翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
ブループリント
ブループリント設は、ファイル処理のビジネスロジックの設定に使用できるアーティファクトです。各ブループリントは、抽出できるフィールド名のリスト、フィールドの応答を抽出する際のデータ形式 (文字列、数値、ブール値など)、およびデータの正規化と検証ルールを指定するために使用できる各フィールドの自然言語コンテキストで構成されます。W2、給与明細、ID カードなど、処理するファイルのクラスごとにブループリントを作成できます。ブループリントは、コンソールまたは API を使用して作成できます。作成する各ブループリントは、独自のブループリント ID と ARN を持つ AWS リソースです。
抽出にブループリントを使用する場合は、カタログブループリントまたはカスタム作成されたブループリントを使用できます。抽出元のファイルの種類が既にわかっている場合は、カタログブループリントがあらかじめ用意されている開始点になります。カタログにないファイルのカスタムブループリントを作成できます。ブループリントを作成するときは、ブループリントプロンプトからブループリントを生成したり、個々のフィールドを追加して手動で作成したり、JSON エディタを使用してブループリントの JSON を作成したりするなど、いくつかの方法を使用できます。これらはアカウントに保存して共有できます。
注記
オーディオブループリントは、ブループリントプロンプトでは作成できません。
ブループリントの最大サイズは 100,000 文字で、JSON 形式です。InvokeDataAutomationAsync API で使用する設計図の場合、設計図あたりの最大フィールド数は 100 です。InvokeDataAutomation API で使用する設計図の場合、設計図あたりの最大フィールド数は 15 です。
注記
ブループリントを使用する場合、フィールド内またはブループリントの作成でプロンプトを使用することがあります。信頼できるソースのみがプロンプト入力を制御できるようにします。 Amazon Bedrock は、ブループリントのインテントを検証する責任を負いません。
ブループリントのチュートリアル
パスポートなどの ID 文書を例に、この文書のブループリントを確認していきましょう。

コンソールで作成したこの ID 文書のブループリントの例を次に示します。
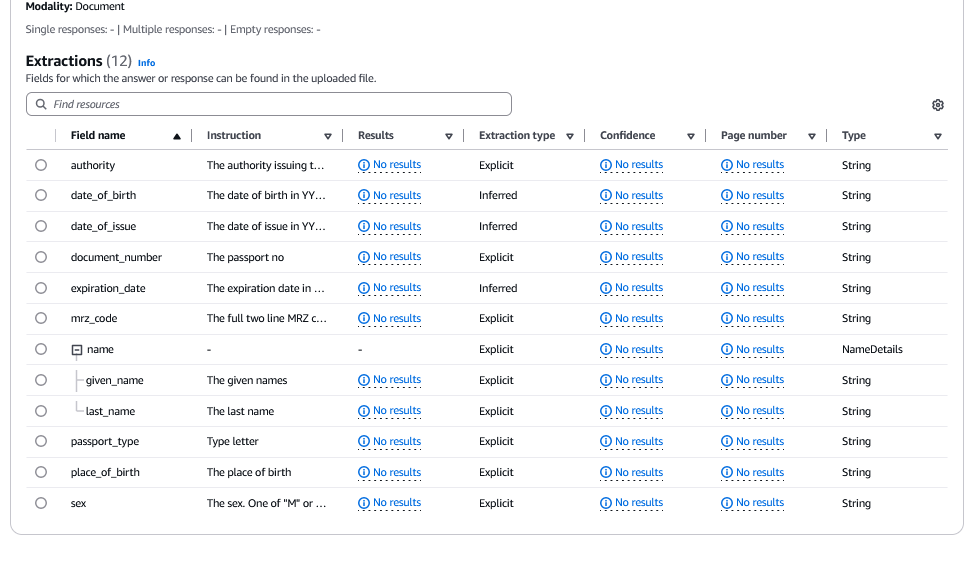
本質的に、ブループリントはフィールドを含むデータ構造であり、そのフィールドには BDA カスタム出力によって抽出された情報が含まれます。抽出テーブルには、2 種類のフィールド (明示的なものと暗黙的なもの) があります。明示的な抽出は、文書で確認できる明記された情報に使用されます。暗黙的な抽出は、文書に表示される方法から変換する必要がある情報に使用されます。例えば、社会保障番号からダッシュを削除して、111-22-3333 から 111223333 に変換する場合などが考えられます。フィールドには、特定の基本コンポーネントが含まれます。
-
フィールド名: ドキュメントから抽出する各フィールドに対して指定できる名前です。
Place_BirthやPlace_of_birthなど、ダウンストリームシステムのフィールドに使用する名前を使用できます。フィールド名にスラッシュ (/) を含めることはできません。代わりにアンダースコアまたは英数字を使用します。 -
説明: ブループリントの各フィールドに自然言語コンテキストを提供して、従うべきデータの正規化ルールまたは検証ルールを記述する入力です。例えば、
Date of birth in YYYY-MM-DD format、Is the year of birth before 1992?です。ブループリントで繰り返し、BDA の応答の精度を高める方法としてもプロンプトを使用できます。必要なフィールドを説明する詳細なプロンプトを提供すると、基礎となるモデルの精度が向上します。プロンプトは最大 300 文字まで可能です。 -
結果: プロンプトとフィールド名に基づいて BDA により抽出される情報。
-
タイプ: フィールドの応答で使用するデータ形式。文字列、数値、ブール値、文字列の配列、数値の配列をサポートしています。
-
信頼スコア: 抽出が正確であるという BDA の確実性の割合。オーディオおよびイメージの設計図は信頼スコアを返しません。
-
抽出タイプ: 抽出のタイプで、明示的なものか推測されたものになります。
-
ページ番号: 結果が見つかった文書のページ。オーディオブループリントと動画ブループリントはページ番号を返しません。
BDA カスタム出力では、単純なフィールドに加えて、テーブルフィールド、グループ、カスタムタイプなど、ドキュメント抽出で発生する可能性のあるユースケースに対応するオプションがいくつか提供されます。
テーブルフィールド
フィールドを作成するときは、基本フィールドの代わりにテーブルフィールドを作成できます。他のフィールドと同様に、フィールドに名前を付けて、プロンプトを指定できます。列フィールドを指定することもできます。これらのフィールドには、列名、列の説明、および列タイプがあります。抽出テーブルに表示される場合、テーブルフィールドにはテーブル名の下にグループ化された列の結果が含まれます。テーブルフィールドには、最大 15 個のサブフィールドのみを含めることができます。
グループ
グループは、複数の結果を抽出内の 1 つの場所に整理するために使用される構造です。グループを作成するときは、グループに名前を付け、フィールドを作成してそのグループに配置できます。このグループは抽出テーブルでマークされ、その下にはグループ内のフィールドが一覧表示されます。
カスタムタイプ
ブループリントプレイグラウンドでブループリントを編集するときに、カスタムタイプを作成できます。どのフィールドもカスタムタイプにできます。このタイプは一意の名前を持ち、検出を構成するフィールドの作成を促します。例えば、Address というカスタムタイプを作成して、その中に「zip_code」、「city_name」、「street_name」、「state」というフィールドを含めます。そして、文書の処理中に、「company_address」フィールドでカスタムタイプを使用できます。このフィールドは、カスタムタイプの下にある行にグループ化された情報をすべて返します。ブループリントごとに最大 30 個のカスタムタイプフィールドを持つことができます。
