翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
Couchbase サーバーからの移行
序章
このガイドでは、Couchbase Server から Amazon DocumentDB への移行時に考慮すべき重要なポイントについて説明します。ここでは、移行の検出、計画、実行、検証の各フェーズに関する考慮事項について説明します。また、オフライン移行とオンライン移行を実行する方法についても説明します。
Amazon DocumentDB との比較
| Couchbase サーバー | Amazon DocumentDB | |
|---|---|---|
| データ組織 | バージョン 7.0 以降では、データはバケット、スコープ、コレクションに整理されます。以前のバージョンでは、データはバケットに整理されています。 | データはデータベースとコレクションに整理されます。 |
| 互換性 | サービスごとに個別の APIs (データ、インデックス、検索など) があります。セカンダリルックアップは、ANSI 標準 SQL に基づくクエリ言語である SQL++ (以前は N1QL と呼ばれていました) を使用するため、多くの開発者が使い慣れています。 | Amazon DocumentDB は MongoDB API と互換性があります。 |
| アーキテクチャ | ストレージは各クラスターインスタンスにアタッチされます。コンピューティングをストレージとは別にスケールすることはできません。 | Amazon DocumentDB は、クラウド向けに設計されており、従来のデータベースアーキテクチャの制限を回避します。コンピューティングレイヤーとストレージレイヤーは Amazon DocumentDB で分離され、コンピューティングレイヤーはストレージとは別にスケーリングできます。 Amazon DocumentDB |
| オンデマンドで読み取りキャパシティを追加する | クラスターは、インスタンスを追加することでスケールアウトできます。ストレージはサービスが実行されているインスタンスにアタッチされるため、スケールアウトにかかる時間は、新しいインスタンスに移動するか、再調整する必要があるデータの量によって異なります。 | Amazon DocumentDB クラスターに最大 15 個の Amazon DocumentDB レプリカを作成することで、Amazon DocumentDB クラスターの読み取りスケーリングを実現できます。ストレージレイヤーには影響しません。 |
| ノード障害からの迅速な復旧 | クラスターには自動フェイルオーバー機能がありますが、クラスターを完全な強度に戻す時間は、新しいインスタンスに移動する必要があるデータの量によって異なります。 | Amazon DocumentDB は、通常 30 秒以内にプライマリをフェイルオーバーし、クラスター内のデータ量に関係なく、8~10 分でクラスターを完全な強度に戻すことができます。 |
| データの増加に応じてストレージをスケールする | セルフマネージド型クラスターの場合、ストレージと IOs は自動的にスケーリングされません。 | Amazon DocumentDB ストレージと IOsスケーリングされます。 |
| パフォーマンスに影響を与えずにデータをバックアップする | バックアップはバックアップサービスによって実行され、デフォルトでは有効になっていません。ストレージとコンピューティングは分離されていないため、パフォーマンスに影響を与える可能性があります。 | Amazon DocumentDB バックアップはデフォルトで有効になっており、オフにすることはできません。バックアップはストレージレイヤーによって処理されるため、コンピューティングレイヤーには影響しません。Amazon DocumentDB は、クラスタースナップショットからの復元と特定の時点への復元をサポートしています。 |
| データ耐久性 | クラスター内のデータには最大 3 つのレプリカコピーがあり、合計 4 つのコピーがあります。データサービスが実行されている各インスタンスには、アクティブなデータのコピーが 1、2、または 3 つあります。 | Amazon DocumentDB は、書き込みクォーラムが 4 のコンピューティングインスタンスの数に関係なく、データの 6 つのコピーを保持し、true のままにします。ストレージレイヤーがデータのコピーを 4 つ保持すると、クライアントは確認を受け取ります。 |
| 整合性 | K/V オペレーションの即時整合性がサポートされています。Couchbase SDK は、データのアクティブなコピーを含む特定のインスタンスに K/V リクエストをルーティングするため、更新が確認されると、クライアントはその更新を読み取ることが保証されます。他のサービス (インデックス、検索、分析、イベント) への更新のレプリケーションは、結果整合性があります。 | Amazon DocumentDB レプリカは結果整合性があります。即時整合性読み取りが必要な場合、クライアントはプライマリインスタンスから読み取ることができます。 |
| レプリケーション | Cross-Data Center Replication (XDCR) は、多対多トポロジでデータのフィルタリングされたアクティブ/パッシブ/アクティブ/アクティブレプリケーションを提供します。 | Amazon DocumentDB グローバルクラスターは、1:多 (最大 10) トポロジでアクティブ/パッシブレプリケーションを提供します。 |
発見
Amazon DocumentDB に移行するには、既存のデータベースワークロードを完全に理解する必要があります。ワークロード検出は、Couchbase クラスターの設定と、データセット、インデックス、ワークロードなどの運用特性を分析し、中断を最小限に抑えながらシームレスな移行を確保するプロセスです。
クラスターの設定
Couchbase は、各機能がサービスに対応するサービス中心のアーキテクチャを使用します。Couchbase クラスターに対して次のコマンドを実行して、どのサービスが使用されているかを判断します (「Getting Information on Nodes
curl -v -u <administrator>:<password> \ http://<ip-address-or-hostname>:<port>/pools/nodes | \ jq '[.nodes[].services[]] | unique'
サンプル出力:
[ "backup", "cbas", "eventing", "fts", "index", "kv", "n1ql" ]
Couchbase サービスには以下が含まれます。
データサービス (kv)
データサービスは、メモリとディスクのデータへの読み取り/書き込みアクセスを提供します。
Amazon DocumentDB は、MongoDB API を介した JSON データに対する K/V オペレーションをサポートしています。
クエリサービス (n1ql)
クエリサービスは、SQL++ を介した JSON データのクエリをサポートします。
Amazon DocumentDB は、MongoDB API を介した JSON データのクエリをサポートしています。
インデックスサービス (インデックス)
インデックスサービスは、データのインデックスを作成および維持し、クエリを高速化します。
Amazon DocumentDB は、デフォルトのプライマリインデックスと、MongoDB API を介した JSON データへのセカンダリインデックスの作成をサポートしています。
検索サービス (fts)
検索サービスは、全文検索のインデックスの作成をサポートしています。
Amazon DocumentDB のネイティブフルテキスト検索機能を使用すると、MongoDB API を介して特殊目的のテキストインデックスを使用して、大きなテキストデータセットに対してテキスト検索を実行できます。高度な検索のユースケースでは、Amazon DocumentDB ゼロ ETL と Amazon OpenSearch Service の統合
分析サービス (cbas)
分析サービスは、JSON データをほぼリアルタイムで分析することをサポートしています。
Amazon DocumentDB は、MongoDB API を介した JSON データに対するアドホッククエリをサポートしています。Amazon EMR でAmazon DocumentDB の JSON データに対して複雑なクエリを実行
イベントサービス (イベント)
イベントサービスは、データ変更に応じてユーザー定義のビジネスロジックを実行します。
Amazon DocumentDB は、Amazon DocumentDB クラスターでデータが変更されるたびに AWS Lambda 関数を呼び出すことで、イベント駆動型のワークロードを自動化します。
バックアップサービス (バックアップ)
バックアップサービスは、完全および増分データバックアップと以前のデータバックアップのマージをスケジュールします。
Amazon DocumentDB は、1~35 日間の保持期間でデータを Amazon S3 に継続的にバックアップするため、バックアップ保持期間内の任意の時点にすばやく復元できます。Amazon DocumentDB は、この継続的なバックアッププロセスの一環として、データの自動スナップショットも取得します。Amazon DocumentDB のバックアップと復元は、 を使用して管理することもできます AWS Backup。
運用特性
Discovery Tool for Couchbase
データセット
このツールは、次のバケット、スコープ、およびコレクション情報を取得します。
バケット名
バケットタイプ
スコープ名
コレクション名
合計サイズ (バイト)
合計項目数
項目サイズ (バイト)
インデックス
このツールは、すべてのバケットについて、次のインデックス統計とすべてのインデックス定義を取得します。Amazon DocumentDB は各コレクションのプライマリインデックスを自動的に作成するため、プライマリインデックスは除外されることに注意してください。
バケット名
スコープ名
コレクション名
インデックス名
インデックスサイズ (バイト)
ワークロード
このツールは、K/V および N1QL クエリメトリクスを取得します。K/V メトリクス値はバケットレベルで収集され、SQL++ メトリクスはクラスターレベルで収集されます。
ツールのコマンドラインオプションは次のとおりです。
python3 discovery.py \ --username <source cluster username> \ --password <source cluster password> \ --data_node <data node IP address or DNS name> \ --admin_port <administration http REST port> \ --kv_zoom <get bucket statistics for specified interval> \ --tools_path <full path to Couchbase tools> \ --index_metrics <gather index definitions and SQL++ metrics> \ --indexer_port <indexer service http REST port> \ --n1ql_start <start time for sampling> \ --n1ql_step <sample interval over the sample period>
コマンドの例を次に示します。
python3 discovery.py \ --username username \ --password ******** \ --data_node "http://10.0.0.1" \ --admin_port 8091 \ --kv_zoom week \ --tools_path "/opt/couchbase/bin" \ --index_metrics true \ --indexer_port 9102 \ --n1ql_start -60000 \ --n1ql_step 1000
K/V メトリクス値は、過去 1 週間の 10 分ごとのサンプルに基づきます (HTTP メソッドと URI
collection-stats.csv – バケット、スコープ、コレクション情報
bucket,bucket_type,scope_name,collection_name,total_size,total_items,document_size beer-sample,membase,_default,_default,2796956,7303,383 gamesim-sample,membase,_default,_default,114275,586,196 pillowfight,membase,_default,_default,1901907769,1000006,1902 travel-sample,membase,inventory,airport,547914,1968,279 travel-sample,membase,inventory,airline,117261,187,628 travel-sample,membase,inventory,route,13402503,24024,558 travel-sample,membase,inventory,landmark,3072746,4495,684 travel-sample,membase,inventory,hotel,4086989,917,4457 ...
index-stats.csv – インデックス名とサイズ
bucket,scope,collection,index-name,index-size beer-sample,_default,_default,beer_primary,468144 gamesim-sample,_default,_default,gamesim_primary,87081 travel-sample,inventory,airline,def_inventory_airline_primary,198290 travel-sample,inventory,airport,def_inventory_airport_airportname,513805 travel-sample,inventory,airport,def_inventory_airport_city,487289 travel-sample,inventory,airport,def_inventory_airport_faa,526343 travel-sample,inventory,airport,def_inventory_airport_primary,287475 travel-sample,inventory,hotel,def_inventory_hotel_city,497125 ...
kv-stats.csv – すべてのバケットのメトリクスを取得、設定、削除する
bucket,gets,sets,deletes beer-sample,0,0,0 gamesim-sample,0,0,0 pillowfight,369,521,194 travel-sample,0,0,0
n1ql-stats.csv – SQL++ クラスターのメトリクスを選択、削除、挿入する
selects,deletes,inserts 0,132,87
indexes-<bucket-name>.txt – バケット内のすべてのインデックスのインデックス定義。Amazon DocumentDB は各コレクションのプライマリインデックスを自動的に作成するため、プライマリインデックスは除外されることに注意してください。
CREATE INDEX `def_airportname` ON `travel-sample`(`airportname`) CREATE INDEX `def_city` ON `travel-sample`(`city`) CREATE INDEX `def_faa` ON `travel-sample`(`faa`) CREATE INDEX `def_icao` ON `travel-sample`(`icao`) CREATE INDEX `def_inventory_airport_city` ON `travel-sample`.`inventory`.`airport`(`city`) CREATE INDEX `def_inventory_airport_faa` ON `travel-sample`.`inventory`.`airport`(`faa`) CREATE INDEX `def_inventory_hotel_city` ON `travel-sample`.`inventory`.`hotel`(`city`) CREATE INDEX `def_inventory_landmark_city` ON `travel-sample`.`inventory`.`landmark`(`city`) CREATE INDEX `def_sourceairport` ON `travel-sample`(`sourceairport`) ...
計画
計画フェーズでは、Amazon DocumentDB クラスターの要件を決定し、Couchbase バケット、スコープ、コレクションを Amazon DocumentDB データベースとコレクションにマッピングします。
Amazon DocumentDB クラスターの要件
検出フェーズで収集されたデータを使用して、Amazon DocumentDB クラスターのサイズを設定します。Amazon DocumentDB クラスターのサイズ設定の詳細については、「インスタンスのサイズ設定」を参照してください。
バケット、スコープ、コレクションをデータベースとコレクションにマッピングする
Amazon DocumentDB クラスター (複数可) に存在するデータベースとコレクションを決定します。Couchbase クラスター内のデータの整理方法に応じて、次のオプションを検討してください。これらは唯一のオプションではありませんが、考慮すべき出発点となります。
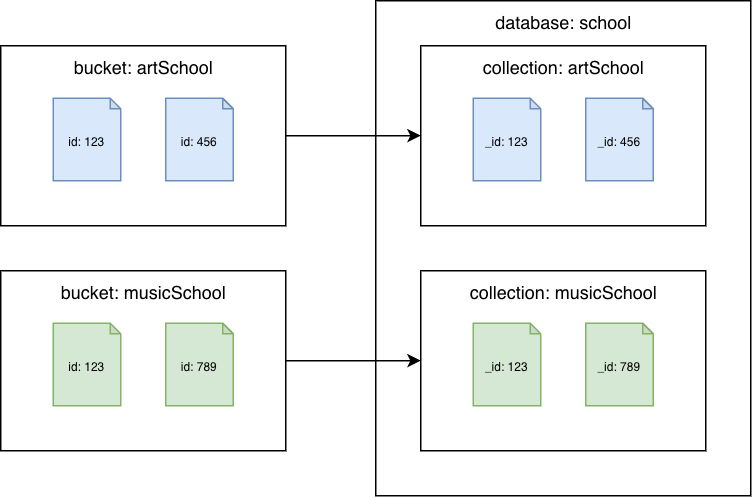
Couchbase Server 6.x 以前
Couchbase バケットから Amazon DocumentDB コレクションへ
各バケットを別の Amazon DocumentDB コレクションに移行します。このシナリオでは、Couchbase ドキュメントid値が Amazon DocumentDB _id値として使用されます。
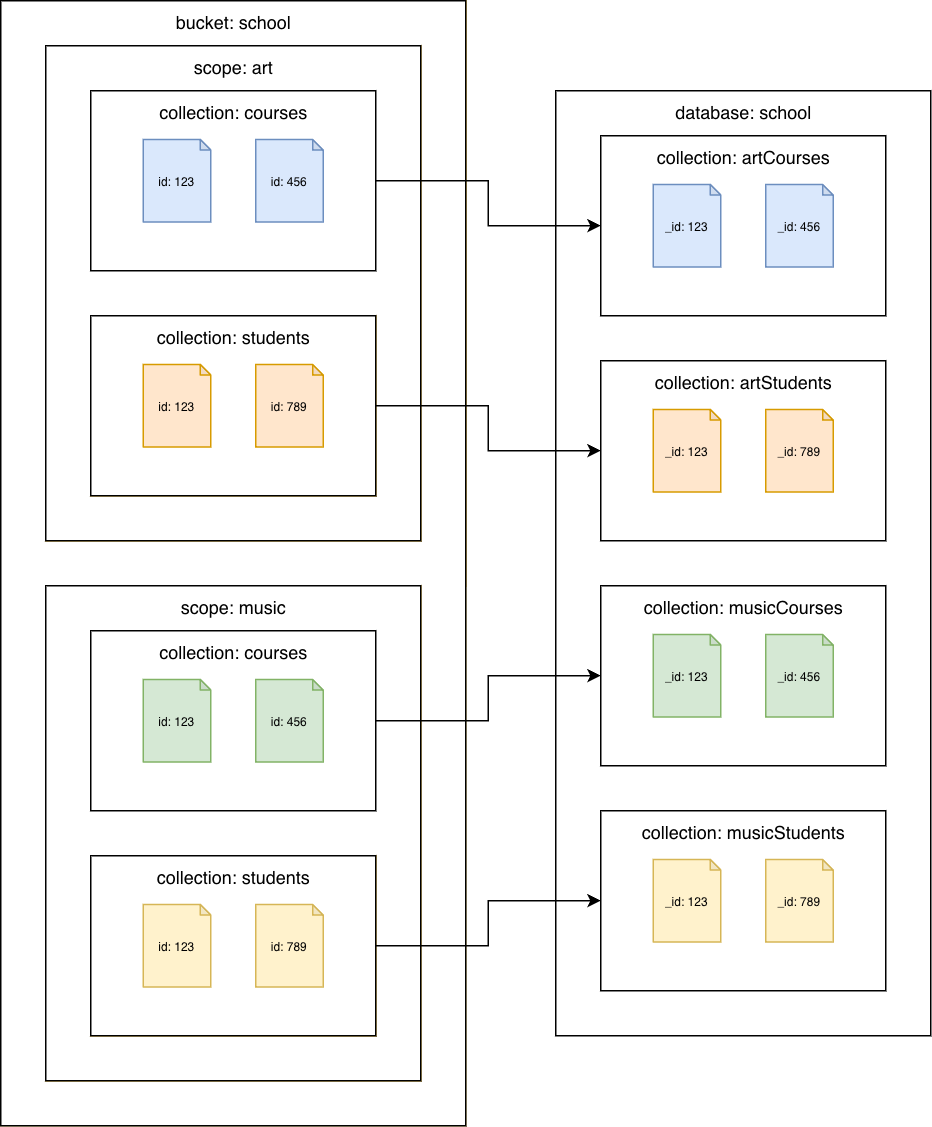
Couchbase Server 7.0 以降
Couchbase コレクションから Amazon DocumentDB コレクションへ
各コレクションを別の Amazon DocumentDB コレクションに移行します。このシナリオでは、Couchbase ドキュメントid値が Amazon DocumentDB _id値として使用されます。
移行
インデックスの移行
Amazon DocumentDB への移行には、データだけでなくインデックスも転送してクエリパフォーマンスを維持し、データベースオペレーションを最適化する必要があります。このセクションでは、互換性と効率を確保しながら Amazon DocumentDB にインデックスを移行するための詳細なstep-by-stepプロセスの概要を説明します。
Amazon Q を使用して、SQL++ CREATE INDEXステートメントを Amazon DocumentDB createIndex() コマンドに変換します。
Discovery Tool for Couchbase によって作成された indexes-<bucket name>.txt ファイル (複数可) をアップロードします。
次のプロンプトを入力します。
Convert the Couchbase CREATE INDEX statements to Amazon DocumentDB createIndex commands
Amazon Q は同等の Amazon DocumentDB createIndex() コマンドを生成します。Couchbase バケット、スコープ、コレクションを Amazon DocumentDB コレクションにマッピングする方法に基づいて、コレクション名を更新する必要がある場合があります。
例えば、次のようになります。
indexes-beer-sample.txt
CREATE INDEX `beerType` ON `beer-sample`(`type`) CREATE INDEX `code` ON `beer-sample`(`code`) WHERE (`type` = "brewery")
Amazon Q 出力の例 (抜粋):
db.beerSample.createIndex( { "type": 1 }, { "name": "beerType", "background": true } ) db.beerSample.createIndex( { "code": 1 }, { "name": "code", "background": true, "partialFilterExpression": { "type": "brewery" } } )
Amazon Q が変換できないインデックスの詳細については、Amazon DocumentDB インデックスとインデックスおよびインデックスプロパティの管理mongo-apis.html#mongo-apis-index」を参照してください。
MongoDB APIs を使用するためのリファクタリングコード
クライアントは Couchbase SDKs を使用して Couchbase Server に接続します。Amazon DocumentDB クライアントは、MongoDB ドライバーを使用して Amazon DocumentDB に接続します。Couchbase SDKs でサポートされているすべての言語は、MongoDB ドライバーでもサポートされています。言語のドライバーの詳細については、MongoDB
APIs は Couchbase Server と Amazon DocumentDB で異なるため、適切な MongoDB APIs を使用するようにコードをリファクタリングする必要があります。Amazon Q を使用して、K/V API コールと SQL++ クエリを同等の MongoDB APIsに変換できます。
ソースコードファイル (複数可) をアップロードします。
次のプロンプトを入力します。
Convert the Couchbase API code to Amazon DocumentDB API code
Hello Couchbase
from datetime import timedelta from pymongo import MongoClient # Connection parameters database_name = "travel-sample" # Connect to Amazon DocumentDB cluster client = MongoClient('<Amazon DocumentDB connection string>') # Get reference to database and collection db = client['travel-sample'] airline_collection = db['airline'] # upsert document function def upsert_document(doc): print("\nUpsert Result: ") try: # key will equal: "airline_8091" key = doc["type"] + "_" + str(doc["id"]) doc['_id'] = key # Amazon DocumentDB uses _id as primary key result = airline_collection.update_one( {'_id': key}, {'$set': doc}, upsert=True ) print(f"Modified count: {result.modified_count}") except Exception as e: print(e) # get document function def get_airline_by_key(key): print("\nGet Result: ") try: result = airline_collection.find_one({'_id': key}) print(result) except Exception as e: print(e) # query for document by callsign def lookup_by_callsign(cs): print("\nLookup Result: ") try: result = airline_collection.find( {'callsign': cs}, {'name': 1, '_id': 0} ) for doc in result: print(doc['name']) except Exception as e: print(e) # Test document airline = { "type": "airline", "id": 8091, "callsign": "CBS", "iata": None, "icao": None, "name": "Couchbase Airways", } upsert_document(airline) get_airline_by_key("airline_8091") lookup_by_callsign("CBS")
Python、Node.js、PHP、Go、Java、C#/ で Amazon DocumentDB に接続する例については、「プログラムによる Amazon DocumentDB への接続」を参照してください。NET、R、Ruby。
移行アプローチを選択する
Amazon DocumentDB にデータを移行する場合、次の 2 つのオプションがあります。
オフライン移行
次の場合は、オフライン移行を検討してください。
ダウンタイムは許容されます。オフライン移行では、ソースデータベースへの書き込みオペレーションを停止し、データをエクスポートしてから Amazon DocumentDB にインポートします。このプロセスでは、アプリケーションのダウンタイムが発生します。アプリケーションまたはワークロードがこの使用不能期間を許容できる場合、オフライン移行は実行可能なオプションです。
小規模なデータセットの移行または概念実証の実施: 小規模なデータセットの場合、エクスポートとインポートのプロセスに必要な時間は比較的短く、オフライン移行は迅速かつ簡単な方法です。また、ダウンタイムの重要性が低い開発、テスト、proof-of-concept環境にも適しています。
シンプルさが優先されます。cbexport と mongoimport を使用するオフラインメソッドは、一般的にデータを移行するための最も簡単なアプローチです。これにより、オンライン移行方法に伴う変更データキャプチャ (CDC) の複雑さを回避できます。
継続的な変更をレプリケートする必要はありません。移行中にソースデータベースが変更をアクティブに受信していない場合、または移行プロセス中にそれらの変更をキャプチャしてターゲットに適用することが重要でない場合は、オフラインアプローチが適切です。
Couchbase Server 6.x 以前
Couchbase バケットから Amazon DocumentDB コレクションへ
cbexport json --format オプションには、 linesまたは を使用できますlist。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
mongoimport と適切なオプションを使用して Amazon DocumentDB コレクションにデータをインポートし、行またはリストをインポートします。
行:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
リスト:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase Server 7.0 以降
オフライン移行を実行するには、cbexport ツールと mongoimport ツールを使用します。
デフォルトのスコープとデフォルトのコレクションを持つ Couchbase バケット
cbexport json --format オプションには、 linesまたは を使用できますlist。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id
mongoimport と適切なオプションを使用して Amazon DocumentDB コレクションにデータをインポートし、行またはリストをインポートします。
行:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
リスト:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
Couchbase コレクションから Amazon DocumentDB コレクションへ
cbexport json --include-data オプションを使用して、各コレクションをエクスポートします。--format オプションには、 linesまたは を使用できますlist。--scope-field および --collection-fieldオプションを使用して、スコープとコレクションの名前を各 JSON ドキュメントの指定されたフィールドに保存します。
cbexport json \ --cluster <source cluster endpoint> \ --bucket <bucket name> \ --include-data <scope name>.<collection name> \ --format <lines | list> \ --username <username> \ --password <password> \ --output export.json \ --include-key _id \ --scope-field "_scope" \ --collection-field "_collection"
cbexport はエクスポートされたすべてのドキュメントに _scopeおよび _collectionフィールドを追加したため、検索および置換、sed、または任意の方法でエクスポートファイル内のすべてのドキュメントから削除できます。
mongoimport と行またはリストをインポートする適切なオプションを使用して、各コレクションのデータを Amazon DocumentDB コレクションにインポートします。
行:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --file export.json
リスト:
mongoimport \ --db <database> \ --collection <collection> \ --uri "<Amazon DocumentDB cluster connection string>" \ --jsonArray \ --file export.json
オンライン移行
ダウンタイムを最小限に抑え、継続的な変更をほぼリアルタイムで Amazon DocumentDB にレプリケートする必要がある場合は、オンライン移行を検討してください。
Amazon Amazon DocumentDB へのライブ移行を実行する方法については、「Couchbase から Amazon
Couchbase Server 6.x 以前
Couchbase バケットから Amazon DocumentDB コレクションへ
Couchbase の移行ユーティリティdocument.id.strategyパラメータはメッセージキー値を_idフィールド値として使用するように設定されています (「シンクコネクタ ID Strategy Properties
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase Server 7.0 以降
デフォルトのスコープとデフォルトのコレクションを持つ Couchbase バケット
Couchbase の移行ユーティリティdocument.id.strategyパラメータはメッセージキー値を_idフィールド値として使用するように設定されています (「シンクコネクタ ID Strategy Properties
ConnectorConfiguration: document.id.strategy: 'com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy'
Couchbase コレクションから Amazon DocumentDB コレクションへ
各スコープ内の各 Couchbase コレクションを個別のトピックにストリーミングするようにソースコネクタ
ConnectorConfiguration: # add couchbase.collections configuration couchbase.collections: '<scope 1>.<collection 1>, <scope 1>.<collection 2>, ...'
各トピックから個別の Amazon DocumentDB コレクションにストリーミングするようにシンクコネクタ
ConnectorConfiguration: # remove collection configuration #collection: 'test' # modify topics configuration topics: '<bucket>.<scope 1>.<collection 1>, <bucket>.<scope 1>.<collection 2>, ...' # add topic.override.%s.%s configurations for each topic topic.override.<bucket>.<scope 1>.<collection 1>.collection: '<collection>' topic.override.<bucket>.<scope 1>.<collection 2>.collection: '<collection>'
検証
このセクションでは、Amazon DocumentDB に移行した後のデータ整合性と整合性を検証するための詳細な検証プロセスについて説明します。検証ステップは、移行方法に関係なく適用されます。
すべてのコレクションがターゲットに存在することを確認する
Couchbase ソース
オプション 1: クエリワークベンチ
SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'
オプション 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT RAW `path` FROM system:keyspaces WHERE `bucket` = '<bucket>'"
Amazon DocumentDB ターゲット
mongosh (Amazon DocumentDB クラスターに接続する」を参照):
db.getSiblingDB('<database>') db.getCollectionNames()
ソースクラスターとターゲットクラスター間のドキュメント数を検証する
Couchbase ソース
Couchbase Server 6.x 以前
オプション 1: クエリワークベンチ
SELECT COUNT(*) FROM `<bucket>`
オプション 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`"
Couchbase Server 7.0 以降
オプション 1: クエリワークベンチ
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
オプション 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB ターゲット
mongosh (Amazon DocumentDB クラスターに接続する」を参照):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').countDocuments()
ソースクラスターとターゲットクラスター間でドキュメントを比較する
Couchbase ソース
Couchbase Server 6.x 以前
オプション 1: クエリワークベンチ
SELECT META().id as _id, * FROM `<bucket>` LIMIT 5
オプション 2: cbq
cbq \ -e <source cluster endpoint> -u <username> \ -p <password> \ -q "SELECT META().id as _id, * FROM `<bucket>` \ LIMIT 5"
Couchbase Server 7.0 以降
オプション 1: クエリワークベンチ
SELECT COUNT(*) FROM `<bucket>`.`<scope>`.`<collection>`
オプション 2: cbq
cbq \ -e <source cluster endpoint> \ -u <username> \ -p <password> \ -q "SELECT COUNT(*) FROM `<bucket:>`.`<scope>`.`<collection>`"
Amazon DocumentDB ターゲット
mongosh (Amazon DocumentDB クラスターに接続する」を参照):
db = db.getSiblingDB('<database>') db.getCollection('<collection>').find({ _id: { $in: [ <_id 1>, <_id 2>, <_id 3>, <_id 4>, <_id 5> ] } })
