翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
での同種データ移行による PostgreSQL データベースからのデータの移行 AWS DMS
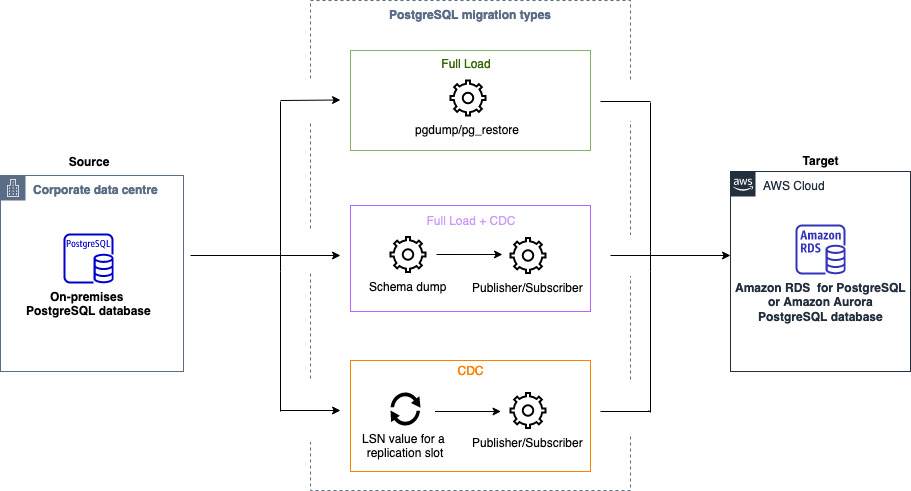
同種データ移行 を使用して、セルフマネージド型 PostgreSQL データベースを RDS for PostgreSQL または Aurora PostgreSQL に移行できます。 AWS DMS は、データ移行用のためのサーバーレス環境を作成します。 AWS DMS はさまざまなネイティブ PostgreSQL データベースツールを使用して、さまざまなタイプのデータ移行に対応します。
フルロードタイプの同種データ移行の場合、 は pg_dump AWS DMS を使用してソースデータベースからデータを読み取り、サーバーレス環境にアタッチされたディスクに保存します。がすべてのソースデータ AWS DMS を読み取ると、ターゲットデータベースの pg_restore を使用してデータを復元します。
Full Load and Change Data Capture (CDC) タイプの同種データ移行の場合、 AWS DMS を使用してソースデータベースからテーブルデータなしでスキーマオブジェクトpg_dumpを読み取り、サーバーレス環境にアタッチされたディスクに保存します。次に、ターゲットデータベースの pg_restore を使用してスキーマオブジェクトを復元します。がpg_restoreプロセス AWS DMS を完了すると、論理レプリケーション用のパブリッシャーモデルとサブスクライバーモデルに自動的に切り替わり、初期テーブルデータをソースデータベースからターゲットデータベースに直接Initial Data Synchronizationコピーし、継続的なレプリケーションを開始します。このモデルでは、単一または複数のサブスクライバーがパブリッシャノード上の単独または複数のパブリケーションにサブスクライブします。
変更データキャプチャ (CDC) タイプの同種データ移行の場合、レプリケーションを開始するにはネイティブ開始ポイント AWS DMS が必要です。ネイティブの開始点を指定すると、 はその時点からの変更を AWS DMS キャプチャします。または、データ移行設定で [すぐに] を選択すると、実際のデータ移行の開始時にレプリケーションの開始点を自動的にキャプチャできます。
注記
CDC のみの移行を正常に実行するには、ソースデータベースのすべてのスキーマとオブジェクトがターゲットデータベースに既に存在している必要があります。ただし、ターゲットにはソースには存在しないオブジェクトが含まれている場合があります。
次のコード例を使用すると、PostgreSQL データベースのネイティブ開始点を取得できます。
select confirmed_flush_lsn from pg_replication_slots where slot_name=‘migrate_to_target';
このクエリは、PostgreSQL データベースの pg_replication_slots ビューを使用してログシーケンス番号 (LSN) の値を取得します。
AWS DMS が PostgreSQL 同種データ移行のステータスを停止、失敗、または削除に設定した後、パブリッシャーとレプリケーションは削除されません。移行を再開しない場合は、次のコマンドを使用してレプリケーションスロットとパブリッシャーを削除します。
SELECT pg_drop_replication_slot('migration_subscriber_{ARN}'); DROP PUBLICATION publication_{ARN};
次の図は、 で同種データ移行を使用して PostgreSQL データベースを RDS for PostgreSQL または Aurora PostgreSQL AWS DMS に移行するプロセスを示しています。
同種データ移行のソースとしての PostgreSQL データベースの使用のベストプラクティス
FLCDC タスクのサブスクライバー側の初期データ同期を高速化するには、
max_logical_replication_workersとmax_sync_workers_per_subscriptionを調整する必要があります。これらの値を増加させると、テーブルの同期速度が向上します。max_logical_replication_workers – 論理レプリケーションワーカーの最大数を指定します。これには、サブスクライバー側の適用ワーカーとテーブル同期ワーカーの両方が含まれます。
max_sync_workers_per_subscription –
max_sync_workers_per_subscriptionを増加させると、テーブルあたりのワーカー数ではなく、並列に同期されているテーブルの数にのみ影響があります。
注記
max_logical_replication_workersはmax_worker_processesを超えず、max_sync_workers_per_subscriptionはmax_logical_replication_workers以下である必要があります。大きなテーブルを移行する場合、選択ルールを使用して別々のタスクに分割することを検討してください。例えば、大きなテーブルを個別のタスクに分割し、小さなテーブルを別の単一のタスクに分割できます。
サブスクライバー側のディスクと CPU の使用率をモニタリングして、最適なパフォーマンスを維持します。
