翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
変換用のブループリントを作成する
BDA を使用すると、特定の要件に応じてデータフィールドを分割したり再構築したりできます。この機能を使用すると、抽出されたデータを下流システムや分析ニーズにより適した形式に変換できます。
多くの場合、ドキュメントには複数の情報を単一のフィールドにまとめたフィールドが含まれている場合があります。BDA を使用すると、データの操作と分析を容易にするために、これらのフィールドを個別のフィールドに分割できます。例えば、ドキュメントに人物の名前が単一のフィールドとして含まれている場合、名前、ミドルネーム、姓、サフィックスを別々のフィールドに分割できます。
変換タスクでは、値の正規化が必要かどうかに応じて、抽出タイプを明示的または推論として定義できます。
| フィールド | 手順 | 抽出タイプ | タイプ |
|---|---|---|---|
|
FIRST_NAME |
名 |
明示的 |
String |
|
MIDDLE_NAME |
ミドルネームまたはイニシャル |
明示的 |
String |
|
LAST_NAME |
ドライバーの名前 |
明示的 |
String |
|
SUFFIX |
PhD、MSc などのサフィックス |
明示的 |
String |
もう 1 つの例として、単一のフィールドとして表示できるアドレスブロックがあります。
| フィールド | 手順 | 抽出タイプ | タイプ |
|---|---|---|---|
|
通り |
住所は何ですか。 |
明示的 |
String |
|
City |
都市は何ですか。 |
明示的 |
String |
|
State |
県または州は何ですか。 |
明示的 |
String |
|
ZipCode |
住所の郵便番号は何ですか。 |
明示的 |
String |
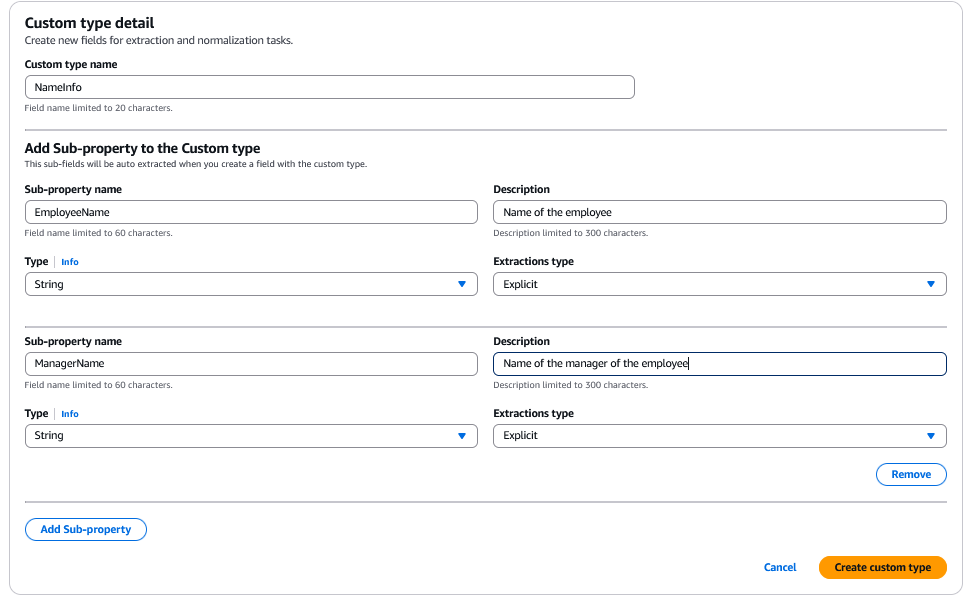
これらのフィールドは、完全に個別のフィールドとして定義することも、カスタムタイプを作成することもできます。カスタムタイプは、さまざまなフィールドで再利用できます。以下の例では、「EmployeeName」と「ManagerName」に使用するカスタムタイプ「NameInfo」を作成します。