# Athena での EXPLAIN および EXPLAIN ANALYZE の使用
`EXPLAIN` ステートメントは、指定された SQL ステートメントの論理実行または分散実行プランを表示、または SQL ステートメントを検証します。結果はテキスト形式での出力、またはグラフへのレンダリングのためのデータ形式での出力が可能です。
**注記**
`EXPLAIN` 構文を使用せずに、Athena コンソールでクエリの論理プランと分散プランのグラフィック表現を表示できます。詳細については、「[SQL クエリの実行プランを表示する](query-plans.md)」を参照してください。
`EXPLAIN ANALYZE` ステートメントでは、指定した SQL ステートメントの分散実行プランと、SQL クエリ内の各オペレーションに関する計算コストの両方を表示します。結果はテキスト形式または JSON 形式で出力することができます。
## 考慮事項と制限事項
Athena の `EXPLAIN` および `EXPLAIN ANALYZE` ステートメントには、以下の制限があります。
+ `EXPLAIN` クエリはデータをスキャンしないため、Athena はそれらに対する料金を請求しません。ただし、`EXPLAIN` クエリはテーブルメタデータの取得のために AWS Glue を呼び出すので、呼び出し回数が [Glue の無料利用枠制限](https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Categories=categories%23analytics&all-free-tier.q=glue&all-free-tier.q_operator=AND)を超える場合に料金が発生する可能性があります。
+ この理由は、`EXPLAIN ANALYZE` クエリが実行されデータをスキャンすると、Athena は、そのスキャンされたデータ量に対して課金をするためです。
+ Lake Formation で定義されている行またはセルのフィルタリング情報、およびクエリの統計情報は、`EXPLAIN` および `EXPLAIN ANALYZE` の出力には表示されません。
## EXPLAIN 構文
```
EXPLAIN [ ( {{option}} [, ...]) ] {{statement}}
```
{{option}} は以下のいずれかにすることができます。
```
FORMAT { TEXT | GRAPHVIZ | JSON }
TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
```
`FORMAT` オプションを指定しない場合、出力はデフォルトで `TEXT` 形式となります。`IO` タイプは、クエリが読み取るテーブルとスキーマに関する情報を提供します。
## EXPLAIN ANALYZE 構文
`EXPLAIN` からの出力に加えて、`EXPLAIN ANALYZE` では、CPU 使用率、入力された行数、出力された行数など、指定したクエリの実行時に関する統計情報も出力します。
```
EXPLAIN ANALYZE [ ( {{option}} [, ...]) ] {{statement}}
```
{{option}} は以下のいずれかにすることができます。
```
FORMAT { TEXT | JSON }
```
`FORMAT` オプションを指定しない場合、出力はデフォルトで `TEXT` 形式となります。`EXPLAIN ANALYZE` によるすべてのクエリは `DISTRIBUTED` なので、`EXPLAIN ANALYZE` では `TYPE` オプションを使用することはできません。
{{ステートメント}}は以下のいずれかになります。
```
SELECT
CREATE TABLE AS SELECT
INSERT
UNLOAD
```
## EXPLAIN での例
以下の `EXPLAIN` に関する例では、まず端的なものを示し、その後に、複合型のものへと進みます。
### 例 1: テキスト形式でクエリプランを表示するために、EXPLAIN ステートメントを使用する
次の例の `EXPLAIN` では、Elastic Load Balancing ログでの `SELECT` クエリについて、その実行プランを表示します 使用される形式はデフォルトのテキスト出力です。
```
EXPLAIN
SELECT
request_timestamp,
elb_name,
request_ip
FROM sampledb.elb_logs;
```
#### 結果
```
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULAR
```
### 例 2: EXPLAIN を使用してクエリプランをグラフ化する
Athena コンソールを使用してクエリプランをグラフ化できます。次のような `SELECT` ステートメントを Athena クエリエディタに入力し、**[EXPLAIN]** を選択します。
```
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
```
Athena クエリエディタの **[Explain]** ページが開き、クエリの分散プランと論理プランが表示されます。次のグラフは、この例の論理プランを示します。
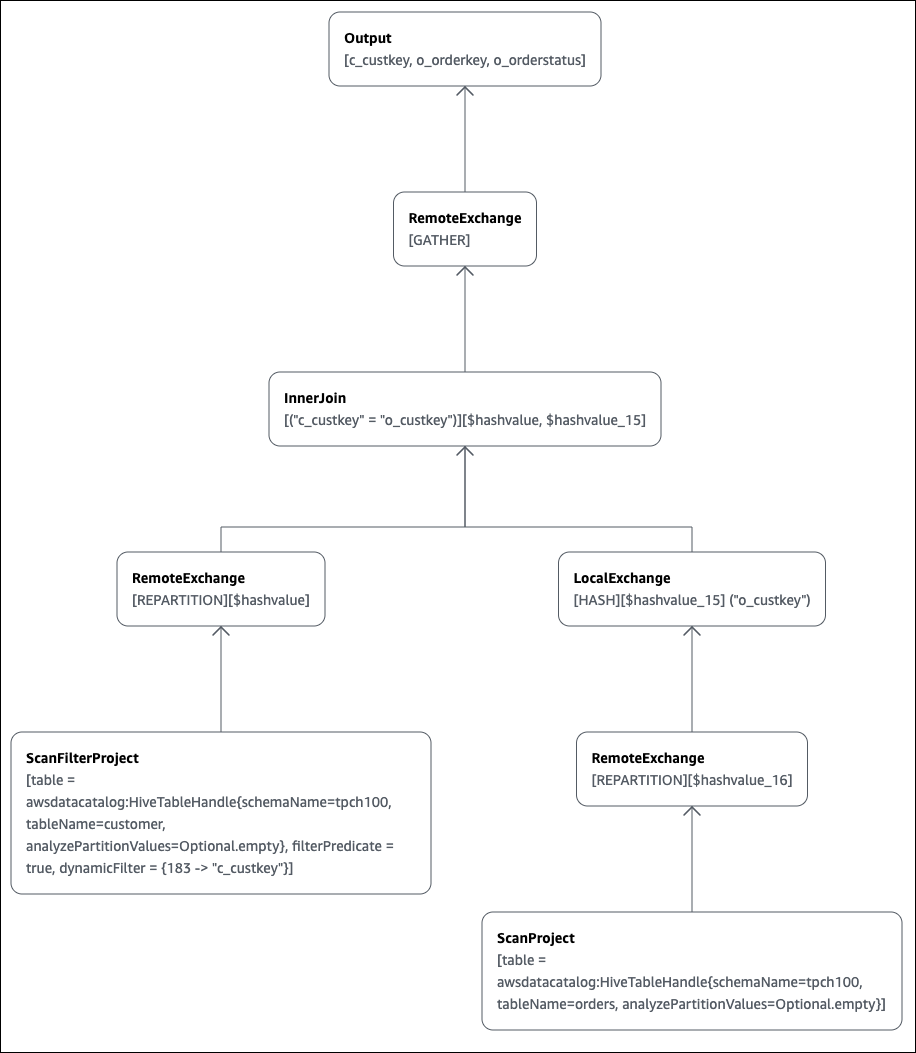
**重要**
現在、一部のパーティションフィルターは、Athena がクエリに適用しても、ネストされたオペレーターツリーグラフに表示されない場合があります。このようなフィルターの効果を検証するには、クエリで `EXPLAIN` または `EXPLAIN ANALYZE` を実行し、結果を表示します。
Athena コンソールでクエリプランのグラフ機能を使用する方法の詳細については、「[SQL クエリの実行プランを表示する](query-plans.md)」を参照してください。
### 例 3: EXPLAIN ステートメントを使用してパーティションプルーニングを検証する
パーティションされたキーにフィルタリング述語を使用してパーティションテーブルをクエリする場合、クエリエンジンはパーティションされたキーにこの述語を適用して、読み込むデータの量を減らします。
以下の例では、パーティションテーブルでの `SELECT` クエリについてパーティションプルーニングを検証するために `EXPLAIN` クエリを使用します。まず、`CREATE TABLE` ステートメントが `tpch100.orders_partitioned` テーブルを作成します。テーブルは、列 `o_orderdate` でパーティションされます。
```
CREATE TABLE `tpch100.orders_partitioned`(
`o_orderkey` int,
`o_custkey` int,
`o_orderstatus` string,
`o_totalprice` double,
`o_orderpriority` string,
`o_clerk` string,
`o_shippriority` int,
`o_comment` string)
PARTITIONED BY (
`o_orderdate` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/{{}}/'
```
`SHOW PARTITIONS` コマンドによる表示にあるように、`tpch100.orders_partitioned` テーブルには `o_orderdate` にいくつかのパーティションがあります。
```
SHOW PARTITIONS tpch100.orders_partitioned;
o_orderdate=1994
o_orderdate=2015
o_orderdate=1998
o_orderdate=1995
o_orderdate=1993
o_orderdate=1997
o_orderdate=1992
o_orderdate=1996
```
以下の `EXPLAIN` クエリは、指定された `SELECT` ステートメントでパーティションプルーニングを検証します。
```
EXPLAIN
SELECT
o_orderkey,
o_custkey,
o_orderdate
FROM tpch100.orders_partitioned
WHERE o_orderdate = '1995'
```
#### 結果
```
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR
```
結果にある太字のテキストは、`PARTITION_KEY` に述語 `o_orderdate = '1995'` が適用されたことを示しています。
### 例 4: EXPLAIN クエリを使用して結合順序と結合タイプをチェックする
以下の `EXPLAIN` クエリは、`SELECT` ステートメントの結合順序と結合タイプをチェックします。`EXCEEDED_LOCAL_MEMORY_LIMIT` エラーが発生する確率を減らすことができるように、このようなクエリを使用してクエリのメモリ使用量を調べます。
```
EXPLAIN (TYPE DISTRIBUTED)
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123
```
#### 結果
```
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR
```
このクエリ例は、パフォーマンスを向上させるためにクロス結合に最適化されています。結果は、`tpch100.orders` が `BROADCAST` 分散タイプとして分散されることを示しています。これは、結合オペレーションを実行するすべてのノードに `tpch100.orders` テーブルが分散されることを意味します。`BROADCAST` 分散タイプでは、`tpch100.orders` テーブルのフィルタリングされた結果のすべてが、結合操作を実行する各ノードのメモリに収まることが必要とされています。
ただし、`tpch100.customer` テーブルは `tpch100.orders` よりも小さくなります。`tpch100.customer` に必要なメモリは少ないため、クエリを `tpch100.orders` ではなく `BROADCAST tpch100.customer` に書き直すことができます。これにより、クエリが `EXCEEDED_LOCAL_MEMORY_LIMIT` エラーを受け取る確率が低くなります。この戦略では、以下の点を前提としています。
+ `tpch100.customer.c_custkey` が `tpch100.customer` テーブルで一意である。
+ `tpch100.customer` と `tpch100.orders` の間に 1 対多のマッピング関係がある。
以下の例は、書き直されたクエリを示しています。
```
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.orders o
JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes.
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123
```
### 例 5: EXPLAIN クエリを使用して効果がない述語を削除する
`EXPLAIN` クエリを使用して、フィルタリング述語の有効性をチェックすることができます。以下の例にあるように、結果を使用して効果がない述語を削除できます。
```
EXPLAIN
SELECT
c.c_name
FROM tpch100.customer c
WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT)
AND c.c_custkey BETWEEN 1000 AND 2000
AND c.c_custkey = 1500
```
#### 結果
```
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAR
```
結果にある `filterPredicate` は、オプティマイザが元の 3 つの述語を 2 つの述語にマージし、それらの適用順序を変更したことを示しています。
```
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
```
結果が述語 `AND c.c_custkey BETWEEN 1000 AND 2000` に効果がないことを示しているので、クエリ結果を変更することなくこの述語を削除できます。
`EXPLAIN` クエリの結果で使用された用語については、「[Athena EXPLAIN ステートメントの結果を理解する](athena-explain-statement-understanding.md)」を参照してください。
## EXPLAIN ANALYZE での例
次に、`EXPLAIN ANALYZE` クエリとその出力に関する例を示します。
### 例 1: クエリプランとコンピューティングのコストをテキスト形式で表示するために、EXPLAIN ANALYZE を使用する
次の例の `EXPLAIN ANALYZE` は、CloudFront ログでの `SELECT` クエリについて、その実行プランとコンピューティングコストを表示します。使用される形式はデフォルトのテキスト出力です。
```
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
```
#### 結果
```
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAR
```
### 例 2: クエリプランを JSON 形式で表示するために、EXPLAIN ANALYZE を使用する
次の例は、CloudFront ログでの `SELECT` クエリについて、その実行プランとコンピューティングコストを表示します。この例では、出力形式として JSON を指定しています。
```
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
```
#### 結果
```
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}
```
## その他のリソース
詳細については、次のリソースを参照してください。
+ [Athena EXPLAIN ステートメントの結果を理解する](athena-explain-statement-understanding.md)
+ [SQL クエリの実行プランを表示する](query-plans.md)
+ [完了したクエリの統計と実行の詳細を表示する](query-stats.md)
+ Trino の「[https://trino.io/docs/current/sql/explain.html](https://trino.io/docs/current/sql/explain.html)」ドキュメント
+ Trino の「[https://trino.io/docs/current/sql/explain-analyze.html](https://trino.io/docs/current/sql/explain-analyze.html)」ドキュメント
+ *AWS Big Data Blog* の「[Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena](https://aws.amazon.com/blogs/big-data/optimize-federated-query-performance-using-explain-and-explain-analyze-in-amazon-athena/)」。
[](http://www.youtube.com/watch?v=7JUyTqglmNU)