翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
グラウンドトゥルースでブループリントを最適化する
サンプルコンテンツアセットに正しい期待される結果を提供することで、ブループリントの精度を向上させることができます。ブループリント命令の最適化では、例を使用してブループリントフィールドの自然言語命令を絞り込むため、推論結果の精度が向上します。
設計図命令の最適化は、請求書番号、契約金額、税フォームフィールドなど、ドキュメントに直接表示される特定の値を抽出する必要がある場合に最適です。本番環境で処理するドキュメント、特に精度の問題が発生したドキュメントを表すアセットの例を 3~10 個提供することをお勧めします。
ブループリント命令の最適化の仕組み
設計図命令の最適化は、期待される結果と最初の推論結果の違いを分析します。このサービスは、サンプルアセット全体でより正確な結果が得られるまで、ブループリントの各フィールドの自然言語の手順を繰り返し調整します。このプロセスは、モデルトレーニングや微調整を必要とせずに数分で完了します。
最適化プロセスを開始するときは、サンプルアセットとそれに対応するグラウンドトゥルースデータ、つまり各フィールドに対して抽出する予定の正しい値を指定します。設計図命令の最適化は、これらの値を推論結果と比較し、精度を向上させるためにフィールドの説明を調整します。最適化が完了すると、完全一致率やグラウンドトゥルースに対して測定された F1 スコアなど、精度の向上を示す精度メトリクスを受け取ります。
ブループリントの最適化を開始する前に必要なもの
フィールドが定義された設計図。コンソールまたは API を使用してブループリントを作成します。ブループリントには、抽出するデータのフィールド名と初期説明が含まれている必要があります。
コンテンツアセットの例。ドキュメントの本番ワークロードを表す 3~10 個のドキュメントアセットを収集します。ブループリントのすべてのフィールドを含む例を選択します。
例で期待される結果。各サンプルアセットから抽出する正しい値を準備します。これらの値は、最適化中に手動で入力することも、マニフェストファイルを使用してアップロードすることもできます。
S3 バケットの場所。サンプルアセットとグラウンドトゥルースデータを保存する S3 バケットを指定します。独自のバケットを指定するか、サービスにバケットの作成を許可できます。
ブループリントを最適化するStep-by-stepのプロセス
ブループリントを最適化するには、Amazon Bedrock Data Automation コンソールのブループリントの詳細ページから開始します。これはドキュメントモダリティでのみ使用できることに注意してください。
ステップ 1. 最適化設計図を選択して、最適化ワークフローを開始します。

ステップ 2. サンプルアセットをアップロードします。ローカルデバイスまたは S3 の場所から最大 10 個のコンテンツアセットを選択します。サービスはアセットをアップロードし、各ファイルのサムネイルを表示します。以前にこのブループリントを最適化した場合は、新しい例を追加したり、既存の例を削除したりできます。
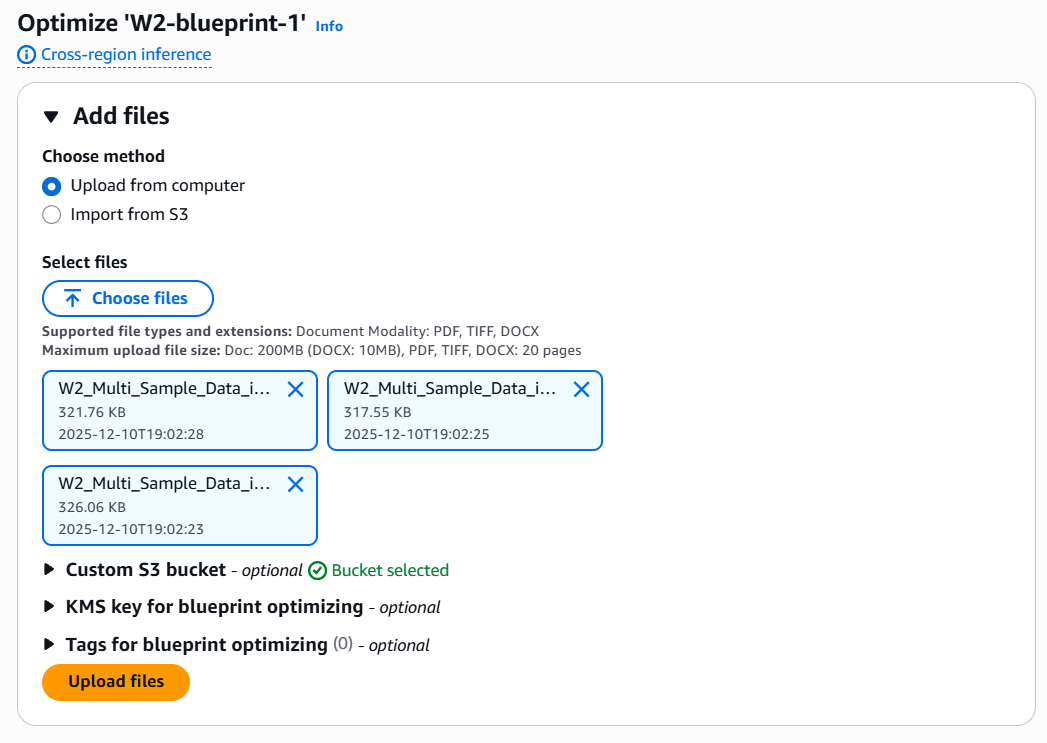
ステップ 3. 各アセットのグラウンドトゥルースを提供します。アセットを選択してグラウンドトゥルースエディタを開きます。エディタには、ドキュメントプレビューが左側に表示され、ブループリントフィールドの簡易テーブルが右側に表示されます。各フィールドに、Ground Truth 列に抽出する予定の正しい値を入力します。
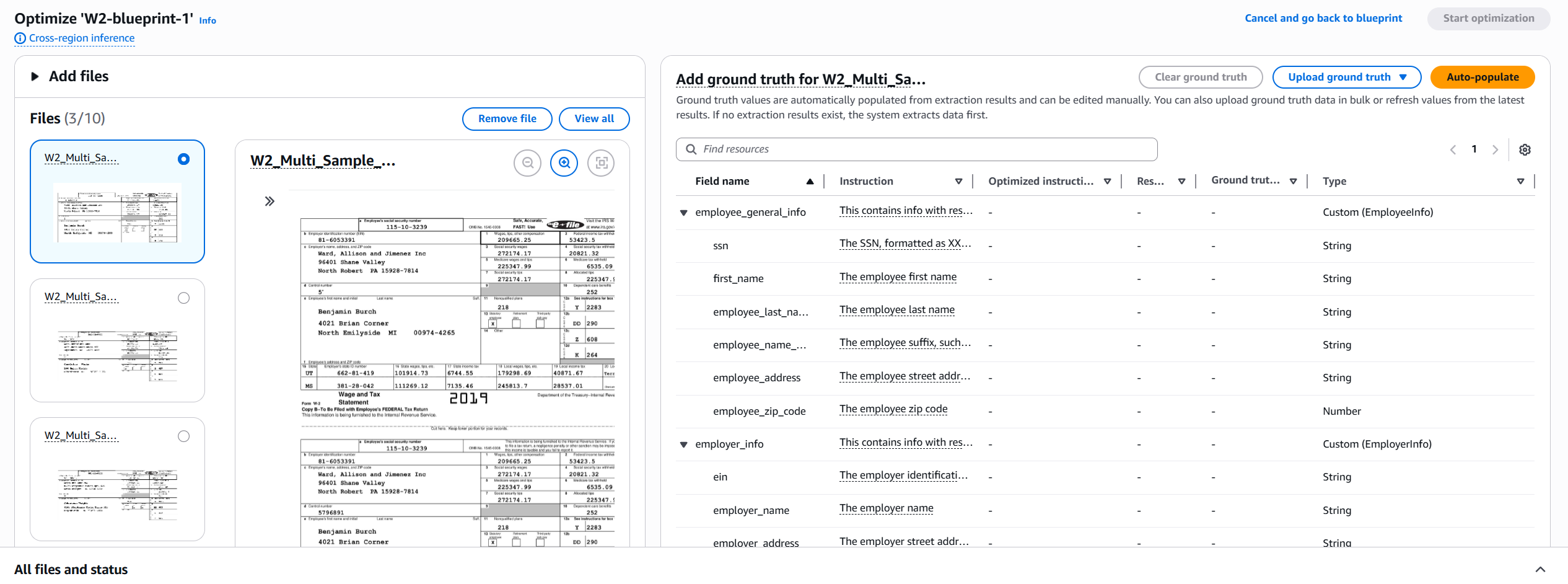
ステップ 4. グラウンドトゥルースエントリを高速化するには、自動入力を選択してアセットの初期推論を実行し、結果列の値から Ground Truth 列を自動的に入力します。先に進む前に、誤った値を編集してください。
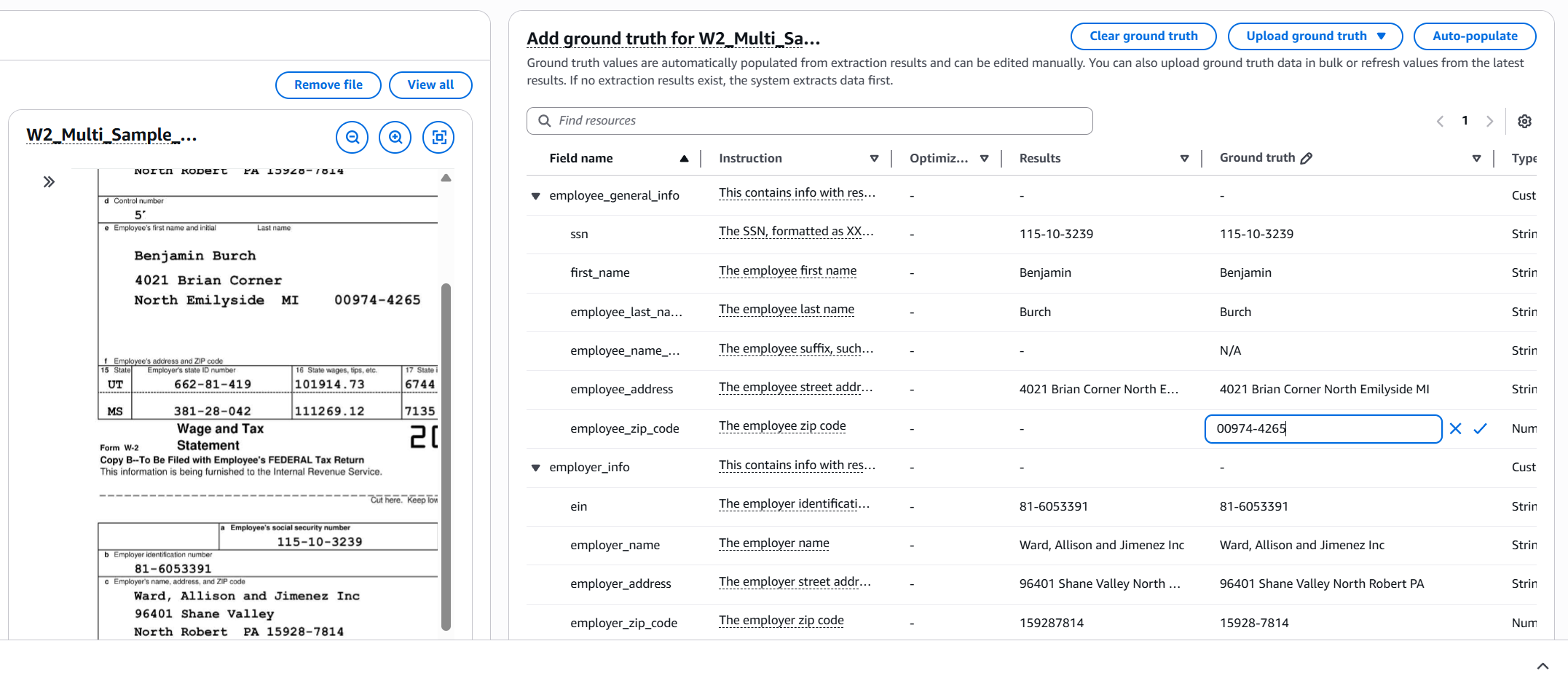
ステップ 5. 最適化を開始します。選択したすべてのアセットのグラウンドトゥルースエントリを完了したら、最適化の開始を選択します。データ自動化は、例を分析し、各フィールドの自然言語の手順を調整します。進行状況インジケータには、「アセットの読み取り」や「ブループリントの自然言語指示の変更」などのメッセージで最適化ステータスが表示されます。
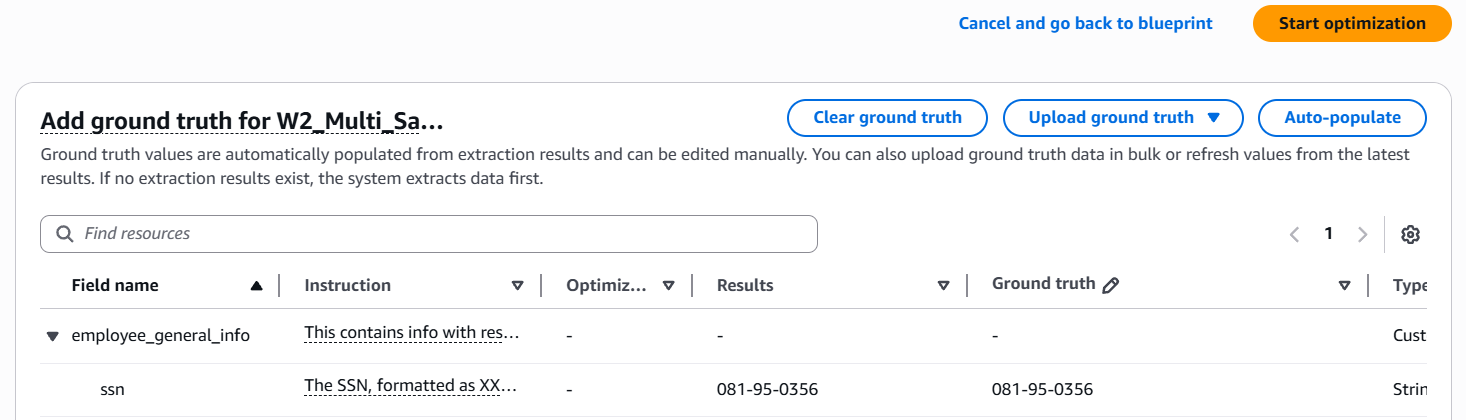
ステップ 6. 評価メトリクスを確認します。最適化が完了すると、メトリクスセクションにブループリントの精度メトリクスが表示されます。メトリクスは、最適化前と最適化後のパフォーマンスを比較します。全体的な F1 スコア、信頼スコア、完全一致率を確認して、設計図が精度要件を満たしているかどうかを評価します。
サンプルファイル別のメトリクスタブには、各サンプルアセットのフィールドレベルの精度が表示されます。これらのメトリクスを使用して、改善されたフィールドと、追加の例や手動調整が必要なフィールドを特定します。
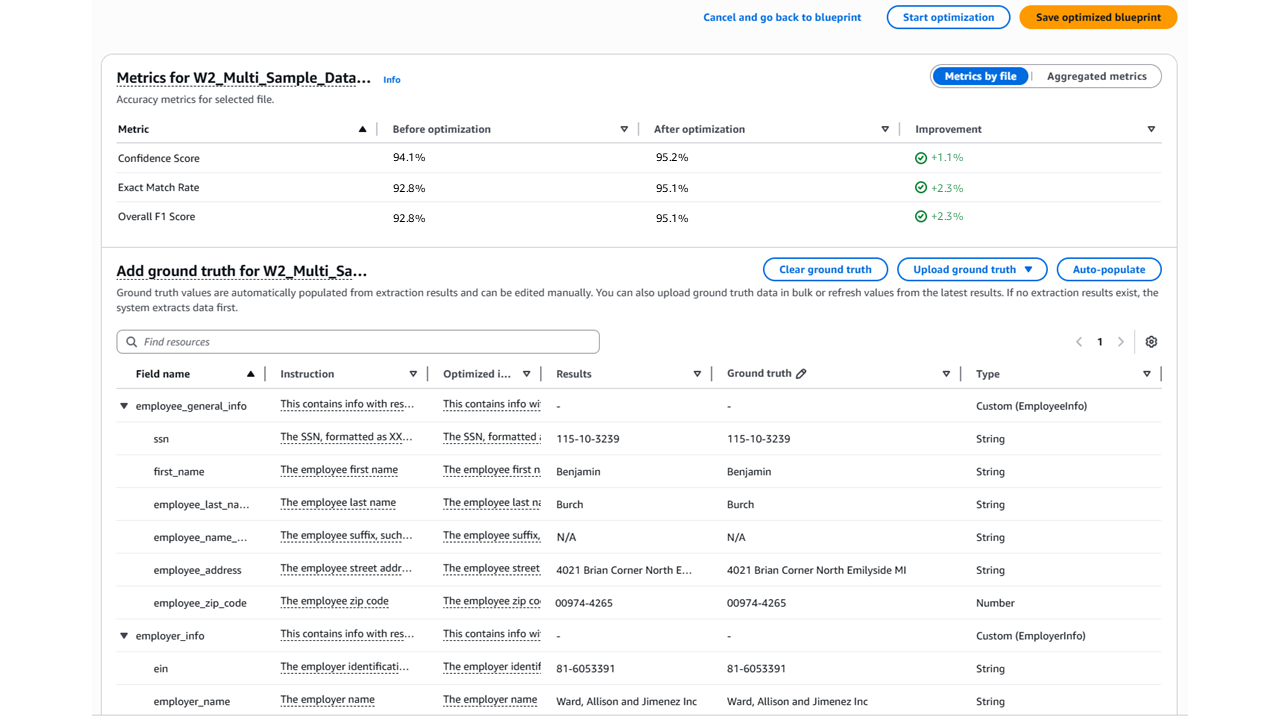
ステップ 7. 最適化を完了します。評価メトリクスが要件を満たしている場合は、最適化されたブループリントを保存を選択して、最適化されたブループリントを本番環境に昇格させます。ブループリントでは、今後のすべての推論リクエストに対して、洗練された自然言語の手順を使用するようになりました。
ブループリントの再最適化
ブループリントは、精度をさらに向上させるためにいつでも再最適化できます。ブループリントの詳細ページに戻り、ブループリントの最適化を選択します。サービスには、以前に最適化に使用したアセットとグラウンドトゥルース値が表示されます。
再最適化するには、新しいサンプルアセットを追加したり、既存のアセットのグラウンドトゥルース値を編集したり、ワークロードを表しなくなったアセットを削除したりできます。最適化の開始を選択すると、ブループリント命令の最適化は、現在のブループリント命令と新しい命令を基準にして計算されます。
最適化後にブループリントを編集する
最適化ブループリントからフィールドを追加または削除すると、サービスは最適化履歴と関連するサンプルアセットを削除します。編集する前に、アセットの場所とグラウンドトゥルースラベルを含むマニフェストファイルをダウンロードします。マニフェストファイルは JSON 形式を使用し、以前の最適化のすべてのフィールドとグラウンドトゥルース値が含まれます。最適化作業を維持するには、編集したブループリントを再最適化するときにマニフェストファイルをアップロードします。データ自動化は、グラウンドトゥルース値を一致するフィールドに自動的に適用します。ブループリントに存在しなくなったフィールドはマニフェストから削除されます。新しいフィールドには、入力するまでグラウンドトゥルース値はありません。
最適化コストを管理する
ブループリント命令の最適化では、自然言語命令を手動で編集し、各サンプルドキュメントに対して繰り返しテストする場合と同様に、推論コストが発生します。大まかな計算では、例として指定するページ数は、ブループリントを最適化するときに課金されるページ数になります。最適化を実行するたびに、サンプルアセットが複数回処理され、手順が絞り込まれます。コストを最小限に抑えるには、初期最適化の例を 3~5 つから始めます。評価メトリクスを検査し、精度をさらに改善する必要があると思われる場合は、さらに例を追加します。
さらに、最適化された自然言語命令は元の命令よりも長く、より詳細になる傾向があり、ランタイム推論コストが増加する可能性があります。
