Aurora PostgreSQL Limitless Database の DDL 制限とその他の情報
以下のトピックでは、Aurora PostgreSQL Limitless Database の DDL SQL コマンドの制限や詳細について説明します。
トピック
ALTER TABLE
ALTER TABLE コマンドは、Aurora PostgreSQL Limitless Database で一般的にサポートされています。詳細については、PostgreSQL ドキュメントの「ALTER TABLE
制限事項
ALTER TABLE には、サポートされるオプションについて以下の制限があります。
サポートされていないオプション
一部のオプションは、トリガーなどのサポートされていない機能に依存するため、サポートされていません。
次の ALTER TABLE のテーブルレベルのオプションはサポートされていません。
-
ALL IN TABLESPACE -
ATTACH PARTITION -
DETACH PARTITION -
ONLYフラグ -
RENAME CONSTRAINT
次の ALTER TABLE の列レベルのオプションはサポートされていません。
-
ADD GENERATED
-
DROP EXPRESSION [ IF EXISTS ]
-
DROP IDENTITY [ IF EXISTS ]
-
RESET
-
RESTART
-
SET
-
SET COMPRESSION
-
SET STATISTICS
CREATE DATABASE
Aurora PostgreSQL Limitless Database では、制限のないデータベースのみがサポートされています。
CREATE DATABASE の実行中に、1 つ以上のノードで正常に作成されたデータベースが、他のノードで失敗することがあります。これは、データベースの作成が非トランザクションオペレーションであるためです。この場合、DB シャードグループの一貫性を維持するために、正常に作成されたデータベースオブジェクトは、事前指定された時間内にすべてのノードから自動的に削除されます。この間、同じ名前のデータベースを再作成すると、データベースが既に存在することを示すエラーが発生する可能性があります。
以下のオペレーションがサポートされています。
-
照合:
CREATE DATABASEnameWITH [LOCALE =locale] [LC_COLLATE =lc_collate] [LC_CTYPE =lc_ctype] [ICU_LOCALE =icu_locale] [ICU_RULES =icu_rules] [LOCALE_PROVIDER =locale_provider] [COLLATION_VERSION =collation_version]; -
CREATE DATABASE WITH OWNER:CREATE DATABASEnameWITH OWNER =user_name;
次のオプションはサポートされていません。
-
CREATE DATABASE WITH TABLESPACE:CREATE DATABASEnameWITH TABLESPACE =tablespace_name; -
CREATE DATABASE WITH TEMPLATE:CREATE DATABASEnameWITH TEMPLATE =template;
CREATE INDEX
CREATE INDEX CONCURRENTLY はシャードテーブルでサポートされています。
CREATE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX は、すべてのテーブルタイプでサポートされています。
CREATE UNIQUE INDEXindex_nameONtable_name(column_name);
CREATE UNIQUE INDEX CONCURRENTLY はサポートされていません。
CREATE UNIQUE INDEX CONCURRENTLYindex_nameONtable_name(column_name);
詳細については、「UNIQUE」を参照してください。インデックスの作成に関する一般的な情報については、PostgreSQL ドキュメントの「CREATE INDEX
- インデックスの表示
-
\dまたは同様のコマンドを使用する場合、すべてのインデックスがルーターに表示されるわけではありません。代わりに、次の例に示すように、table_namepg_catalog.pg_indexesビューを使用してインデックスを取得します。SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"id"}'; CREATE TABLE items (id int PRIMARY KEY, val int); CREATE INDEX items_my_index on items (id, val); postgres_limitless=> SELECT * FROM pg_catalog.pg_indexes WHERE tablename='items'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+----------------+------------+------------------------------------------------------------------------ public | items | items_my_index | | CREATE INDEX items_my_index ON ONLY public.items USING btree (id, val) public | items | items_pkey | | CREATE UNIQUE INDEX items_pkey ON ONLY public.items USING btree (id) (2 rows)
CREATE SCHEMA
スキーマ要素を持つ CREATE SCHEMA はサポートされていません。
CREATE SCHEMAmy_schemaCREATE TABLE (column_nameINT);
これにより、次のようなエラーが生成されます。
ERROR: CREATE SCHEMA with schema elements is not supported
CREATE TABLE
CREATE TABLE ステートメントの関係はサポートされていません。次に例を示します。
CREATE TABLE orders (orderid int, customerId int, orderDate date) WITH (autovacuum_enabled = false);
IDENTITY 列はサポートされていません。次に例を示します。
CREATE TABLE orders (orderid INT GENERATED ALWAYS AS IDENTITY);
Aurora PostgreSQL Limitless Database は、シャードテーブル名に対して最大 54 文字をサポートします。
CREATE TABLE AS
CREATE TABLE AS を使用してテーブルを作成するには、rds_aurora.limitless_create_table_mode 変数を使用する必要があります。シャードテーブルの場合は、rds_aurora.limitless_create_table_shard_key 変数も使用する必要があります。詳細については、「変数を使用した無制限テーブルの作成」を参照してください。
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; CREATE TABLE ctas_table AS SELECT 1 a; -- "source" is the source table whose columns and data types are used to create the new "ctas_table2" table. CREATE TABLE ctas_table2 AS SELECT a,b FROM source;
リファレンステーブルはプライマリキーの制約を必要とするため、CREATE TABLE AS を使用してリファレンステーブルを作成することはできません。CREATE TABLE
AS はプライマリキーを新しいテーブルに伝播しません。
詳細については、PostgreSQL ドキュメントの「CREATE TABLE AS
DROP DATABASE
作成したデータベースを削除できます。
DROP DATABASE コマンドはバックグラウンドで非同期的に実行されます。実行中に、同じ名前で新しいデータベースを作成しようとすると、エラーが発生します。
SELECT INTO
SELECT INTO は機能的に CREATE TABLE AS と似ています。rds_aurora.limitless_create_table_mode 変数を使用する必要があります シャードテーブルの場合は、rds_aurora.limitless_create_table_shard_key 変数も使用する必要があります。詳細については、「変数を使用した無制限テーブルの作成」を参照してください。
-- Set the variables. SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"a"}'; -- "source" is the source table whose columns and data types are used to create the new "destination" table. SELECT * INTO destination FROM source;
現在、SELECT INTO オペレーションはシャードから直接ではなく、ルーターを介して実行されます。そのため、パフォーマンスが低下する可能性があります。
詳細については、PostgreSQL ドキュメントの「SELECT INTO
制約
Aurora PostgreSQL Limitless Database の制約には、次の制限が適用されます。
- CHECK
-
リテラルとの比較演算子を含むシンプルな制約はサポートされています。次の例に示すように、関数の検証を必要とするより複雑な式や制約はサポートされていません。
CREATE TABLE my_table ( id INT CHECK (id > 0) -- supported , val INT CHECK (val > 0 AND val < 1000) -- supported , tag TEXT CHECK (length(tag) > 0) -- not supported: throws "Expression inside CHECK constraint is not supported" , op_date TIMESTAMP WITH TIME ZONE CHECK (op_date <= now()) -- not supported: throws "Expression inside CHECK constraint is not supported" );次の例に示すように、制約に明示的な名前を付けることができます。
CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , val INT CONSTRAINT val_in_range CHECK (val > 0 AND val < 1000) );次の例に示すように、
CHECK制約でテーブルレベルの制約構文を使用できます。CREATE TABLE my_table ( id INT CONSTRAINT positive_id CHECK (id > 0) , min_val INT CONSTRAINT min_val_in_range CHECK (min_val > 0 AND min_val < 1000) , max_val INT , CONSTRAINT max_val_in_range CHECK (max_val > 0 AND max_val < 1000 AND max_val > min_val) ); - EXCLUDE
-
除外制約は、Aurora PostgreSQL Limitless Database ではサポートされていません。
- 外部キー
-
詳細については、「外部キー」を参照してください。
- NOT NULL
-
NOT NULL制約は制限なしでサポートされています。 - PRIMARY KEY
-
プライマリキーは一意制約を意味するため、一意制約と同じ制限がプライマリキーに適用されます。つまり、次のようになります。
-
テーブルがシャードテーブルに変換される場合、シャードキーはプライマリキーのサブセットである必要があります。つまり、プライマリキーにはシャードキーのすべての列が含まれます。
-
テーブルがリファレンステーブルに変換される場合は、プライマリキーが必要です。
次の例は、プライマリキーの使用を示しています。
-- Create a standard table. CREATE TABLE public.my_table ( item_id INT , location_code INT , val INT , comment text ); -- Change the table to a sharded table using the 'item_id' and 'location_code' columns as shard keys. CALL rds_aurora.limitless_alter_table_type_sharded('public.my_table', ARRAY['item_id', 'location_code']);シャードキーを含まないプライマリキーを追加しようとしています。
-- Add column 'item_id' as the primary key. -- Invalid because the primary key doesnt include all columns from the shard key: -- 'location_code' is part of the shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERROR -- add column "val" as primary key -- Invalid because primary key does not include all columns from shard key: -- item_id and location_code iare part of shard key but not part of the primary key ALTER TABLE public.my_table ADD PRIMARY KEY (item_id); -- ERRORシャードキーを含むプライマリキーを追加しようとしています。
-- Add the 'item_id' and 'location_code' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code); -- OK -- Add the 'item_id', 'location_code', and 'val' columns as the primary key. -- Valid because the primary key contains the shard key. ALTER TABLE public.my_table ADD PRIMARY KEY (item_id, location_code, val); -- OK標準テーブルをリファレンステーブルに変更します。
-- Create a standard table. CREATE TABLE zipcodes (zipcode INT PRIMARY KEY, details VARCHAR); -- Convert the table to a reference table. CALL rds_aurora.limitless_alter_table_type_reference('public.zipcode');シャードテーブルとリファレンステーブルの作成の詳細については、「Aurora PostgreSQL Limitless Database テーブルの作成」を参照してください。
-
- UNIQUE
-
シャードテーブルでは、一意のキーにシャードキーが含まれている必要があります。つまり、シャードキーは一意のキーのサブセットである必要があります。これは、テーブルタイプをシャードに変更するときにチェックされます。リファレンステーブルには制限はありません。
CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT UNIQUE );次の例に示すように、テーブルレベルの
UNIQUE制約がサポートされています。CREATE TABLE customer ( customer_id INT NOT NULL , zipcode INT , email TEXT , CONSTRAINT zipcode_and_email UNIQUE (zipcode, email) );次の例は、プライマリキーと一意のキーの併用を示しています。両方のキーにシャードキーが含まれている必要があります。
SET rds_aurora.limitless_create_table_mode='sharded'; SET rds_aurora.limitless_create_table_shard_key='{"p_id"}'; CREATE TABLE t1 ( p_id BIGINT NOT NULL, c_id BIGINT NOT NULL, PRIMARY KEY (p_id), UNIQUE (p_id, c_id) );
詳細については、PostgreSQL ドキュメントの「Constraints
デフォルト値
Aurora PostgreSQL Limitless Database は、デフォルト値の式をサポートしています。
次の例は、デフォルト値の使用を示しています。
CREATE TABLE t ( a INT DEFAULT 5, b TEXT DEFAULT 'NAN', c NUMERIC ); CALL rds_aurora.limitless_alter_table_type_sharded('t', ARRAY['a']); INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c ---+-----+--- 5 | NAN | (1 row)
次の例に示すように、式がサポートされています。
CREATE TABLE t1 (a NUMERIC DEFAULT random());
次の例では、NOT NULL で、デフォルト値を持つ新しい列を追加します。
ALTER TABLE t ADD COLUMN d BOOLEAN NOT NULL DEFAULT FALSE; SELECT * FROM t; a | b | c | d ---+-----+---+--- 5 | NAN | | f (1 row)
次の例では、デフォルト値で既存の列を変更します。
ALTER TABLE t ALTER COLUMN c SET DEFAULT 0.0; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f (2 rows)
次の例では、デフォルト値を削除します。
ALTER TABLE t ALTER COLUMN a DROP DEFAULT; INSERT INTO t DEFAULT VALUES; SELECT * FROM t; a | b | c | d ---+-----+-----+----- 5 | NAN | | f 5 | NAN | 0.0 | f | NAN | 0.0 | f (3 rows)
詳細については、PostgreSQL ドキュメントの「Default values
拡張子
Aurora PostgreSQL Limitless Database では、次の PostgreSQL 拡張機能がサポートされています。
-
aurora_limitless_fdw– この拡張機能はプリインストールされています。削除することはできません。 -
aws_s3– この拡張機能は、Aurora PostgreSQL と同様に Aurora PostgreSQL Limitless Database で動作します。Amazon S3 バケットから Aurora PostgreSQL Limitless Database DB クラスターにデータをインポートするか、Aurora PostgreSQL Limitless Database DB クラスターから Amazon S3 バケットにデータをエクスポートします。詳細については、「Amazon S3 から Aurora PostgreSQL DB クラスター にデータをインポートする」および「Aurora PostgreSQL DB クラスターから Amazon S3 へのデータのエクスポート」を参照してください。
-
btree_gin -
citext -
ip4r -
pg_buffercache– この拡張機能は、Aurora PostgreSQL Limitless Database とコミュニティ PostgreSQL では動作が異なります。詳細については、「Aurora PostgreSQL Limitless Database での pg_buffercache の違い」を参照してください。 -
pg_stat_statements -
pg_trgm -
pgcrypto -
pgstattuple– この拡張機能は、Aurora PostgreSQL Limitless Database とコミュニティ PostgreSQL では動作が異なります。詳細については、「Aurora PostgreSQL Limitless Database での pgstattuple の違い」を参照してください。 -
pgvector -
plpgsql– この拡張機能はプリインストールされていますが、削除できます。 -
PostGIS– 長いトランザクションとテーブル管理機能はサポートされていません。空間リファレンステーブルの変更はサポートされていません。 -
unaccent -
uuid
現在、ほとんどの PostgreSQL 拡張機能は Aurora PostgreSQL Limitless Database ではサポートされていません。ただし、shared_preload_libraries
例えば、pg_hint_plan 拡張機能をロードすることはできますが、ロードしても、クエリコメントで渡されたヒントが使用されるとは限りません。
注記
pg_stat_statementspg_stat_statements のインストールの詳細については、「limitless_stat_statements」を参照してください。
pg_available_extensions および pg_available_extension_versions 関数を使用して、Aurora PostgreSQL Limitless Database でサポートされている拡張機能を検索できます。
以下の DDL は拡張機能に対してサポートされています。
- CREATE EXTENSION
-
PostgreSQL と同様に、拡張機能を作成できます。
CREATE EXTENSION [ IF NOT EXISTS ]extension_name[ WITH ] [ SCHEMAschema_name] [ VERSIONversion] [ CASCADE ]詳細については、PostgreSQL ドキュメントの「CREATE EXTENSION
」を参照してください。 - ALTER EXTENSION
-
次の DDL がサポートされています。
ALTER EXTENSIONnameUPDATE [ TOnew_version] ALTER EXTENSIONnameSET SCHEMAnew_schema詳細については、PostgreSQL ドキュメントの「ALTER EXTENSION
」を参照してください。 - DROP EXTENSION
-
PostgreSQL と同様に、拡張機能を削除できます。
DROP EXTENSION [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]詳細については、PostgreSQL ドキュメントの「DROP EXTENSION
」を参照してください。
以下の DDL は拡張機能に対してサポートされません。
- ALTER EXTENSION
-
拡張機能からメンバーオブジェクトを追加または削除することはできません。
ALTER EXTENSIONnameADDmember_objectALTER EXTENSIONnameDROPmember_object
Aurora PostgreSQL Limitless Database での pg_buffercache の違い
Aurora PostgreSQL Limitless Database では、pg_buffercachepg_buffercache ビューを使用すると、現在接続されているノード、つまりルーターからのみバッファ関連の情報を受信します。同様に、関数 pg_buffercache_summary または pg_buffercache_usage_counts を使用すると、接続されたノードからの情報のみが提供されます。
多数のノードがあり、問題を効果的に診断するために任意のノードからバッファ情報にアクセスする必要がある場合があります。そのため、Limitless Database には次の関数が用意されています。
-
rds_aurora.limitless_pg_buffercache(subcluster_id) -
rds_aurora.limitless_pg_buffercache_summary(subcluster_id) -
rds_aurora.limitless_pg_buffercache_usage_counts(subcluster_id)
任意のノードのサブクラスター ID を入力することで、ルーターでもシャードでも、そのノードに固有のバッファ情報に簡単にアクセスできます。これらの関数は、制限なしのデータベースに pg_buffercache 拡張機能をインストールするときに直接使用できます。
注記
Aurora PostgreSQL Limitless Database では、pg_buffercache 拡張機能のバージョン 1.4 以降でこれらの関数がサポートされます。
limitless_pg_buffercache ビューに表示される列は、pg_buffercache ビューの列とは若干異なります。
-
bufferid-pg_buffercacheから変更されません。 -
relname– ファイルノード番号をpg_buffercacheのように表示する代わりに、limitless_pg_buffercacheは現在のデータベースまたは共有システムカタログで使用可能な場合は関連付けられたrelnameを表示し、それ以外の場合はNULLを表示します。 -
parent_relname–pg_buffercacheに存在しないこの新しい列には、relname列の値がパーティションテーブルを表す場合 (シャードテーブルの場合)、親relnameが表示されます。それ以外の場合は、NULLが表示されます。 -
spcname– テーブルスペースオブジェクト識別子 (OID) をpg_buffercacheのように表示する代わりに、limitless_pg_buffercacheはテーブルスペース名を表示します。 -
datname– データベース OID をpg_buffercacheのように表示する代わりに、limitless_pg_buffercacheはデータベース名を表示します。 -
relforknumber-pg_buffercacheから変更されません。 -
relblocknumber-pg_buffercacheから変更されません。 -
isdirty-pg_buffercacheから変更されません。 -
usagecount-pg_buffercacheから変更されません。 -
pinning_backends-pg_buffercacheから変更されません。
limitless_pg_buffercache_summary ビューと limitless_pg_buffercache_usage_counts ビューの列は、それぞれ通常の pg_buffercache_summary ビューと pg_buffercache_usage_counts ビューの列と同じです。
これらの関数を使用すると、Limitless Database 環境内のすべてのノードの詳細なバッファキャッシュ情報にアクセスでき、データベースシステムの診断と管理をより効果的に行えます。
Aurora PostgreSQL Limitless Database での pgstattuple の違い
Aurora PostgreSQL では、pgstattuple
AWS では、タプルレベルの統計を取得するためのこの拡張機能の重要性を認識しています。こうした統計は、肥大化の排除や診断情報の収集などのタスクに不可欠です。そのため、Aurora PostgreSQL Limitless Database は、制限のないデータベースで pgstattuple 拡張機能をサポートします。
Aurora PostgreSQL Limitless Database には、rds_aurora スキーマに次の関数が含まれています。
- タプルレベルの統計関数
-
rds_aurora.limitless_pgstattuple(relation_name)-
目的: 標準テーブルとそのインデックスのタプルレベルの統計を抽出する
-
入力:
relation_name(テキスト) - リレーションの名前 -
出力: Aurora PostgreSQL の
pgstattuple関数によって返される列と一致する列
rds_aurora.limitless_pgstattuple(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブル、およびインデックスのタプルレベルの統計を抽出する
-
入力:
-
relation_name(テキスト) - リレーションの名前 -
subcluster_id(テキスト) – 統計を抽出するノードのサブクラスター ID
-
-
出力:
-
リファレンステーブルとカタログテーブル (インデックスを含む) の場合、列は Aurora PostgreSQL の列と一致します。
-
シャードテーブルの場合、統計は、指定されたサブクラスターに存在するシャードテーブルのパーティションのみを表します。
-
-
- インデックス統計関数
-
rds_aurora.limitless_pgstatindex(relation_name)-
目的: 標準テーブルの B ツリーインデックスの統計を抽出する
-
入力:
relation_name(テキスト) - B ツリーインデックスの名前 -
出力:
root_block_noを除くすべての列が返されます。返される列は、Aurora PostgreSQL のpgstatindex関数と一致します。
rds_aurora.limitless_pgstatindex(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブルの B ツリーインデックスの統計を抽出する。
-
入力:
-
relation_name(テキスト) – B ツリーインデックスの名前 -
subcluster_id(テキスト) – 統計を抽出するノードのサブクラスター ID
-
-
出力:
-
リファレンステーブルとカタログテーブルインデックスの場合、すべての列 (
root_block_noを除く) が返されます。返される列は Aurora PostgreSQL と一致します。 -
シャードテーブルの場合、統計は、指定されたサブクラスターに存在するシャードテーブルインデックスのパーティションのみを表します。
tree_level列には、リクエストされたサブクラスターのすべてのテーブルスライスの平均が表示されます。
-
rds_aurora.limitless_pgstatginindex(relation_name)-
目的: 標準テーブルの一般化逆インデックス (GIN) の統計を抽出する
-
入力:
relation_name(テキスト) – GIN の名前 -
出力: Aurora PostgreSQL の
pgstatginindex関数によって返される列と一致する列
rds_aurora.limitless_pgstatginindex(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブルの GIN インデックスの統計を抽出する。
-
入力:
-
relation_name(テキスト) – インデックスの名前 -
subcluster_id(テキスト) – 統計を抽出するノードのサブクラスター ID
-
-
出力:
-
リファレンステーブルとカタログテーブルの GIN インデックスの場合、列は Aurora PostgreSQL の列と一致します。
-
シャードテーブルの場合、統計は、指定されたサブクラスターに存在するシャードテーブルインデックスのパーティションのみを表します。
-
rds_aurora.limitless_pgstathashindex(relation_name)-
目的: 標準テーブルのハッシュインデックスの統計を抽出する
-
入力:
relation_name(テキスト) – ハッシュインデックスの名前 -
出力: Aurora PostgreSQL の
pgstathashindex関数によって返される列と一致する列
rds_aurora.limitless_pgstathashindex(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブルのハッシュインデックスの統計を抽出する。
-
入力:
-
relation_name(テキスト) – インデックスの名前 -
subcluster_id(テキスト) – 統計を抽出するノードのサブクラスター ID
-
-
出力:
-
リファレンステーブルととカタログテーブルのハッシュインデックスの場合、列は Aurora PostgreSQL の列と一致します。
-
シャードテーブルの場合、統計は、指定されたサブクラスターに存在するシャードテーブルインデックスのパーティションのみを表します。
-
-
- ページ数関数
-
rds_aurora.limitless_pg_relpages(relation_name)-
目的: 標準テーブルとそのインデックスのページ数を抽出する
-
入力:
relation_name(テキスト) - リレーションの名前 -
出力: 指定されたリレーションのページ数
rds_aurora.limitless_pg_relpages(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブル (そのインデックスを含む) のページ数を抽出する
-
入力:
-
relation_name(テキスト) - リレーションの名前 -
subcluster_id(テキスト) – ページ数が抽出されるノードのサブクラスター ID
-
-
出力: シャードテーブルの場合、ページ数は、指定されたサブクラスターのすべてのテーブルスライスのページ数の合計です。
-
- 概算のタプルレベルの統計関数
-
rds_aurora.limitless_pgstattuple_approx(relation_name)-
目的: 標準テーブルとそのインデックスの概算のタプルレベルの統計を抽出する
-
入力:
relation_name(テキスト) - リレーションの名前 -
出力: Aurora PostgreSQL の pgstattuple_approx 関数によって返される列と一致する列
rds_aurora.limitless_pgstattuple_approx(relation_name,subcluster_id)-
目的: リファレンステーブル、シャードテーブル、カタログテーブル (そのインデックスを含む) の概算のタプルレベルの統計を抽出する
-
入力:
-
relation_name(テキスト) - リレーションの名前 -
subcluster_id(テキスト) – 統計を抽出するノードのサブクラスター ID
-
-
出力:
-
リファレンステーブルとカタログテーブル (インデックスを含む) の場合、列は Aurora PostgreSQL の列と一致します。
-
シャードテーブルの場合、統計は、指定されたサブクラスターに存在するシャードテーブルのパーティションのみを表します。
-
-
注記
現在、Aurora PostgreSQL Limitless Database は、マテリアライズドビュー、TOAST テーブル、または一時テーブルの pgstattuple 拡張機能をサポートしていません。
Aurora PostgreSQL Limitless Database では、入力をテキストとして指定する必要がありますが、Aurora PostgreSQL は他の形式もサポートしています。
外部キー
外部キー (FOREIGN KEY) の制約は、いくつかの制限付きでサポートされています。
-
FOREIGN KEYを使ったCREATE TABLEは、標準テーブルでのみサポートされています。FOREIGN KEYを使ってシャードテーブルまたはリファレンステーブルを作成するには、まず外部キーの制約なしでテーブルを作成します。次に、次のステートメントを使用して変更します。ALTER TABLE ADD CONSTRAINT; -
テーブルに外部キー制約がある場合、標準テーブルをシャードテーブルまたはリファレンステーブルに変換することはサポートされていません。制約を削除し、変換後に追加します。
-
外部キー制約のテーブルタイプには、次の制限が適用されます。
-
標準テーブルには、別の標準テーブルへの外部キー制約を含めることができます。
-
親テーブルと子テーブルがコロケーションされ、外部キーがシャードキーのスーパーセットである場合、シャードテーブルには外部キー制約を含めることができます。
-
シャードテーブルには、リファレンステーブルへの外部キー制約を含めることができます。
-
リファレンステーブルには、別のリファレンステーブルへの外部キー制約を含めることができます。
-
外部キーオプション
Aurora PostgreSQL Limitless Database では、一部の DDL オプションで外部キーがサポートされています。次の表では、Aurora PostgreSQL Limitless Database テーブル間でサポートされるオプションと、サポートされないオプションを示しています。
| DDL オプション | リファレンスからリファレンス | シャードからシャード (コロケーション) | シャードからリファレンス | 標準から標準 |
|---|---|---|---|---|
|
|
可能 | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
いいえ | いいえ | いいえ | なし |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
はい | いいえ | なし | はい |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
いいえ | いいえ | いいえ | なし |
|
|
はい | いいえ | なし | はい |
|
|
いいえ | いいえ | なし | はい |
|
|
はい | はい | はい | はい |
|
|
はい | はい | はい | はい |
|
|
いいえ | いいえ | いいえ | なし |
|
|
はい | いいえ | なし | はい |
例
-
標準から標準:
set rds_aurora.limitless_create_table_mode='standard'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer REFERENCES products (product_no), quantity integer ); SELECT constraint_name, table_name, constraint_type FROM information_schema.table_constraints WHERE constraint_type='FOREIGN KEY'; constraint_name | table_name | constraint_type -------------------------+-------------+----------------- orders_product_no_fkey | orders | FOREIGN KEY (1 row) -
シャードからシャード (コロケーション):
set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"product_no"}'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; set rds_aurora.limitless_create_table_collocate_with='products'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
シャードからリファレンス:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); set rds_aurora.limitless_create_table_mode='sharded'; set rds_aurora.limitless_create_table_shard_key='{"order_id"}'; CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no); -
リファレンスからリファレンス:
set rds_aurora.limitless_create_table_mode='reference'; CREATE TABLE products( product_no integer PRIMARY KEY, name text, price numeric ); CREATE TABLE orders ( order_id integer PRIMARY KEY, product_no integer, quantity integer ); ALTER TABLE orders ADD CONSTRAINT order_product_fk FOREIGN KEY (product_no) REFERENCES products (product_no);
関数
関数は、Aurora PostgreSQL Limitless Database でサポートされています。
次の DDL は関数に対してサポートされています。
- CREATE FUNCTION
-
Aurora PostgreSQL と同様に関数を作成できますが、関数を置き換える際の可変性の変更は除きます。
詳細については、PostgreSQL のドキュメントの「機能の作成
」を参照してください。 - ALTER FUNCTION
-
Aurora PostgreSQL と同様に関数を変更できますが、可変性の変更は除きます。
詳細については、PostgreSQL ドキュメントの「ALTER FUNCTION
」を参照してください。 - DROP FUNCTION
-
Aurora PostgreSQL と同様に関数を削除できます。
DROP FUNCTION [ IF EXISTS ]name[ ( [ [argmode] [argname]argtype[, ...] ] ) ] [, ...] [ CASCADE | RESTRICT ]詳細については、PostgreSQL ドキュメントの「DROP FUNCTION
」を参照してください。
関数の分散
関数のすべてのステートメントが 1 つのシャードを対象とする場合、関数全体をターゲットシャードにプッシュダウンすると有益です。その場合、ルーター自体で関数を解決するのではなく、結果はルーターに伝播されます。関数とストアドプロシージャのプッシュダウン機能は、シャードであるデータソースの近くで関数またはストアドプロシージャを実行したい場合に便利です。
関数を分散させるには、まず関数を作成してから、関数を分散するための rds_aurora.limitless_distribute_function プロシージャを呼び出します。この関数では次の構文を使用します。
SELECT rds_aurora.limitless_distribute_function('function_prototype', ARRAY['shard_key'], 'collocating_table');
関数では以下のパラメータを使用します。
-
function_prototypeいずれかの引数が
OUTパラメータとして定義されている場合は、function_prototypeの引数にその型を含めないでください。 -
ARRAY['– 関数のシャードキーとして識別される関数引数のリスト。shard_key'] -
collocating_table
この関数を実行するためにどのシャードにプッシュダウンするかを識別するため、システムは ARRAY[' 引数を取得し、これをハッシュ化して、このハッシュ値を含む範囲をホストする shard_key']collocating_table
- 制限事項
-
関数またはプロシージャを分散させる場合、関数またはプロシージャはそのシャード内のシャードキー範囲によって制限されるデータのみを扱います。関数またはプロシージャが別のシャードからデータにアクセスしようとする場合、分散関数または分散プロシージャによって返される結果は、分散されていない場合とは異なります。
例えば、複数のシャードにアクセスするクエリを含む関数を作成し、
rds_aurora.limitless_distribute_functionプロシージャを呼び出して分散させる場合です。シャードキーの引数を指定してこの関数を呼び出すと、実行の結果がそのシャードに存在する値によって制限される可能性があります。これらの結果は、関数を分散させずに生成された結果とは異なります。 - 例
-
シャードキー
customer_idを持つシャードテーブルcustomersがある場合の次の関数funcについて考えてみます。postgres_limitless=> CREATE OR REPLACE FUNCTION func(c_id integer, sc integer) RETURNS int language SQL volatile AS $$ UPDATE customers SET score = sc WHERE customer_id = c_id RETURNING score; $$;次に、この関数を分散させます。
SELECT rds_aurora.limitless_distribute_function('func(integer, integer)', ARRAY['c_id'], 'customers');以下はクエリプランの例です。
EXPLAIN(costs false, verbose true) SELECT func(27+1,10); QUERY PLAN -------------------------------------------------- Foreign Scan Output: (func((27 + 1), 10)) Remote SQL: SELECT func((27 + 1), 10) AS func Single Shard Optimized (4 rows)EXPLAIN(costs false, verbose true) SELECT * FROM customers,func(customer_id, score) WHERE customer_id=10 AND score=27; QUERY PLAN --------------------------------------------------------------------- Foreign Scan Output: customer_id, name, score, func Remote SQL: SELECT customers.customer_id, customers.name, customers.score, func.func FROM public.customers, LATERAL func(customers.customer_id, customers.score) func(func) WHERE ((customers.customer_id = 10) AND (customers.score = 27)) Single Shard Optimized (10 rows)次の例は、
INとOUTパラメータを引数に持つプロシージャを示しています。CREATE OR REPLACE FUNCTION get_data(OUT id INTEGER, IN arg_id INT) AS $$ BEGIN SELECT customer_id, INTO id FROM customer WHERE customer_id = arg_id; END; $$ LANGUAGE plpgsql;次の例では、
INパラメータのみを使用してプロシージャを分散させます。EXPLAIN(costs false, verbose true) SELECT * FROM get_data(1); QUERY PLAN ----------------------------------- Foreign Scan Output: id Remote SQL: SELECT customer_id FROM get_data(1) get_data(id) Single Shard Optimized (6 rows)
関数の可変性
関数が Immutable、Stable、または Volatile であるかを確認するには、pg_procprovolatile 値をチェックすることができます。provolatile 値は、関数の結果が入力引数のみに依存するか、外部要因の影響を受けるかを示します。
値は次のいずれかです。
-
i– Immutable 関数。同じ入力に対して常に同じ結果を提供します。 -
s– Stable 関数。スキャン内で (固定された入力に対する) 結果が変わりません。 -
v– Volatile 関数。結果がいつでも変わる可能性があります。また、副作用のある関数でvを使用すると、関数への呼び出しが最適化されません。
次の例は、Volatile 関数を示しています。
SELECT proname, provolatile FROM pg_proc WHERE proname='pg_sleep'; proname | provolatile ----------+------------- pg_sleep | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='uuid_generate_v4'; proname | provolatile ------------------+------------- uuid_generate_v4 | v (1 row) SELECT proname, provolatile FROM pg_proc WHERE proname='nextval'; proname | provolatile ---------+------------- nextval | v (1 row)
既存の関数のボラティリティの変更は、Aurora PostgreSQL Limitless Database ではサポートされていません。これは、次の例に示すように、ALTER FUNCTION コマンドと CREATE OR REPLACE FUNCTION コマンドの両方に適用されます。
-- Create an immutable function CREATE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$IMMUTABLE; -- Altering the volatility throws an error ALTER FUNCTION immutable_func1 STABLE; -- Replacing the function with altered volatility throws an error CREATE OR REPLACE FUNCTION immutable_func1(name text) RETURNS text language plpgsql AS $$ BEGIN RETURN name; END; $$VOLATILE;
関数に正しいボラティリティーを割り当てることを強くお勧めします。例えば、関数が複数のテーブルから SELECT を使用したり、データベースオブジェクトを参照したりする場合は、IMMUTABLE として設定しないでください。テーブルの内容が一度でも変更されると、イミュータビリティが壊れます。
Aurora PostgreSQL は Immutable 関数内で SELECT を許可しますが、結果が正しくない可能性があります。Aurora PostgreSQL Limitless Database が、エラーと誤った結果の両方を返す可能性があります。詳細については、PostgreSQL ドキュメントの「Function volatility categories
シーケンス
名前付きシーケンスは、昇順または降順で一意の番号を生成するデータベースオブジェクトです。CREATE SEQUENCE は新しいシーケンス番号ジェネレーターを作成します。シーケンスの値は一意であることが保証されています。
Aurora PostgreSQL Limitless Database で名前付きシーケンスを作成すると、分散シーケンスオブジェクトが作成されます。次に、Aurora PostgreSQL Limitless Database は、シーケンス値の重複しないチャンクをすべての分散トランザクションルーター (ルーター) に分散します。チャンクはルーター上のローカルシーケンスオブジェクトとして表されるため、nextval や currval などのシーケンスオペレーションはローカルで実行されます。ルーターは独立して動作し、必要に応じて分散シーケンスから新しいチャンクをリクエストします。
シーケンスの詳細については、PostgreSQL ドキュメントの「CREATE SEQUENCE
新しいチャンクのリクエスト
ルーターに割り当てられたチャンクのサイズを設定するには、rds_aurora.limitless_sequence_chunk_size パラメータを使用します。デフォルト値は 250000 です。各ルーターは、最初にアクティブとリザーブドの 2 つのチャンクを所有しています。アクティブチャンクはローカルシーケンスオブジェクトの設定 (minvalue および maxvalue の設定) に使用され、予約済みチャンクは内部カタログテーブルに保存されます。アクティブチャンクが最小値または最大値に達すると、予約済みチャンクに置き換えられます。そのために、内部で ALTER SEQUENCE が使用され、これにより AccessExclusiveLock が取得されます。
バックグラウンドワーカーは、ルーターノードで 10 秒ごとに実行され、使用済みの予約済みチャンクのシーケンスをスキャンします。使用済みチャンクが見つかった場合、ワーカーは分散シーケンスから新しいチャンクをリクエストします。バックグラウンドワーカーが新しいチャンクをリクエストするのに十分な時間を確保できるように、チャンクサイズを十分な大きさに設定してください。リモートリクエストはユーザーセッションのコンテキストでは発生しません。つまり、新しいシーケンスを直接リクエストすることはできません。
制限事項
Aurora PostgreSQL Limitless Database のシーケンスには、次の制限が適用されます。
-
pg_sequenceカタログ、pg_sequences関数、およびSELECT * FROMステートメントはいずれも、ローカルのシーケンス状態のみを表示し、分散状態は表示しません。sequence_name -
シーケンス値は一意であることが保証されており、セッション内で単調であることが保証されています。ただし、他のセッションが他のルーターに接続されている場合、他のセッションで
nextvalステートメントが実行されると順不同になる可能性があります。 -
シーケンスサイズ (使用可能な値の数) が、すべてのルーターに分散するのに十分な大きさであることを確認してください。
rds_aurora.limitless_sequence_chunk_sizeパラメータを使用して、chunk_sizeを設定します。(各ルーターには 2 つのチャンクがあります。) -
CACHEオプションはサポートされていますが、キャッシュはchunk_sizeより小さくなければなりません。
サポートされていないオプション
以下のオプションは、Aurora PostgreSQL Limitless Database のシーケンスではサポートされていません。
- シーケンス操作関数
-
setval関数はサポートされていません。詳細については、PostgreSQL ドキュメントの「Sequence Manipulation Functions」を参照してください。 - CREATE SEQUENCE
-
次のオプションはサポートされていません。
CREATE [{ TEMPORARY | TEMP} | UNLOGGED] SEQUENCE [[ NO ] CYCLE]詳細については、PostgreSQL ドキュメントの「CREATE SEQUENCE
」を参照してください。 - ALTER SEQUENCE
-
次のオプションはサポートされていません。
ALTER SEQUENCE [[ NO ] CYCLE]詳細については、PostgreSQL ドキュメントの「ALTER SEQUENCE
」を参照してください。 - ALTER TABLE
-
ALTER TABLEコマンドはシーケンスではサポートされていません。
例
- CREATE/DROP SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 1 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16960 | 20 | 1 | 1 | 10000 | 1 | 1 | f (1 row) % connect to another router postgres_limitless=> SELECT nextval('s'); nextval --------- 10001 (1 row) postgres_limitless=> SELECT * FROM pg_sequence WHERE seqrelid='s'::regclass; seqrelid | seqtypid | seqstart | seqincrement | seqmax | seqmin | seqcache | seqcycle ----------+----------+----------+--------------+--------+--------+----------+---------- 16959 | 20 | 10001 | 1 | 20000 | 10001 | 1 | f (1 row) postgres_limitless=> DROP SEQUENCE s; DROP SEQUENCE - ALTER SEQUENCE
-
postgres_limitless=> CREATE SEQUENCE s; CREATE SEQUENCE postgres_limitless=> ALTER SEQUENCE s RESTART 500; ALTER SEQUENCE postgres_limitless=> SELECT nextval('s'); nextval --------- 500 (1 row) postgres_limitless=> SELECT currval('s'); currval --------- 500 (1 row) - シーケンス操作関数
-
postgres=# CREATE TABLE t(a bigint primary key, b bigint); CREATE TABLE postgres=# CREATE SEQUENCE s minvalue 0 START 0; CREATE SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b ---+--- 0 | 0 1 | 1 (2 rows) postgres=# ALTER SEQUENCE s RESTART 10000; ALTER SEQUENCE postgres=# INSERT INTO t VALUES (nextval('s'), currval('s')); INSERT 0 1 postgres=# SELECT * FROM t; a | b -------+------- 0 | 0 1 | 1 10000 | 10000 (3 rows)
シーケンスビュー
Aurora PostgreSQL Limitless Database では、シーケンスに対して次のビューを提供します。
- rds_aurora.limitless_distributed_sequence
-
このビューには、分散シーケンスの状態と設定が表示されます。
minvalue、maxvalue、start、inc、cache列は pg_sequencesビューと同じ意味を持ち、シーケンスの作成に使用されたオプションを表示します。 lastval列には、分散シーケンスオブジェクトの最新の割り当て値または予約値が表示されます。これは、値が既に使用されたことを意味するわけではありません。ルーターはシーケンスチャンクをローカルに保持するためです。postgres_limitless=> SELECT * FROM rds_aurora.limitless_distributed_sequence WHERE sequence_name='test_serial_b_seq'; schema_name | sequence_name | lastval | minvalue | maxvalue | start | inc | cache -------------+-------------------+---------+----------+------------+-------+-----+------- public | test_serial_b_seq | 1250000 | 1 | 2147483647 | 1 | 1 | 1 (1 row) - rds_aurora.limitless_sequence_metadata
-
このビューには、分散シーケンスメタデータが表示され、クラスターノードのシーケンスメタデータが集約されます。次の列を使用します。
-
subcluster_id– チャンクを所有するクラスターノード ID。 -
アクティブチャンク – 使用されているシーケンスのチャンク (
active_minvalue、active_maxvalue)。 -
予約済みチャンク — 次に使用されるローカルチャンク (
reserved_minvalue、reserved_maxvalue)。 -
local_last_value– ローカルシーケンスで最後に確認された値。 -
chunk_size– 作成時に設定されたチャンクのサイズ。
postgres_limitless=> SELECT * FROM rds_aurora.limitless_sequence_metadata WHERE sequence_name='test_serial_b_seq' order by subcluster_id; subcluster_id | sequence_name | schema_name | active_minvalue | active_maxvalue | reserved_minvalue | reserved_maxvalue | chunk_size | chunk_state | local_last_value ---------------+-------------------+-------------+-----------------+-----------------+-------------------+-------------------+------------+-------------+------------------ 1 | test_serial_b_seq | public | 500001 | 750000 | 1000001 | 1250000 | 250000 | 1 | 550010 2 | test_serial_b_seq | public | 250001 | 500000 | 750001 | 1000000 | 250000 | 1 | (2 rows) -
シーケンスの問題のトラブルシューティング
シーケンスで次の問題が発生する可能性があります。
- チャンクサイズが十分に大きくない
-
チャンクサイズが十分に大きく設定されておらず、トランザクションレートが高い場合、バックグラウンドワーカーは、アクティブチャンクを使い切る前に新しいチャンクをリクエストする時間が足りなくなる可能性があります。これにより、
LIMITLESS:AuroraLimitlessSequenceReplace、LWLock:LockManager、Lockrelation、LWlock:bufferscontentなどの競合イベントや待機イベントが発生する可能性があります。rds_aurora.limitless_sequence_chunk_sizeパラメータの値を大きくします。 - シーケンスキャッシュの設定が高すぎる
-
PostgreSQL では、シーケンスキャッシュはセッションレベルで行われます。各セッションは、シーケンスオブジェクトへの 1 回のアクセス中に連続するシーケンス値を割り当て、それに応じてシーケンスオブジェクトの
last_valueを増やします。その後、そのセッション内で次回nextvalを使用する際に、シーケンスオブジェクトにアクセスせずに、単純に事前に割り当てられた値を返します。セッション内で割り当てられたが使用されなかった番号は、セッションが終了すると失われ、シーケンスに「ホール」が発生します。これにより、sequence_chunk がすばやく消費され、
LIMITLESS:AuroraLimitlessSequenceReplace、LWLock:LockManager、Lockrelation、LWlock:bufferscontentなどの競合イベントや待機イベントが発生する可能性があります。シーケンスキャッシュ設定を減らします。
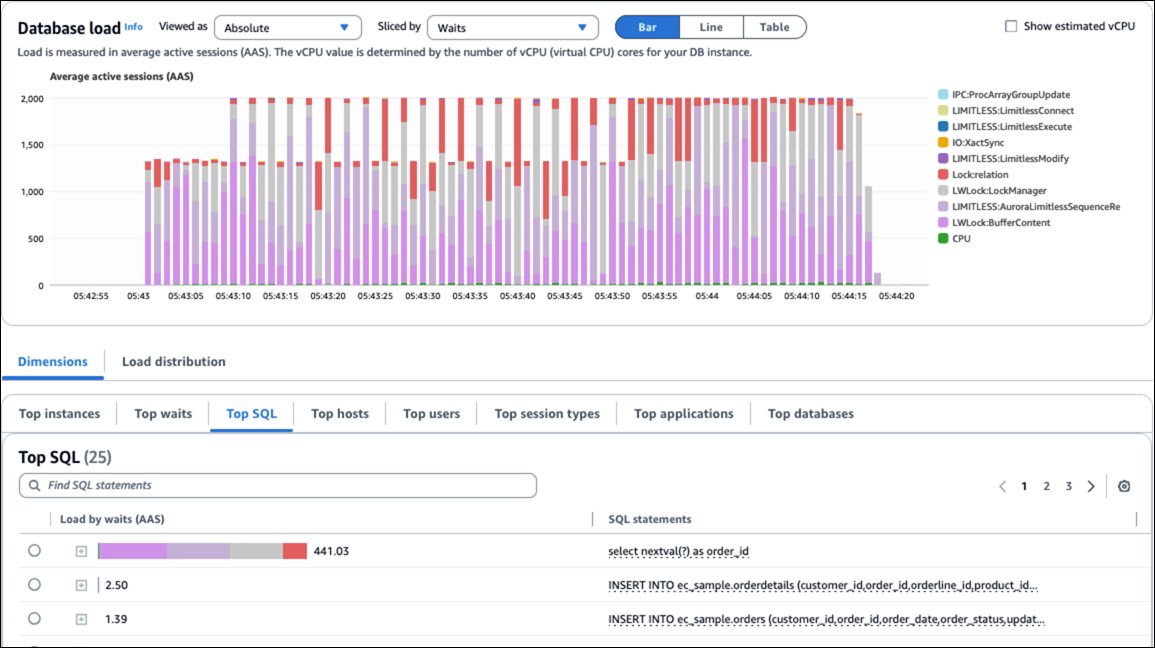
次の図は、シーケンスの問題によって発生する待機イベントを示しています。