翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
JDBC スキーマの自動生成
Amazon DocumentDB はドキュメントデータベースであるため、テーブルとスキーマの概念はありません。ただし、Tableau などの BI ツールは、データベースがスキーマを提示することを期待します。具体的には、JDBC ドライバー接続でデータベース内のコレクションのスキーマを取得する必要がある場合は、データベース内のすべてのコレクションをポーリングします。ドライバーは、そのコレクションのスキーマのキャッシュバージョンがすでに存在するかどうかを判別します。キャッシュされたバージョンが存在しない場合は、ドキュメントのコレクションをサンプリングし、次の動作に基づいてスキーマを作成します。
スキーマ生成の制限
DocumentDB JDBC ドライバーは識別子の長さに 128 文字の制限を課しています。スキーマジェネレータは、生成された識別子 (テーブル名とカラム名) の長さを切り捨てて、その制限に適合するようにします。
スキャン方法のオプション
サンプリング動作は、接続文字列またはデータソースオプションを使用して変更できます。
-
scanMethod=<option>
-
random - (デフォルト) - サンプルドキュメントはランダムな順序で返されます。
-
idForward - サンプルドキュメントは ID の順序で返されます。
-
idReverse - サンプルドキュメントは id の逆の順序で返されます。
-
all - コレクション内のすべてのドキュメントをサンプリングします。
-
-
ScanLimit=<n> - サンプリングするドキュメントの数。値は正の整数である必要があります。デフォルト値は 1000 です。scanMethod が all に設定されている場合、このオプションは無視されます。
Amazon DocumentDB データ型
Amazon DocumentDB サーバーはいくつかの MongoDB データ型をサポートしています。サポートされているデータ型とそれに関連付けられた JDBC データ型を以下に示します。
| MongoDB データ型 | DocumentDB でサポートされています | JDBC データ型 |
|---|---|---|
| バイナリデータ | はい | VARBINARY |
| ブール値 | はい | BOOLEAN |
| Double | はい | DOUBLE |
| 32 ビット整数 | はい | INTEGER |
| 64 ビット整数 | はい | BIGINT |
| String | はい | VARCHAR |
| ObjectId | はい | VARCHAR |
| 日付 | 可能 | TIMESTAMP |
| Null | はい | VARCHAR |
| 正規表現 | はい | VARCHAR |
| タイムスタンプ | はい | VARCHAR |
| MinKey | はい | VARCHAR |
| MaxKey | はい | VARCHAR |
| オブジェクト | はい | 仮想テーブル |
| 配列 | はい | 仮想テーブル |
| Decimal128 | いいえ | DECIMAL |
| JavaScript | いいえ | VARCHAR |
| JavaScript (スコープ付き) | いいえ | VARCHAR |
| 未定義 | いいえ | VARCHAR |
| 記号 | いいえ | VARCHAR |
| dbPointer (4.0+) | いいえ | VARCHAR |
スカラードキュメントフィールドのマッピング
コレクションからドキュメントのサンプルをスキャンする場合、JDBC ドライバーは、コレクション内のサンプルを表す 1 つ以上のスキーマを作成します。一般に、ドキュメントのスカラーフィールドは、テーブルスキーマの列にマップされます。例えば、team というコレクションと 1 つのドキュメント { "_id" : "112233", "name" :
"Alastair", "age": 25 } の場合、これはスキーマにマップされます。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| team | チームID | VARCHAR | PK |
| team | 名前 | VARCHAR | |
| team | 年齢 | INTEGER |
データ型の競合プロモーション
サンプリングされたドキュメントをスキャンするときに、フィールドのデータ型がドキュメント間で一貫していない可能性があります。この場合、JDBC ドライバーは JDBC データ型を、サンプリングされたドキュメントのすべてのデータ型に適合する共通データ型に昇格します。
例:
{ "_id" : "112233", "name" : "Alastair", "age" : 25 } { "_id" : "112244", "name" : "Benjamin", "age" : "32" }
年齢 フィールドは、最初のドキュメントでは 32 ビット整数ですが、2 番目のドキュメントでは文字列です。ここで、JDBC ドライバーは JDBC データ型を VARCHAR に昇格させ、いずれかのデータ型を検出したときに処理します。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| team | チームID | VARCHAR | PK |
| team | 名前 | VARCHAR | |
| team | 年齢 | VARCHAR |
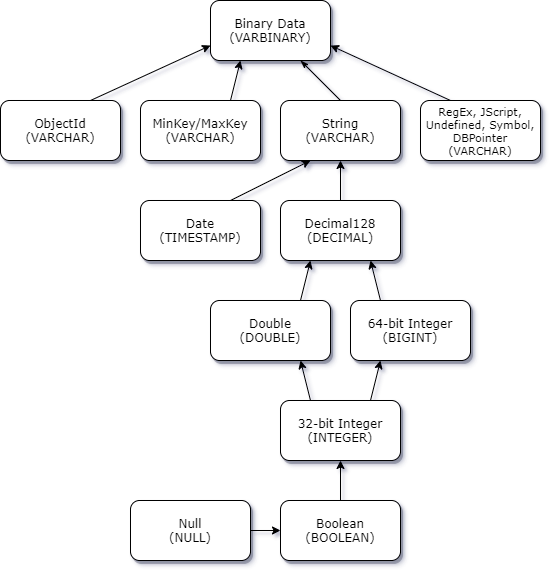
スカラー - スカラー競合プロモーション
次の図表は、スカラー - スカラーデータ型の競合を解決する方法を示しています。
スカラー - 複合型競合プロモーション
スカラー・スカラー型の競合と同様に、異なるドキュメント内の同じフィールドは、複素数(配列とオブジェクト)とスカラー(整数、ブールなど)の間で競合するデータ型を持つことができます。これらの競合はすべて、それらのフィールドについて VARCHAR に解決 (昇格) されます。この場合、配列とオブジェクトのデータは JSON 表現として返されます。
埋め込み配列 - 文字列フィールドの競合の例 :
{ "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] } { "_id":"112244", "name":"Joan Starr", "subscriptions":1 }
上記の例は、customer2 テーブルのスキーマにマッピングされています。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| customer2 | Customer2 ID | VARCHAR | PK |
| customer2 | 名前 | VARCHAR | |
| customer2 | サブスクリプション | VARCHAR |
customer1_subscriptions 仮想テーブルは次のとおりです。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| customer1_subscriptions | customer1 ID | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | 値 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | リージョン | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | コード | VARCHAR |
オブジェクトと配列のデータ型の処理
これまでは、スカラーデータ型のマッピング方法のみについて説明しました。オブジェクトデータ型と配列データ型は (現在) 仮想テーブルにマッピングされています。JDBC ドライバーは、ドキュメント内のオブジェクトまたは配列フィールドを表す仮想テーブルを作成します。マッピングされた仮想テーブルの名前は、元のコレクションの名前の後にフィールドの名前をアンダースコア (「_」) で区切って連結します。
ベーステーブルの主要なキー (「_id」) は、新しい仮想テーブル内の新しい名前を取得し、関連付けられたベーステーブルの外部キーとして提供されます。
埋め込み配列型フィールドの場合、配列の各レベルの配列へのインデックスを表すインデックス列が生成されます。
埋め込みオブジェクトフィールドの例
ドキュメント内のオブジェクトフィールドの場合、仮想テーブルへのマッピングは JDBC ドライバーによって作成されます。
{ "Collection: customer", "_id":"112233", "name":"George Jackson", "address":{ "address1":"123 Avenue Way", "address2":"Apt. 5", "city":"Hollywood", "region":"California", "country":"USA", "code":"90210" } }
上記の例は、customer テーブルのスキーマにマッピングされます。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| カスタマー | カスタマー ID | VARCHAR | PK |
| カスタマー | 名前 | VARCHAR |
および顧客アドレス仮想テーブルは次のとおりです。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| customer_address | カスタマー ID | VARCHAR | PK/FK |
| customer_address | address1 | VARCHAR | |
| customer_address | address2 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | リージョン | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | コード | VARCHAR |
埋め込み配列フィールドの例
ドキュメント内の配列フィールドの場合、JDBC ドライバーによって仮想テーブルへのマッピングも作成されます。
{ "Collection: customer1", "_id":"112233", "name":"George Jackson", "subscriptions":[ "Vogue", "People", "USA Today" ] }
上記の例は、customer1 テーブルのスキーマにマッピングします。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| customer1 | customer1 ID | VARCHAR | PK |
| customer1 | 名前 | VARCHAR |
customer1_subscriptions 仮想テーブルは次のとおりです。
| テーブル名 | Column Name (列名) | データタイプ | Key |
|---|---|---|---|
| customer1_subscriptions | customer1 ID | VARCHAR | PK/FK |
| customer1_subscriptions | subscriptions_index_lvl0 | BIGINT | PK |
| customer1_subscriptions | 値 | VARCHAR | |
| customer_address | city | VARCHAR | |
| customer_address | リージョン | VARCHAR | |
| customer_address | country | VARCHAR | |
| customer_address | コード | VARCHAR |
