Aurora ゼロ ETL 統合でのデータフィルタリング
Aurora ゼロ ETL 統合はデータフィルタリングをサポートしているため、ソース Aurora DB クラスターからターゲットデータウェアハウスにレプリケートされるデータを制御できます。データベース全体をレプリケートする代わりに、1 つ以上のフィルターを適用して、特定のテーブルを選択的に含めたり除外したりできます。これにより、関連するデータのみが転送されるようにすることで、ストレージとクエリのパフォーマンスを最適化できます。現在、フィルタリングはデータベースレベルとテーブルレベルに制限されています。列レベルと行レベルのフィルタリングはサポートされていません。
データフィルタリングは、次のような場合に便利です。
-
2 つ以上の異なるソースクラスターの特定のテーブルを結合し、いずれのクラスターのデータ全体は必要ない場合。
-
データベース全体ではなく、テーブルのサブセットのみを使用して分析を行うことで、コストを節約する場合。
-
電話番号、住所、クレジットカード情報などの機密情報を特定のテーブルから除外する場合。
ゼロ ETL 統合には、AWS マネジメントコンソール、AWS Command Line Interface (AWS CLI)、または RDS API を使用して、データフィルターを追加できます。
統合でプロビジョンしたクラスターをターゲットとして使用している場合、データフィルタリングを使用するには、クラスターがパッチ 180 以降である必要があります。
データフィルターの形式
1 つの統合に対して複数のフィルターを定義できます。各フィルターは、フィルター式のパターンのいずれかに一致する既存および今後利用するデータベーステーブルを含めるまたは除外します。Aurora ゼロ ETL 統合では、データフィルタリングに Maxwell フィルター構文
各フィルターには以下の要素が含まれます。
| Element | 説明 |
|---|---|
| フィルタータイプ |
|
| フィルター式 |
コンマ区切りのパターンのリスト。式では Maxwell フィルター構文 |
| パターン |
フィルターパターンの形式は 注記Aurora MySQL の場合、正規表現はデータベース名とテーブル名の両方でサポートされています。Aurora PostgreSQL の場合、正規表現はスキーマ名とテーブル名でのみサポートされ、データベース名ではサポートされていません。 列レベルのフィルターや拒否リストを含めることはできません。 1 つの統合に含めることができるパターンの合計数は、最大 99 個です。コンソールでは、パターンを 1 つのフィルター式に含めることも、複数の式に分散することもできます。1 つのパターンの長さは 256 文字を超えることはできません。 |
重要
Aurora PostgreSQL ソース DB クラスターを選択する場合は、少なくとも 1 つのデータフィルターパターンを指定する必要があります。このパターンには、ターゲットデータウェアハウスへのレプリケーション用のデータベース (database-name.*.*
次の図は、コンソールでの Aurora MySQL データフィルターの構造を示しています。
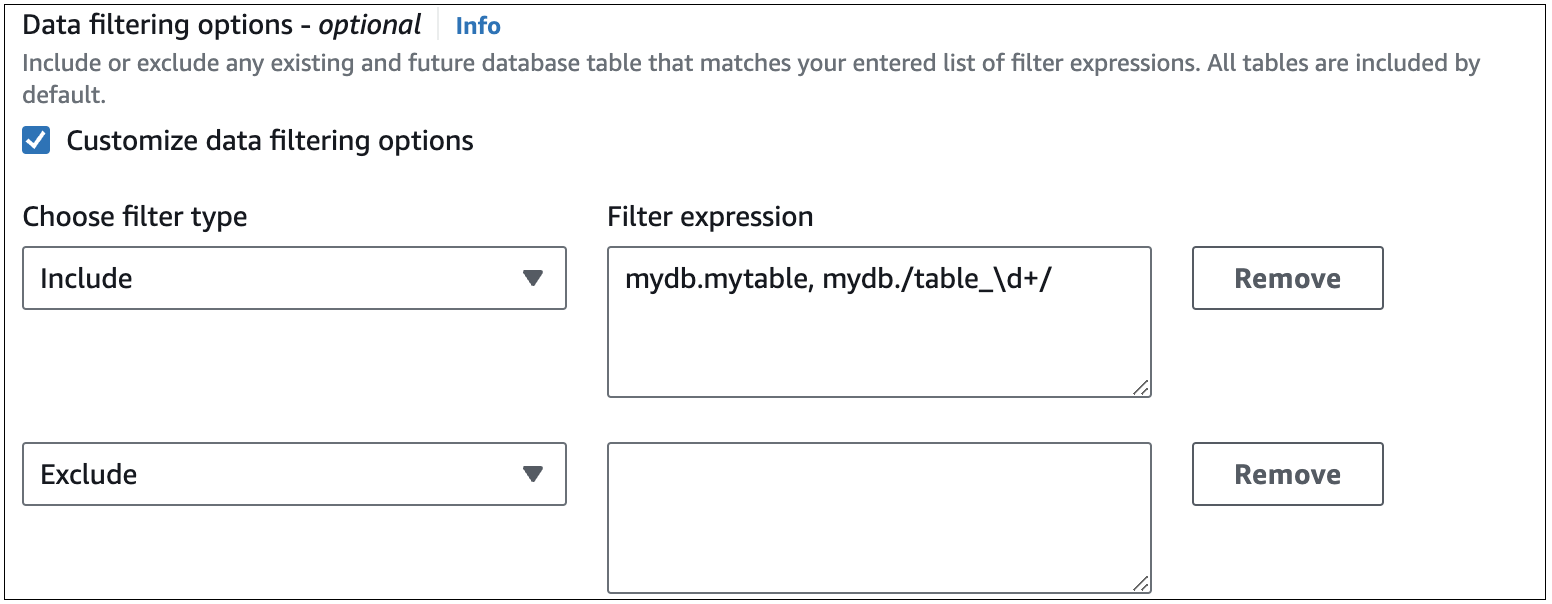
重要
フィルターパターンには、個人を特定する情報、または機密情報を含めないでください。
AWS CLI のデータフィルター
AWS CLI を使用してデータフィルターを追加する場合、構文はコンソールと少し異なります。1 つのフィルタータイプで複数のパターンをグループ化できないように、各パターンにフィルタータイプ (Include または Exclude) を個別に割り当てる必要があります。
例えば、コンソールでは、以下のカンマで区切られたパターンを 1 つの Include ステートメントにまとめることができます。
Aurora MySQL
mydb.mytable,mydb./table_\d+/
Aurora PostgreSQL
mydb.myschema.mytable,mydb.myschema./table_\d+/
ただし AWS CLI を使用する際は、データフィルターを次のように記述する必要があります。
Aurora MySQL
'include:mydb.mytable, include:mydb./table_\d+/'
Aurora PostgreSQL
'include:mydb.myschema.mytable, include:mydb.myschema./table_\d+/'
フィルター論理
統合でデータフィルターを指定しない場合、Aurora は include:*.* をデフォルトのフィルターと見なし、すべてのテーブルをターゲットデータウェアハウスに複製します。ただし、少なくとも 1 つのフィルターを追加すると、デフォルトのロジックは exclude:*.* に切り替わり、デフォルトですべてのテーブルが除外されます。これにより、レプリケーションに含めるデータベースとテーブルを明示的に定義できます。
例えば、次のフィルターを定義する場合、
'include: db.table1, include: db.table2'
Aurora は、フィルターを次のように解釈します。
'exclude:*.*, include: db.table1, include: db.table2'
結果として、Aurora は db という名前のデータベースから table1 および table2 のみをターゲットデータウェアハウスにレプリケートします。
フィルターの優先順位
Aurora は、指定された順番にデータフィルターを適用します。AWS マネジメントコンソール では、フィルタ式を左から右、上から下へと処理します。2 番目のフィルターまたは最初のフィルターに続く個々のパターンは、それを上書きできます。
例えば、最初のフィルターが Include books.stephenking の場合、books データベースの stephenking テーブルのみが含まれます。ただし、2 つ目のフィルター、Exclude books.* を追加すると、最初のフィルターが上書きされます。これにより、books インデックスのテーブルがターゲットデータウェアハウスにレプリケートされるのを防ぐことができます。
1 つまたは複数のフィルターを指定すると、ロジックはデフォルトで exclude:*.* を前提として開始されます。そのため、すべてのテーブルが自動的にレプリケーションから除外されます。ベストプラクティスとして、最も広範なフィルターから最も具体的なフィルターを定義します。1 つ以上の Include ステートメントから始めてレプリケートするデータを指定し、Exclude フィルターを追加して特定のテーブルを選択的に削除します。
AWS CLI を使用して定義するフィルターにも同じ原則が適用されます。Aurora は、これらのフィルターパターンを指定された順番で適用するため、あるパターンによってその前に指定されたフィルターパターンが上書きされる場合があります。
Aurora MySQL の例
以下の例は、Aurora MySQL の例におけるゼロ ETL 統合でのデータフィルタリングの仕組みを示しています。
-
すべてのデータベースとすべてのテーブルを含める。
'include: *.*' -
booksデータベース内のすべてのテーブルを含める。'include: books.*' -
mysteryという名前のすべてのテーブルを除外します。'include: *.*, exclude: *.mystery' -
booksデータベース内の 2 つの特定のテーブルを含める。'include: books.stephen_king, include: books.carolyn_keene' -
サブストリング
mysteryを含んでいるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./.*mystery.*/' -
mysteryで始まるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./mystery.*/' -
mysteryで終わるものを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*, exclude: books./.*mystery/' -
table_stephen_kingという名前のテーブルを除き、table_で始まるbooksデータベース内の すべてのテーブルを含めます。例えば、table_moviesやtable_booksはレプリケートされますが、table_stephen_kingはレプリケートされません。'include: books./table_.*/, exclude: books.table_stephen_king'
Aurora PostgreSQL の例
以下の例は、Aurora PostgreSQL ゼロ ETL 統合でのデータフィルタリングの仕組みを示しています。
-
booksデータベース内のすべてのテーブルを含めます。'include: books.*.*' -
booksデータベース内のmysteryという名前のテーブルをすべて除外します。'include: books.*.*, exclude: books.*.mystery' -
booksデータベース内のmysteryスキーマの 1 つのテーブルを含め、employeeデータベース内のfinanceスキーマの 1 つのテーブルを含めます。'include: books.mystery.stephen_king, include: employee.finance.benefits' -
サブストリング
kingを含むテーブルを除き、booksデータベースおよびscience_fictionスキーマ内のすべてのテーブルを含めます。'include: books.science_fiction.*, exclude: books.*./.*king.*/ -
sciで始まるスキーマ名を持つテーブルを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*.*, exclude: books./sci.*/.*' -
mysteryスキーマ内のkingで終わるテーブルを除き、booksデータベース内のすべてのテーブルを含めます。'include: books.*.*, exclude: books.mystery./.*king/' -
table_stephen_kingという名前のテーブルを除き、table_で始まるbooksデータベース内のすべてのテーブルを含めます。例えば、fictionスキーマのtable_moviesとmysteryスキーマのtable_booksはレプリケートされますが、どちらのスキーマでもtable_stephen_kingはレプリケートされません。'include: books.*./table_.*/, exclude: books.*.table_stephen_king'
統合へのデータフィルターの追加
AWS マネジメントコンソール、AWS CLI、または Amazon RDS API を使用してデータフィルタリングを設定できます。
重要
統合の作成後にフィルターを追加すると、Aurora はフィルターがもともと存在していたものであるかのようにフィルターを扱います。新しいフィルタリング条件に一致しないターゲットデータウェアハウスのデータを削除し、影響を受けるすべてのテーブルを再同期します。
ゼロ ETL 統合にデータフィルターを追加するには
AWS マネジメントコンソール にサインインし、Amazon RDS コンソール (https://console.aws.amazon.com/rds/
) を開きます。 -
ナビゲーションペインから、[ゼロ ETL 統合] を選択します。データフィルターを追加する統合を選択して [変更] を選択します。
-
[ソース] で、1 つまたは複数の
IncludeステートメントとExcludeステートメントを追加します。次の図は、MySQL 統合のデータフィルターの例を示しています。
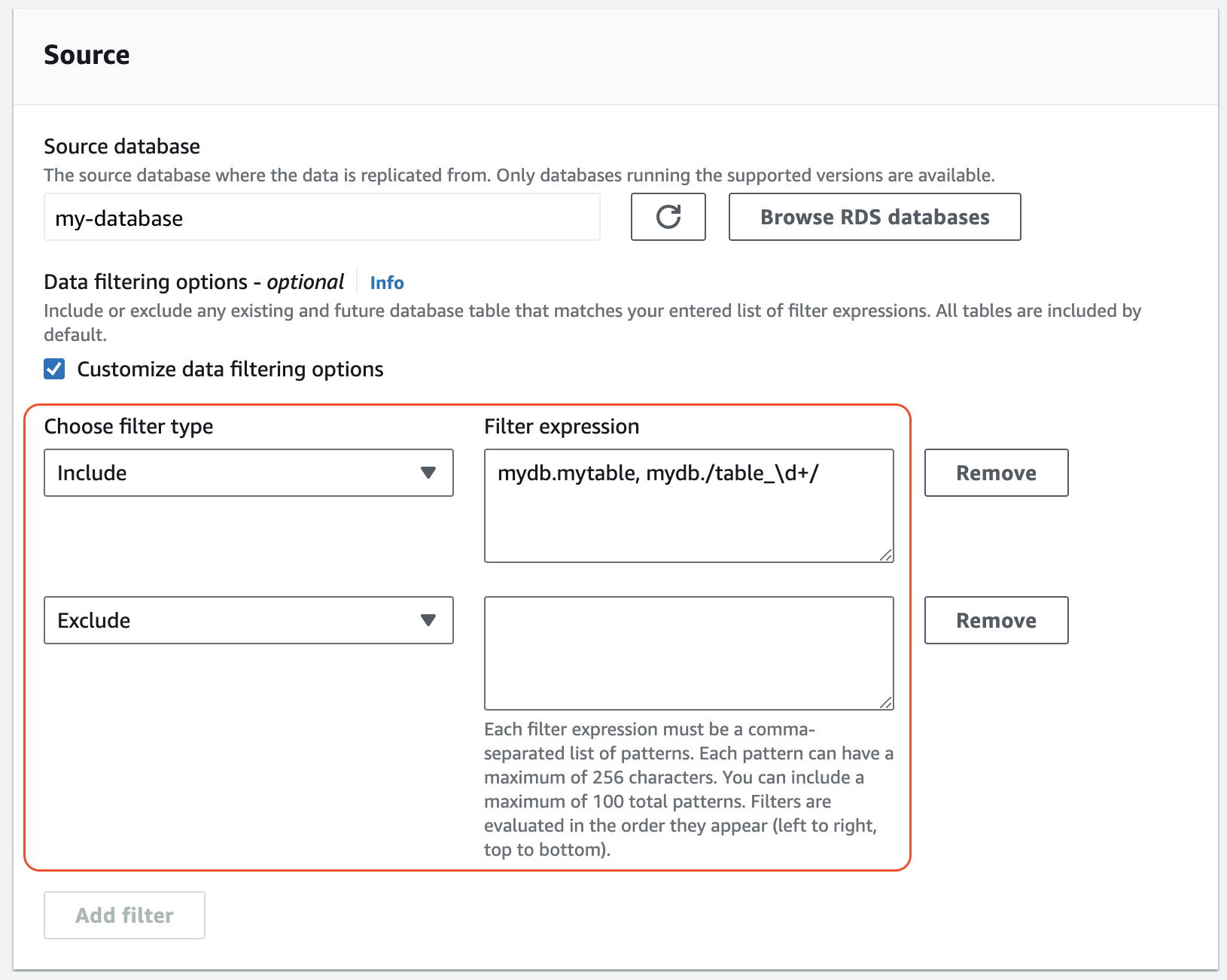
-
変更が適切であることを確認したら、[続行] および [変更を保存] を選択します。
AWS CLI を使用してゼロ ETL 統合にデータフィルターを追加するには、modify-integrationInclude および Exclude の Maxwell フィルターのカンマ区切りリストで --data-filter パラメーターを指定します。
例
次の例は、my-integration にフィルターパターンを追加します。
Linux、macOS、Unix の場合:
aws rds modify-integration \ --integration-identifiermy-integration\ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
Windows の場合:
aws rds modify-integration ^ --integration-identifiermy-integration^ --data-filter'include: foodb.*, exclude: foodb.tbl, exclude: foodb./table_\d+/'
RDS API を使用してゼロ ETL 統合を変更するには、ModifyIntegration オペレーションを呼び出します。統合 ID を指定し、フィルターパターンのカンマ区切りリストを指定します。
統合からのデータフィルターの削除
統合からデータフィルターを削除すると、Aurora は削除したフィルターが存在しなかったかのようにそれ以外のフィルターを適用し始めます。次に、基準を満たした以前に除外されたデータをターゲットデータウェアハウスにレプリケートします。これにより、影響を受けるすべてのテーブルの再同期がトリガーされます。
