AWS Data Pipeline は新規顧客には利用できなくなりました。の既存のお客様は、通常どおりサービスを AWS Data Pipeline 引き続き使用できます。詳細はこちら
翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
コマンドラインを使用してクラスターを起動する
Amazon EMR クラスターを定期的に実行してウェブログを分析したり、科学データを分析したりする場合は、 AWS Data Pipeline を使用して Amazon EMR クラスターを管理できます。では AWS Data Pipeline、クラスターの起動前に満たす必要がある前提条件を指定できます (例えば、今日のデータが Amazon S3 にアップロードされていることを確認するなど)。このチュートリアルでは、シンプルな Amazon EMR ベースのパイプラインまたはより複雑なパイプラインの一部のモデルとなる、クラスターの起動について順を追って説明します。
前提条件
CLI を使用するには、事前に次のステップを完了しておく必要があります。
-
コマンドラインインターフェイス (CLI) をインストールして設定します。詳細については、「アクセス AWS Data Pipeline」を参照してください。
-
DataPipelineDefaultRole と DataPipelineDefaultResourceRole という名前の IAM ロールが存在していることを確認します。 AWS Data Pipeline コンソールでは、これらのロールが自動的に作成されます。 AWS Data Pipeline コンソールを一度も使用していない場合は、これらのロールを手動で作成する必要があります。詳細については、「の IAM ロール AWS Data Pipeline」を参照してください。
パイプライン定義ファイルの作成
次のコードは、Amazon EMR で提供される既存の Hadoop ストリーミングジョブを実行する、単純な Amazon EMR クラスターのパイプライン定義ファイルです。このサンプルアプリケーションは、WordCount と呼ばれ、Amazon EMR コンソールを使用して実行することもできます。
このコードをテキストファイルにコピーし、MyEmrPipelineDefinition.json として保存します。Amazon S3 バケットの場所は、所有している Amazon S3 バケットの名前に置き換える必要があります。また、開始日および終了日も置き換える必要があります。クラスターをすぐに起動するには、 startDateTimeを 1 日前の日付endDateTimeに設定し、1 日後の日付に設定します。 AWS Data Pipeline その後、 は、作業のバックログとして認識するものに対処しようとして、「期限を過ぎた」クラスターをすぐに起動します。このバックフィルは、最初のクラスターの AWS Data Pipeline 起動を 1 時間待つ必要がないことを意味します。
{ "objects": [ { "id": "Hourly", "type": "Schedule", "startDateTime": "2012-11-19T07:48:00", "endDateTime": "2012-11-21T07:48:00", "period": "1 hours" }, { "id": "MyCluster", "type": "EmrCluster", "masterInstanceType": "m1.small", "schedule": { "ref": "Hourly" } }, { "id": "MyEmrActivity", "type": "EmrActivity", "schedule": { "ref": "Hourly" }, "runsOn": { "ref": "MyCluster" }, "step": "/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,s3n://elasticmapreduce/samples/wordcount/input,-output,s3://myawsbucket/wordcount/output/#{@scheduledStartTime},-mapper,s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate" } ] }
このパイプラインには 3 個のオブジェクトがあります。
-
Hourly。作業のスケジュールを表します。アクティビティのフィールドの 1 つとしてスケジュールを設定できます。スケジュールを設定すると、アクティビティはそのスケジュールに従って(この例では 1 時間ごとに)実行されます。 -
MyCluster。クラスターの実行に使用される一連の Amazon EC2 インスタンスを表します。クラスターとして実行する EC2 インスタンスのサイズと数を指定できます。インスタンスの数を指定しなかった場合、クラスターはマスターノードとタスクノードの 2 つを使用して起動されます。クラスターを起動するサブネットも指定できます。Amazon EMR で提供された AMI に追加ソフトウェアをロードするブートストラップアクションなど、クラスターに追加設定を追加できます。 -
MyEmrActivity。クラスタで処理する計算を表します。Amazon EMR では、ストリーミング、カスケード、スクリプト化された Hive など、複数のタイプのクラスターがサポートされています。runsOnフィールドは MyCluster を参照し、それをクラスターの基盤の指定として使用します。
パイプライン定義のアップロードとアクティブ化
パイプライン定義をアップロードし、パイプラインをアクティブ化する必要があります。以下のコマンド例では、pipeline_name をパイプラインのラベルに置き換え、pipeline_file をパイプライン定義 .json ファイルの完全修飾パスに置き換えます。
AWS CLI
パイプライン定義を作成してパイプラインをアクティブ化するには、以下の create-pipeline コマンドを使用します。パイプラインの ID をメモします。この値は、ほとんどの CLI コマンドで使用するからです。
aws datapipeline create-pipeline --name{ "pipelineId": "df-00627471SOVYZEXAMPLE" }pipeline_name--unique-idtoken
パイプライン定義を更新するには、以下の put-pipeline-definition コマンドを使用します。
aws datapipeline put-pipeline-definition --pipeline-id df-00627471SOVYZEXAMPLE --pipeline-definition file://MyEmrPipelineDefinition.json
パイプラインが正常に検証された場合、validationErrors フィールドは空です。警告を確認する必要があります。
パイプラインをアクティブ化するには、以下の activate-pipeline コマンドを使用します。
aws datapipeline activate-pipeline --pipeline-id df-00627471SOVYZEXAMPLE
以下の list-pipelines コマンドを使用して、パイプラインリストにパイプラインが表示されていることを確認できます。
aws datapipeline list-pipelines
パイプライン実行の監視
Amazon EMR コンソール AWS Data Pipeline を使用して起動したクラスターを表示でき、Amazon S3 コンソールを使用して出力フォルダを表示できます。
によって起動されたクラスターの進行状況を確認するには AWS Data Pipeline
-
Amazon EMR コンソールを開きます。
-
によって生成されたクラスター AWS Data Pipeline の名前の形式は
<pipeline-identifier>_@<emr-cluster-name>_<launch-time>です。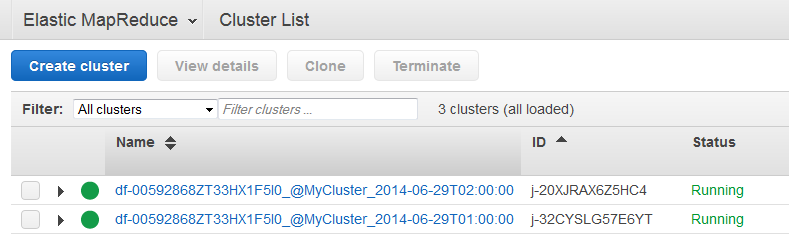
-
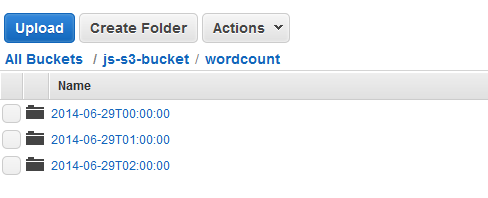
いずれかの実行が完了した後、Amazon S3 コンソールを開いて、タイムスタンプ付きの出力フォルダーがあり、クラスターの結果が予想したとおり含まれていることを確認します。