翻訳は機械翻訳により提供されています。提供された翻訳内容と英語版の間で齟齬、不一致または矛盾がある場合、英語版が優先します。
AWS Glue で ETL プロセスを に変換する AWS Schema Conversion Tool
以下は、 AWS Glue を使用して ETL スクリプトを に変換するプロセスの概要です AWS SCT。この例では、ソースデータベースおよびデータウェアハウスに使用される ETL プロセスとともに、Oracle データベースから Amazon Redshift への変換を行います。
トピック
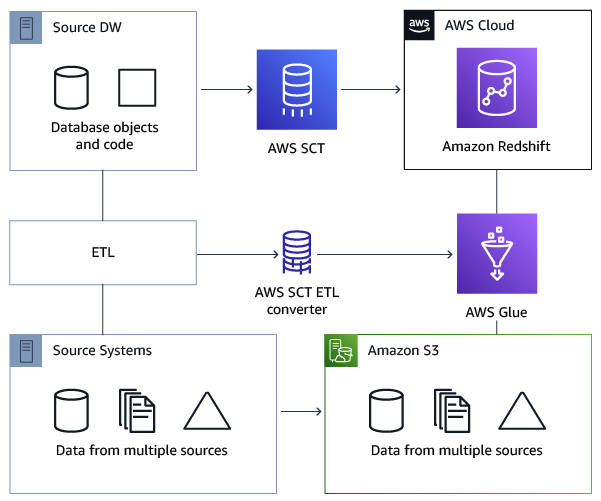
次のアーキテクチャ図は、ETL スクリプトの への変換を含むデータベース移行プロジェクトの例を示しています AWS Glue。
前提条件
開始する前に、以下を実行します。
-
AWSに移行する予定のソースデータベースをすべて移行します。
-
ターゲットデータウェアハウスを に移行します AWS。
-
ETL プロセスに関わるすべてのコードのリストを収集します。
-
各データベースに必要なすべての接続情報のリストを収集します。
また、ユーザーに代わって他の AWS リソースにアクセスするためのアクセス許可 AWS Glue も必要です。これらのアクセス許可は AWS Identity and Access Management 、(IAM) を使用して付与します。用の IAM ポリシーが作成されていることを確認します AWS Glue。詳細については、「 デベロッパーガイド」の「 Glueservice AWS の IAM ポリシーを作成する」を参照してください。 AWS Glue
AWS Glue データカタログについて
変換プロセスの一環として、 はソースデータベースとターゲットデータベースに関する情報を AWS Glue ロードします。この情報は、ツリーと呼ばれる構造で各種カテゴリに分類されます。この構造には、以下のものが含まれています。
-
接続 - 接続パラメータ
-
クローラー - クローラーのリスト。スキーマごとに 1 つのクローラーが割り当てられます。
-
データベース - テーブルを保持するコンテナ
-
テーブル - テーブル内のデータを表すメタデータ定義
-
ETL ジョブ - ETL 操作を実行するビジネスロジック
-
トリガー – ETL ジョブがいつ実行されるかを制御するロジック AWS Glue (オンデマンド、スケジュール、ジョブイベントによってトリガーされるかどうかにかかわらず)
AWS Glue データカタログは、データの場所、スキーマ、およびランタイムメトリクスへのインデックスです。 AWS Glue と を使用する場合 AWS SCT、 AWS Glue データカタログには ETL ジョブのソースとターゲットとして使用されるデータへの参照が含まれています AWS Glue。データウェアハウスを作成するには、このデータを分類します。
データカタログ内の情報は、ETL ジョブの作成と監視に使用します。一般的には、クローラーを実行してデータストア内のデータのインベントリを行いますが、データカタログにメタデータテーブルを追加する別の方法もあります。
データカタログでテーブルを定義したら、データベースに追加します。データベースはテーブルの整理に使用されます AWS Glue。
AWS SCT で を使用した変換の制限 AWS Glue
AWS SCT で を使用して変換する場合、次の制限が適用されます AWS Glue。
| リソース | デフォルトの制限 |
| アカウントあたりのデータベース数 | 10,000 |
| データベースあたりのテーブル数 | 100,000 |
| テーブルあたりのパーティションの数 | 1,000,000 |
| テーブルあたりのテーブルバージョンの数 | 100,000 |
| アカウントあたりのデータベース数 | 1,000,000 |
| アカウントあたりのパーティションの数 | 10,000,000 |
| アカウントあたりのテーブルバージョンの数 | 1,000,000 |
| アカウントあたりの接続数 | 1,000 |
| アカウントあたりのクローラー数 | 25 |
| アカウントあたりのジョブの数 | 25 |
| アカウントあたりのトリガー数 | 25 |
| アカウントあたりの同時ジョブの実行数 | 30 |
| ジョブあたりの同時ジョブの実行数 | 3 |
| トリガーごとのジョブ数 | 10 |
| アカウントごとの開発エンドポイントの数 | 5 |
| 開発エンドポイントによって一度に使用される最大データ処理単位 (DPU) 数 | 5 |
| 一度にロールによって使用される最大 DPU 数 | 100 |
| データベース名の長さ |
無制限 Apache Hive など、その他のメタデータストアとの互換性を考慮して、名前は小文字に変換されます。 Amazon Athena からデータベースにアクセスする場合は、英数字とアンダースコア文字のみを使用して名前を指定してください。 |
| 接続名の長さ | 無制限 |
| クローラー名の長さ | 無制限 |
ステップ 1: 新しい プロジェクトを作成する
新しいプロジェクトを作成するには、以下の大まかな手順を実行します。
-
で新しいプロジェクトを作成します AWS SCT。詳細については、「でのプロジェクトの開始と管理 AWS SCT」を参照してください。
-
ソースデータベースとターゲットデータベースをプロジェクトに追加します。詳細については、「でプロジェクトにサーバーを追加する AWS SCT」を参照してください。
ターゲットデータベースの接続設定で [ AWS Glueの使用] を選択していることを確認してください。それには、[AWS Glue] タブを選択します。 AWS プロファイルからコピー で、使用するプロファイルを選択します。プロファイルは、 AWS アクセスキー、シークレットキー、Amazon S3 バケットフォルダを自動的に入力する必要があります。表示されない場合は、この情報を手動で入力します。OK を選択すると、 AWS Glue はオブジェクトを分析し、メタデータを AWS Glue データカタログにロードします。
セキュリティ設定によっては、サーバー上の一部のスキーマに対する十分な権限がアカウントにないことを示す警告メッセージが表示される場合があります。使用するスキーマへのアクセス権がある場合は、このメッセージを無視しても問題ありません。
-
ETL をインポートする準備を完了するには、ソース データベースとターゲット データベースに接続します。そのためには、ソースまたはターゲットのメタデータツリーでデータベースを選択し、[サーバーに接続] を選択します。
AWS Glue は、ETL 変換に役立つデータベースをソースデータベースサーバーとターゲットデータベースサーバーに作成します。ターゲットサーバーのデータベースには、 AWS Glue データカタログが含まれています。特定のオブジェクトを見つけるには、ソースまたはターゲットパネルの検索を使用します。
特定のオブジェクトの変換方法を確認するには、変換する項目を指定し、コンテキスト (右クリック) メニューから [スキーマの変換] を選択します。 AWS SCT によって、スクリプトに変換されます。
変換されたスクリプトは、右側のパネルの [Scripts] (スクリプト) フォルダを選択します。現在、スクリプトは仮想オブジェクトであり、 AWS SCT プロジェクトの一部としてのみ使用できます。
変換されたスクリプトを使用して AWS Glue ジョブを作成するには、スクリプトを Amazon S3 にアップロードします。スクリプトを Amazon S3 にアップロードするには、スクリプトを選択し、コンテキスト (右クリック) メニューから [S3 に保存] を選択します。
ステップ 2: AWS Glue ジョブを作成する
スクリプトを Amazon S3 に保存したら、スクリプトを選択し、 AWS Glue ジョブの設定を選択してウィザードを開き、 AWS Glue ジョブを設定できます。ウィザードを使用すると、設定を簡単に行うことができます。
-
ウィザードの最初のタブの [設計データフロー] で、実行戦略と、このジョブに含めるスクリプトのリストを選択します。各スクリプトのパラメータも選択できます。また、正しい順序で実行されるようにスクリプトを並べ替えることもできます。
-
2 番目のタブでは、ジョブに名前を付け、 AWS Glueの設定を直接設定できます。この画面では、次の設定を指定できます。
-
AWS Identity and Access Management (IAM) ロール
-
スクリプトファイルの名前とファイルパス
-
Amazon S3 が管理するキーによるサーバー側の暗号化 (SSE-S3) を使用したスクリプトの暗号化
-
一時ディレクトリ
-
生成された Python ライブラリパス
-
ユーザーの Python ライブラリパス
-
依存する.jar ファイルのパス
-
参照されるファイルパス
-
実行されるジョブごとの同時 DPU
-
最大同時実行数
-
ジョブのタイムアウト (分)
-
遅延通知のしきい値 (分)
-
再試行回数
-
セキュリティ設定
-
サーバー側の暗号化
-
-
3 番目のステップ (タブ) では、ターゲットエンドポイントへの設定済みの接続を選択します。
ジョブの設定が完了すると、 AWS Glue データカタログの ETL ジョブの下に表示されます。ジョブを選択すると設定が表示され、確認または編集を行うことができます。で新しいジョブを作成するには AWS Glue、 AWS Glue ジョブのコンテキスト (右クリック) メニューからジョブの作成を選択します。これにより、スキーマ定義が適用されます。表示を更新するには、コンテキスト (右クリック) メニューから [Refresh from database] (データベースから更新) を選択します。
この時点で、 AWS Glue コンソールでジョブを表示できます。これを行うには、 にサインイン AWS マネジメントコンソール し、https://console.aws.amazon.com/glue/
新しいジョブをテストして、正常に動作していることを確認します。そのためには、まずソーステーブルのデータを確認し、ターゲットテーブルが空であることを確認します。ジョブを実行してから、もう一度確認します。 AWS Glue コンソールからエラーログを表示できます。
