実行するには、既存のバージョンのデプロイと同じ新しいデプロイを作成します。新しいデプロイのポッドがエラーなしで実行されていることを確認したら、アプリケーションのポッドにトラフィックをルーティングするサービスのselector仕様を変更することで、新しいデプロイへのトラフィックの送信を開始できます。
Flux
Canary デプロイを使用する
Canary デプロイは、変更からリスクを大幅に排除できる Blue/Green デプロイのバリアントです。このデプロイ戦略では、古いデプロイと並行してポッド数が少ない新しいデプロイを作成し、トラフィックのごく一部を新しいデプロイに振り向けます。メトリクスが、新しいバージョンのパフォーマンスが既存のバージョンと同じかそれ以上であることを示している場合は、新しいデプロイへのトラフィックを徐々に増やし、すべてのトラフィックが新しいデプロイに転送されるまでスケールアップします。問題が発生した場合は、すべてのトラフィックを古いデプロイにルーティングし、新しいデプロイへのトラフィックの送信を停止できます。
Kubernetes には Canary デプロイを実行するネイティブな方法はありませんが、Istio
ヘルスチェックと自己修復
バグのないソフトウェアはありませんが、Kubernetes はソフトウェア障害の影響を最小限に抑えるのに役立ちます。以前は、アプリケーションがクラッシュした場合、アプリケーションを手動で再起動して状況を修復する必要がありました。Kubernetes では、ポッド内のソフトウェア障害を検出し、新しいレプリカに自動的に置き換えることができます。Kubernetes を使用すると、アプリケーションの状態をモニタリングし、異常なインスタンスを自動的に置き換えることができます。
Kubernetes は 3 種類のヘルスチェック
-
ライブネスプローブ
-
スタートアッププローブ (Kubernetes バージョン 1.16 以降でサポート)
-
準備状況プローブ
Kubernetes エージェントである Kubelet
コンテナ内でシェルスクリプトを実行する execベースのプローブを選択した場合は、timeoutSeconds値の有効期限が切れる前にシェルコマンドが終了していることを確認します。そうしないと、ノードに<defunct>プロセスが発生し、ノードに障害が発生します。
推奨事項
Liveness Probe を使用して異常なポッドを削除する
Liveness プローブは、プロセスが実行され続けるがアプリケーションが応答しなくなるデッドロック状態を検出できます。たとえば、ポート 80 でリッスンするウェブサービスを実行している場合は、Pod のポート 80 で HTTP GET リクエストを送信するように Liveness プローブを設定できます。Kubelet は定期的に GET リクエストを Pod に送信し、応答を期待します。Pod が 200~399 の間に応答した場合、kubelet は Pod が正常であると見なします。そうしないと、Pod は異常としてマークされます。Pod がヘルスチェックに継続的に失敗した場合、kubelet はそれを終了します。
を使用してinitialDelaySeconds、最初のプローブを遅延させることができます。
Liveness Probe を使用する場合は、Kubernetes がすべての Pod を置き換えようとし、アプリケーションがオフラインになるため、すべての Pod が同時に Liveness Probe に失敗する状況でアプリケーションが実行されないようにしてください。さらに、Kubernetes は引き続き Liveness Probes にも失敗する新しい Pod を作成し、コントロールプレーンに不要な負荷をかけます。外部データベースなど、Pod の外部にある要素に依存するように Liveness Probe を設定しないでください。つまり、応答しないexternal-to-your-Podデータベースは、ポッドが Liveness Probes に失敗しないようにする必要があります。
Sandor Szücs の投稿「LIVENESS PROBES ARE DANGEROUS
起動に時間がかかるアプリケーションに Startup Probe を使用する
アプリの起動にさらに時間が必要な場合は、Startup Probe を使用して Liveness and Readiness Probe を遅延させることができます。たとえば、データベースからキャッシュをハイドレートする必要がある Java アプリケーションは、完全に機能するまでに最大 2 分かかる場合があります。Liveness または Readiness Probe が完全に機能するまでは失敗する可能性があります。Startup Probe を設定すると、Liveness または Readiness Probe が実行される前に Java アプリが正常になります。
Startup Probe が成功するまで、他のすべてのプローブは無効になります。Kubernetes がアプリケーションの起動を待機する最大時間を定義できます。最大設定時間が経過しても Pod が起動プローブに失敗した場合、Pod は終了し、新しい Pod が作成されます。
Startup Probe は Liveness Probe に似ています。失敗すると、Pod が再作成されます。Ricardo A. が記事「Fantastic Probes and How To Configure TheminitialDelaySeconds代わりに で Liveness/Readiness Probe を使用する必要があります。
Readiness Probe を使用して部分的な利用不能を検出する
Liveness プローブが Pod を終了 (したがってアプリを再起動) して解決されたアプリの障害を検出する間、Readiness Probe はアプリが一時的に使用できない可能性のある状態を検出します。このような状況では、アプリが一時的に応答しなくなることがありますが、このオペレーションが完了すると再び正常であることが予想されます。
たとえば、強力なディスク I/O オペレーション中に、アプリケーションが一時的にリクエストを処理できない場合があります。ここでは、アプリケーションの Pod を終了することは解決策ではありません。同時に、Pod に送信される追加のリクエストが失敗する可能性があります。
Readiness Probe を使用すると、アプリで一時的な使用不能を検出し、再び機能するまで Pod へのリクエストの送信を停止できます。失敗によって Pod が再作成される Liveness Probe とは異なり、Readiness Probe が失敗すると、Pod は Kubernetes Service からトラフィックを受信しません。準備プローブが成功すると、Pod はサービスからのトラフィックの受信を再開します。
Liveness Probe と同様に、Pod の外部にあるリソース (データベースなど) に依存する Readiness Probe を設定しないでください。設定の不十分な準備状況によってアプリケーションが機能しなくなるシナリオを次に示します。アプリケーションのデータベースに到達できない場合に Pod の準備状況プローブが失敗すると、同じヘルスチェック基準を共有するため、他の Pod レプリカも同時に失敗します。この方法でプローブを設定すると、データベースが使用できないたびに Pod の準備プローブが失敗し、Kubernetes はすべての Pod へのトラフィックの送信を停止します。
Readiness Probes を使用する副作用は、デプロイの更新にかかる時間を短縮できることです。準備プローブが成功しない限り、新しいレプリカはトラフィックを受信しません。それまでは、古いレプリカは引き続きトラフィックを受信します。
中断への対応
Pod の有効期間は限られています。長時間稼働している Pod がある場合でも、Pod が正常に終了することを確認するのが賢明です。アップグレード戦略によっては、Kubernetes クラスターのアップグレードで新しいワーカーノードを作成する必要がある場合があります。そのため、すべての Pod を新しいノードで再作成する必要があります。適切な終了処理と Pod Disruption Budgets を使用すると、Pod が古いノードから削除され、新しいノードで再作成されるため、サービスの中断を回避できます。
ワーカーノードをアップグレードする推奨方法は、新しいワーカーノードを作成し、古いノードを終了することです。ワーカーノードを終了する前に、drain終了する必要があります。ワーカーノードがドレインされると、そのすべてのポッドは安全にエビクションされます。ここでのキーワードは安全です。ワーカーのポッドが削除されると、単にSIGKILLシグナルが送信されるわけではありません。代わりに、削除されるポッド内の各コンテナのメインプロセス (PID 1) にSIGTERMシグナルが送信されます。SIGTERM シグナルが送信されると、Kubernetes はSIGKILLシグナルが送信される前にプロセスに時間 (猶予期間) を与えます。この猶予期間はデフォルトで 30 秒です。デフォルトを上書きするには、kubectl の grace-periodフラグを使用するか、Podspec terminationGracePeriodSecondsで宣言します。
kubectl delete pod <pod name> —grace-period=<seconds>
通常、メインプロセスに PID 1 がないコンテナがあります。Python ベースのサンプルコンテナを考えてみましょう。
$ kubectl exec python-app -it ps PID USER TIME COMMAND 1 root 0:00 {script.sh} /bin/sh ./script.sh 5 root 0:00 python app.py
この例では、シェルスクリプトは SIGTERMを受け取ります。この例では Python アプリケーションであるメインプロセスは、SIGTERMシグナルを取得しません。Pod が終了すると、Python アプリケーションは突然強制終了します。これは、コンテナENTRYPOINT
コンテナフックPreStop フックアクションは、コンテナがSIGTERMシグナルを受信する前に実行され、このシグナルが送信される前に完了する必要があります。terminationGracePeriodSeconds 値は、SIGTERMシグナルが送信されたときではなく、PreStopフックアクションの実行が開始されたときから適用されます。
推奨事項
Pod Disruption Budgets で重要なワークロードを保護する
アプリケーションのレプリカ数が宣言されたしきい値を下回った場合、Pod Disruption Budget または PDB は一時的に削除プロセスを停止できます。使用可能なレプリカの数がしきい値を超えると、削除プロセスは続行されます。PDB を使用して、 minAvailableとレプリカmaxUnavailableの数を宣言できます。たとえば、アプリのコピーを 3 つ以上使用できるようにする場合は、PDB を作成できます。
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: my-svc-pdb spec: minAvailable: 3 selector: matchLabels: app: my-svc
上記の PDB ポリシーは、3 つ以上のレプリカが使用可能になるまでエビクションプロセスを停止するよう Kubernetes に指示します。ノードドレイニングは を尊重しますPodDisruptionBudgets。EKS マネージド型ノードグループのアップグレード中、ノードは 15 分のタイムアウトでドレインされます。15 分後、更新が強制されない場合 (オプションは EKS コンソールでローリング更新と呼ばれます)、更新は失敗します。更新を強制すると、ポッドは削除されます。
セルフマネージド型ノードの場合、AWS Node Termination Handler
Pod anti-affinity を使用して、異なるノードでデプロイの Pod をスケジュールし、ノードのアップグレード中の PDB 関連の遅延を回避できます。
カオスエンジニアリングを実践する
カオスエンジニアリングは、本番環境の乱れに耐えられるシステムの能力の信頼性を構築するために、分散システムで実験する分野です。
ブログで Dominik Tornow は、Kubernetes はreplicaクラッシュした場合、Deployment Contollerreplica。このようにして、Kubernetes コントローラーは障害を自動的に修正します。
Gremlin
Service Mesh を使用する
サービスメッシュを使用して、アプリケーションの耐障害性を向上させることができます。サービスメッシュにより、service-to-service通信が可能になり、マイクロサービスネットワークのオブザーバビリティが向上します。ほとんどのサービスメッシュ製品は、アプリケーションのネットワークトラフィックを傍受して検査する各サービスと一緒に小さなネットワークプロキシを実行することで機能します。アプリケーションを変更せずに、アプリケーションをメッシュに配置することができます。サービスプロキシの組み込み機能を使用すると、ネットワーク統計の生成、アクセスログの作成、分散トレースのアウトバウンドリクエストへの HTTP ヘッダーの追加を行うことができます。
サービスメッシュは、自動リクエストの再試行、タイムアウト、サーキットブレーク、レート制限などの機能により、マイクロサービスの耐障害性を高めるのに役立ちます。
複数のクラスターを操作する場合は、サービスメッシュを使用してクラスター間のservice-to-service通信を有効にできます。
サービスメッシュ
オブザーバビリティ
オブザーバビリティは、モニタリング、ログ記録、トレースを含む包括的な用語です。マイクロサービスベースのアプリケーションは、本質的に分散されます。単一のシステムのモニタリングで十分なモノリシックアプリケーションとは異なり、分散アプリケーションアーキテクチャでは、各コンポーネントのパフォーマンスをモニタリングする必要があります。クラスターレベルのモニタリング、ログ記録、分散トレースシステムを使用して、顧客を混乱させる前にクラスター内の問題を特定できます。
トラブルシューティングとモニタリング用の Kubernetes 組み込みツールは限られています。metrics-server はリソースメトリクスを収集してメモリに保存しますが、保持しません。kubectl を使用して Pod のログを表示できますが、Kubernetes は自動的にログを保持しません。また、分散トレースの実装は、アプリケーションコードレベルまたはサービスメッシュを使用して行われます。
Kubernetes の拡張性はここにあります。Kubernetes を使用すると、任意の一元的なモニタリング、ログ記録、トレースソリューションを導入できます。
推奨事項
アプリケーションをモニタリングする
最新のアプリケーションでモニタリングする必要があるメトリクスの数は継続的に増加しています。これは、お客様の課題の解決に集中できるように、アプリケーションを自動的に追跡する方法がある場合に役立ちます。Prometheus
モニタリングツールを使用すると、運用チームがサブスクライブできるアラートを作成できます。イベントに対してアラームをアクティブ化するルールを検討してください。イベントが悪化すると、停止したり、アプリケーションのパフォーマンスに影響を与えたりする可能性があります。
モニタリングすべきメトリクスが不明な場合は、次の方法からヒントを得ることができます。
Sysdig の記事 Kubernetes でのアラートのベストプラクティス
Prometheus クライアントライブラリを使用してアプリケーションメトリクスを公開する
アプリケーションの状態をモニタリングし、標準メトリクスを集約することに加えて、Prometheus クライアントライブラリ
一元的なログ記録ツールを使用してログを収集し、保持する
EKS でのログ記録は、コントロールプレーンログとアプリケーションログの 2 つのカテゴリに分類されます。EKS コントロールプレーンのログ記録は、コントロールプレーンからアカウントの CloudWatch Logs に直接監査ログと診断ログを提供します。アプリケーションログは、クラスター内で実行されている Pod によって生成されるログです。アプリケーションログには、ビジネスロジックアプリケーションを実行する Pod と、CoreDNS、Cluster Autoscaler、Prometheus などの Kubernetes システムコンポーネントによって生成されたログが含まれます。
EKS には、次の 5 種類のコントロールプレーンログが用意されています。
-
Kubernetes API サーバーコンポーネントログ
-
監査
-
オーセンティケーター
-
コントローラーマネージャー
-
スケジューラー
コントローラーマネージャーとスケジューラのログは、ボトルネックやエラーなどのコントロールプレーンの問題の診断に役立ちます。デフォルトでは、EKS コントロールプレーンログは CloudWatch Logs に送信されません。コントロールプレーンのログ記録を有効にし、アカウント内のクラスターごとにキャプチャする EKS コントロールプレーンログのタイプを選択できます。
アプリケーションログを収集するには、Fluent Bit
Kubernetes ログアグリゲータツールは DaemonSets として実行され、ノードからコンテナログをスクレイプします。その後、アプリケーションログは一元管理された保存先に送信されます。例えば、CloudWatch Container Insights は Fluent Bit または Fluentd を使用してログを収集し、CloudWatch Logs に送信して保存できます。Fluent Bit と Fluentd は、Elasticsearch や InfluxDB などの多くの一般的なログ分析システムをサポートしているため、Fluent ビットまたは Fluentd のログ設定を変更することで、ログのストレージバックエンドを変更できます。
分散トレースシステムを使用してボトルネックを特定する
一般的な最新のアプリケーションには、ネットワーク上に分散されたコンポーネントがあり、その信頼性は、アプリケーションを構成する各コンポーネントの適切な機能によって異なります。分散トレースソリューションを使用して、リクエストのフローとシステムの通信方法を理解できます。トレースは、アプリケーションネットワークにボトルネックが存在する場所を示し、カスケード障害を引き起こす可能性のある問題を防ぐことができます。
アプリケーションにトレースを実装するには、2 つのオプションがあります。共有ライブラリを使用してコードレベルで分散トレースを実装するか、サービスメッシュを使用できます。
コードレベルでトレースを実装すると、不利になる可能性があります。この方法では、コードを変更する必要があります。Polyglot アプリケーションがある場合、これはさらに複雑になります。また、サービス全体でさらに別のライブラリを維持する責任もあります。
LinkerD
AWS X-Ray
(共有ライブラリとサービスメッシュ) の両方の実装をサポートする AWS X-Ray
