Amazon RDS ゼロ ETL 統合でのデータフィルタリング
Amazon RDS ゼロ ETL 統合はデータフィルタリングをサポートしているため、ソース Amazon RDS データベースからターゲットデータウェアハウスにレプリケートされるデータを制御できます。データベース全体をレプリケートする代わりに、1 つ以上のフィルターを適用して、特定のテーブルを選択的に含めたり除外したりできます。これにより、関連するデータのみが転送されるようにすることで、ストレージとクエリのパフォーマンスを最適化できます。現在、フィルタリングはデータベースレベルとテーブルレベルに制限されています。列レベルと行レベルのフィルタリングはサポートされていません。
データフィルタリングは、次のような場合に便利です。
-
2 つ以上の異なるソースデータベースの特定のテーブルを結合し、いずれのデータベースのデータ全体は必要ない場合。
-
データベース全体ではなく、テーブルのサブセットのみを使用して分析を行うことで、コストを節約する場合。
-
電話番号、住所、クレジットカード情報などの機密情報を特定のテーブルから除外する場合。
ゼロ ETL 統合には、AWS マネジメントコンソール、AWS Command Line Interface (AWS CLI)、または RDS API を使用して、データフィルターを追加できます。
統合でプロビジョンしたクラスターをターゲットとして使用している場合、データフィルタリングを使用するには、クラスターがパッチ 180 以降である必要があります。
トピック
データフィルターの形式
1 つの統合に対して複数のフィルターを定義できます。各フィルターは、フィルター式のパターンのいずれかに一致する既存および今後利用するデータベーステーブルを含めるまたは除外します。Amazon RDS ゼロ ETL 統合では、データフィルタリングに Maxwell フィルター構文
各フィルターには以下の要素が含まれます。
| Element | 説明 |
|---|---|
| フィルタータイプ |
|
| フィルター式 |
コンマ区切りのパターンのリスト。式では Maxwell フィルター構文 |
| パターン |
フィルターパターンの形式は 注記RDS for MySQL の場合、正規表現はデータベース名とテーブル名の両方でサポートされています。RDS for PostgreSQL の場合、正規表現はスキーマ名とテーブル名でのみサポートされ、データベース名ではサポートされていません。 列レベルのフィルターや拒否リストを含めることはできません。 1 つの統合に含めることができるパターンの合計数は、最大 99 個です。コンソールでは、パターンを 1 つのフィルター式に含めることも、複数の式に分散することもできます。1 つのパターンの長さは 256 文字を超えることはできません。 |
重要
RDS for PostgreSQL ソースデータベースを選択する場合は、少なくとも 1 つのデータフィルターパターンを指定する必要があります。このパターンには、ターゲットデータウェアハウスへのレプリケーション用のデータベース (database-name.*.*
次の図は、コンソールでの RDS for MySQL データフィルターの構造を示しています。
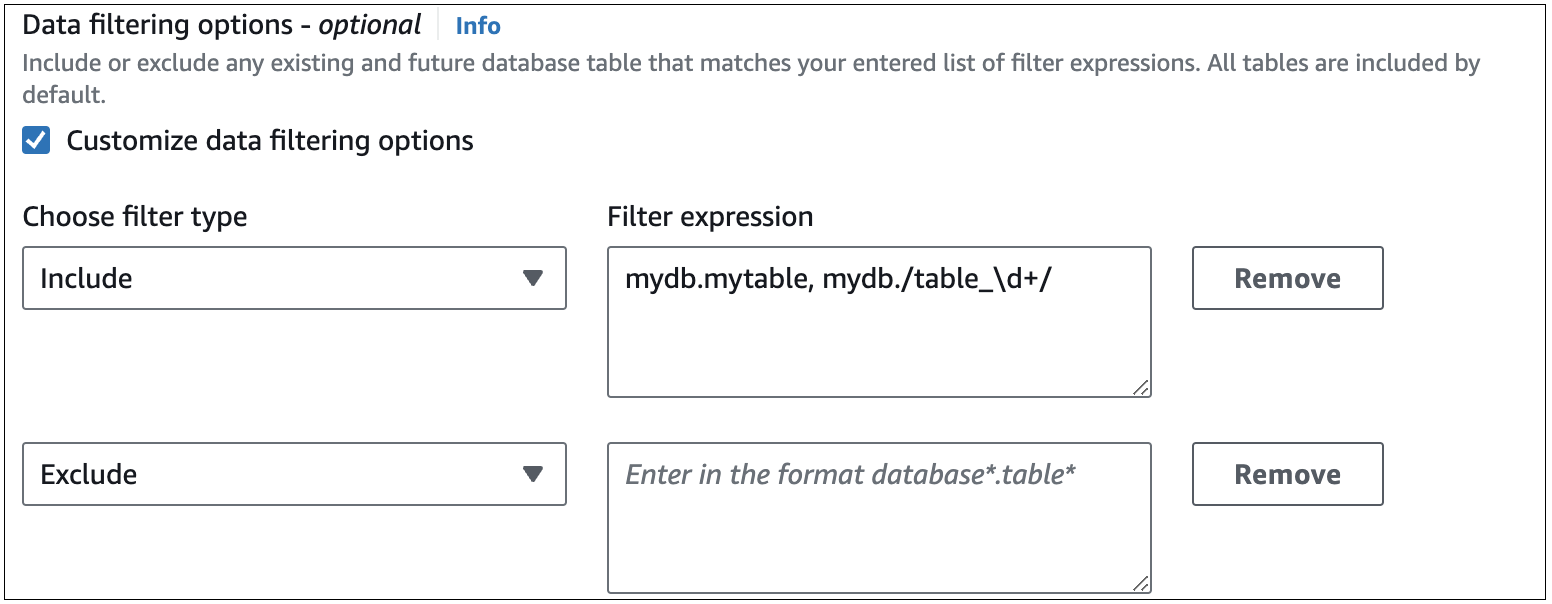
重要
フィルターパターンには、個人を特定する情報、または機密情報を含めないでください。
AWS CLI のデータフィルター
AWS CLI を使用してデータフィルターを追加する場合、構文はコンソールと少し異なります。1 つのフィルタータイプで複数のパターンをグループ化できないように、各パターンにフィルタータイプ (Include または Exclude) を個別に割り当てる必要があります。
例えば、コンソールでは、以下のカンマで区切られたパターンを 1 つの Include ステートメントにまとめることができます。
RDS for MySQL
mydb.mytable,mydb./table_\d+/
RDS for PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
ただし AWS CLI を使用する際は、データフィルターを次のように記述する必要があります。
RDS for MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
RDS for PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
フィルター論理
統合でデータフィルターを指定しない場合、Amazon RDS は include:*.* をデフォルトのフィルターと見なし、すべてのテーブルをターゲットデータウェアハウスに複製します。ただし、少なくとも 1 つのフィルターを追加すると、デフォルトのロジックは exclude:*.* に切り替わり、デフォルトですべてのテーブルが除外されます。これにより、レプリケーションに含めるデータベースとテーブルを明示的に定義できます。
例えば、次のフィルターを定義する場合、
'include: db.table1, include: db.table2'
Amazon RDS は、フィルターを次のように解釈します。
'exclude:*.*, include: db.table1, include: db.table2'
結果として、Amazon RDS は db という名前のデータベースから table1 および table2 のみをターゲットデータウェアハウスにレプリケートします。
フィルターの優先順位
Amazon RDS は、指定された順番にデータフィルターを適用します。AWS マネジメントコンソール では、フィルタ式を左から右、上から下へと処理します。2 番目のフィルターまたは最初のフィルターに続く個々のパターンは、それを上書きできます。
例えば、最初のフィルターが Include books.stephenking の場合、books データベースの stephenking テーブルのみが含まれます。ただし、2 つ目のフィルター、Exclude books.* を追加すると、最初のフィルターが上書きされます。これにより、books インデックスのテーブルがターゲットデータウェアハウスにレプリケートされるのを防ぐことができます。
1 つまたは複数のフィルターを指定すると、ロジックはデフォルトで exclude:*.* を前提として開始されます。そのため、すべてのテーブルが自動的にレプリケーションから除外されます。ベストプラクティスとして、最も広範なフィルターから最も具体的なフィルターを定義します。1 つ以上の Include ステートメントから始めてレプリケートするデータを指定し、Exclude フィルターを追加して特定のテーブルを選択的に削除します。
AWS CLI を使用して定義するフィルターにも同じ原則が適用されます。Amazon RDS は、これらのフィルターパターンを指定された順番で適用するため、あるパターンによってその前に指定されたフィルターパターンが上書きされる場合があります。
RDS for MySQL の例
以下の例は、RDS for MySQL の例におけるゼロ ETL 統合でのデータフィルタリングの仕組みを示しています。
-
すべてのデータベースとすべてのテーブルを含める。
'include: *.*' -
booksデータベース内のすべてのテーブルを含める。'include: books.*' -
mysteryという名前のすべてのテーブルを除外します。'include: *.*, exclude: *.mystery' -
booksデータベース内の 2 つの特定のテーブルを含める。'include: books.stephen_king, include: books.carolyn_keene' -
サブストリング
mysteryを含んでいるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./.*mystery.*/' -
mysteryで始まるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./mystery.*/' -
mysteryで終わるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./.*mystery/' -
table_stephen_kingという名前のテーブルを除き、table_で始まるbooksデータベース内の すべてのテーブルを含めます。例えば、table_moviesやtable_booksはレプリケートされますが、table_stephen_kingはレプリケートされません。'include: books./table_.*/, exclude: books.table_stephen_king'
RDS for PostgreSQL の例
以下の例は、RDS for PostgreSQL ゼロ ETL 統合でのデータフィルタリングの仕組みを示しています。
-
booksデータベース内のすべてのテーブルを含めます。'include: books.*.*' -
booksデータベース内のmysteryという名前のテーブルをすべて除外します。'include: books.*.*, exclude: books.*.mystery' -
booksデータベース内のmysteryスキーマの 1 つのテーブルを含め、employeeデータベース内のfinanceスキーマの 1 つのテーブルを含めます。'include: books.mystery.stephen_king, include: employee.finance.benefits' -
サブストリング
kingを含むテーブルを除き、booksデータベースおよびscience_fictionスキーマ内のすべてのテーブルを含めます。'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
sciで始まるスキーマ名を持つテーブルを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*.*, exclude: books./sci.*/.*' -
mysteryスキーマ内のkingで終わるテーブルを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*.*, exclude: books.mystery./.*king/' -
table_stephen_kingという名前のテーブルを除き、table_で始まるbooksデータベース内のすべてのテーブルを含めます。例えば、fictionスキーマのtable_moviesとmysteryスキーマのtable_booksはレプリケートされますが、どちらのスキーマでもtable_stephen_kingはレプリケートされません。'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
RDS for Oracle の例
以下の例は、RDS for Oracle ゼロ ETL 統合でのデータフィルタリングの仕組みを示しています。
-
books データベース内のすべてのテーブルを含めます。
'include: books.*.*' -
books データベース内の mystery という名前のテーブルをすべて除外します。
'include: books.*.*, exclude: books.*.mystery' -
books データベース内の mystery スキーマのテーブルを 1 つ含め、employee データベース内の finance スキーマのテーブルを 1 つ含めます。
'include: books.mystery.stephen_king, include: employee.finance.benefits' -
books データベース内の mystery スキーマのすべてのテーブルを含めます。
'include: books.mystery.*'
大文字と小文字の区別に関する考慮事項
Oracle Database と Amazon Redshift では、オブジェクト名の大文字と小文字の処理方法が異なり、これはデータフィルター設定とターゲットクエリの両方に影響します。次の点に注意してください。
-
Oracle Database は、
CREATEステートメントで明示的に引用符で囲まれていない限り、データベース、スキーマ、およびオブジェクト名を大文字で保存します。例えば、mytable(引用符なし) を作成する場合、Oracle データディクショナリはテーブル名をMYTABLEとして保存します。オブジェクト名を引用すると、データディクショナリは大文字と小文字を保持します。 -
ゼロ ETL データフィルターでは大文字と小文字が区別され、Oracle データディクショナリに表示されるオブジェクト名の大文字と小文字が正確に一致する必要があります。
-
Amazon Redshift クエリは、明示的に引用符で囲まれていない限り、デフォルトで小文字のオブジェクト名になります。例えば、
MYTABLE(引用符なし) のクエリはmytableを検索します。
Amazon Redshift フィルターを作成してデータをクエリするときは、大文字と小文字の違いに注意してください。
大文字の統合の作成
二重引用符で名前を指定せずにテーブルを作成すると、Oracle データベースは名前をデータディクショナリに大文字で保存します。例えば、次のいずれかの SQL ステートメントを使用して MYTABLE を作成できます。
CREATE TABLE REINVENT.MYTABLE (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reinvent.mytable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE REinvent.MyTable (id NUMBER PRIMARY KEY, description VARCHAR2(100)); CREATE TABLE reINVENT.MYtabLE (id NUMBER PRIMARY KEY, description VARCHAR2(100));
上記のステートメントでテーブル名を引用しなかったため、Oracle データベースはオブジェクト名を大文字で MYTABLE として保存します。
このテーブルを Amazon Redshift にレプリケートするには、create-integration コマンドのデータフィルターで大文字の名前を指定する必要があります。ゼロ ETL フィルター名と Oracle データディクショナリ名は一致する必要があります。
aws rds create-integration \ --integration-name upperIntegration \ --data-filter "include: ORCL.REINVENT.MYTABLE" \ ...
デフォルトでは、Amazon Redshift はデータを小文字で保存します。Amazon Redshift のレプリケートされたデータベースで MYTABLE をクエリするには、Oracle データディクショナリのケースと一致するように大文字名 MYTABLE を引用符で囲む必要があります。
SELECT * FROM targetdb1."REINVENT"."MYTABLE";
次のクエリでは、引用符メカニズムを使用しません。これらは、デフォルトの小文字名を使用する mytable という名前の Amazon Redshift テーブルを検索するためエラーを返しますが、Oracle データディクショナリではそのテーブルの名前は MYTABLE です。
SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable; SELECT * FROM targetdb1."REINVENT".mytable;
次のクエリでは、引用符メカニズムを使用して大文字と小文字が混在する名前を指定します。クエリはすべて、MYTABLE という名前ではない Amazon Redshift テーブルを検索するため、エラーを返します。
SELECT * FROM targetdb1."REINVENT"."MYtablE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."mytable";
小文字の統合の作成
次の代替例では、二重引用符を使用して、Oracle データディクショナリにテーブル名を小文字で保存します。次のように mytable を作成します。
CREATE TABLE REINVENT."mytable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle データベースは、テーブル名 mytable を小文字として保存します。このテーブルを Amazon Redshift にレプリケートするには、ゼロ ETL データフィルターで小文字の名前 mytable を指定する必要があります。
aws rds create-integration \ --integration-name lowerIntegration \ --data-filter "include: ORCL.REINVENT.mytable" \ ...
Amazon Redshift のレプリケートされたデータベースでこのテーブルをクエリするときは、小文字の名前 mytable を指定できます。クエリは、Oracle データディクショナリのテーブル名である mytable という名前のテーブルを検索するため、成功します。
SELECT * FROM targetdb1."REINVENT".mytable;
Amazon Redshift のデフォルトは小文字のオブジェクト名であるため、次のクエリも mytable の検索に成功します。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".MyTable;
次のクエリでは、オブジェクト名の引用符メカニズムを使用します。名前が mytable と異なる Amazon Redshift テーブルを検索するため、すべてエラーが返されます。
SELECT * FROM targetdb1."REINVENT"."MYTABLE"; SELECT * FROM targetdb1."REINVENT"."MyTable"; SELECT * FROM targetdb1."REINVENT"."MYtablE";
大文字と小文字が混在する統合でテーブルを作成する
次の例では、二重引用符を使用して、Oracle データディクショナリにテーブル名を小文字で保存します。次のように MyTable を作成します。
CREATE TABLE REINVENT."MyTable" (id NUMBER PRIMARY KEY, description VARCHAR2(100));
Oracle データベースでは、このテーブル名が大文字と小文字が混在した MyTable として保存されます。このテーブルを Amazon Redshift にレプリケートするには、データフィルターで大文字と小文字が混在した名前を指定する必要があります。
aws rds create-integration \ --integration-name mixedIntegration \ --data-filter "include: ORCL.REINVENT.MyTable" \ ...
Amazon Redshift のレプリケートされたデータベースでこのテーブルをクエリする場合は、オブジェクト名を引用符で囲んで大文字と小文字が混在した名前 MyTable を指定する必要があります。
SELECT * FROM targetdb1."REINVENT"."MyTable";
Amazon Redshift のデフォルトは小文字のオブジェクト名であるため、次のクエリは小文字の名前 mytable を検索しているため、オブジェクトを見つけられません。
SELECT * FROM targetdb1."REINVENT".MYtablE; SELECT * FROM targetdb1."REINVENT".MYTABLE; SELECT * FROM targetdb1."REINVENT".mytable;
注記
RDS for Oracle 統合では、データベース名、スキーマ、またはテーブル名のフィルター値に正規表現を使用することはできません。
統合へのデータフィルターの追加
AWS マネジメントコンソール、AWS CLI、または Amazon RDS API を使用してデータフィルタリングを設定できます。
重要
統合の作成後にフィルターを追加すると、Amazon RDS はフィルターがもともと存在していたものであるかのようにフィルターを扱います。新しいフィルタリング条件に一致しないターゲットデータウェアハウスのデータを削除し、影響を受けるすべてのテーブルを再同期します。
ゼロ ETL 統合にデータフィルターを追加するには
AWS マネジメントコンソール にサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 -
ナビゲーションペインから、[ゼロ ETL 統合] を選択します。データフィルターを追加する統合を選択して [変更] を選択します。
-
[ソース] で、1 つまたは複数の
IncludeステートメントとExcludeステートメントを追加します。次の図は、MySQL 統合のデータフィルターの例を示しています。

-
変更が適切であることを確認したら、[続行] および [変更を保存] を選択します。
AWS CLI を使用してゼロ ETL 統合にデータフィルターを追加するには、modify-integrationInclude および Exclude の Maxwell フィルターのカンマ区切りリストで --data-filter パラメーターを指定します。
例
次の例は、my-integration にフィルターパターンを追加します。
Linux、macOS、Unix の場合:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Windows の場合:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
RDS API を使用してゼロ ETL 統合を変更するには、ModifyIntegration オペレーションを呼び出します。統合 ID を指定し、フィルターパターンのカンマ区切りリストを指定します。
統合からのデータフィルターの削除
統合からデータフィルターを削除すると、Amazon RDS は削除したフィルターが存在しなかったかのようにそれ以外のフィルターを適用し始めます。次に、基準を満たした以前に除外されたデータをターゲットデータウェアハウスにレプリケートします。これにより、影響を受けるすべてのテーブルの再同期がトリガーされます。
