Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Riparazioni del cluster a seguito di errori della GPU
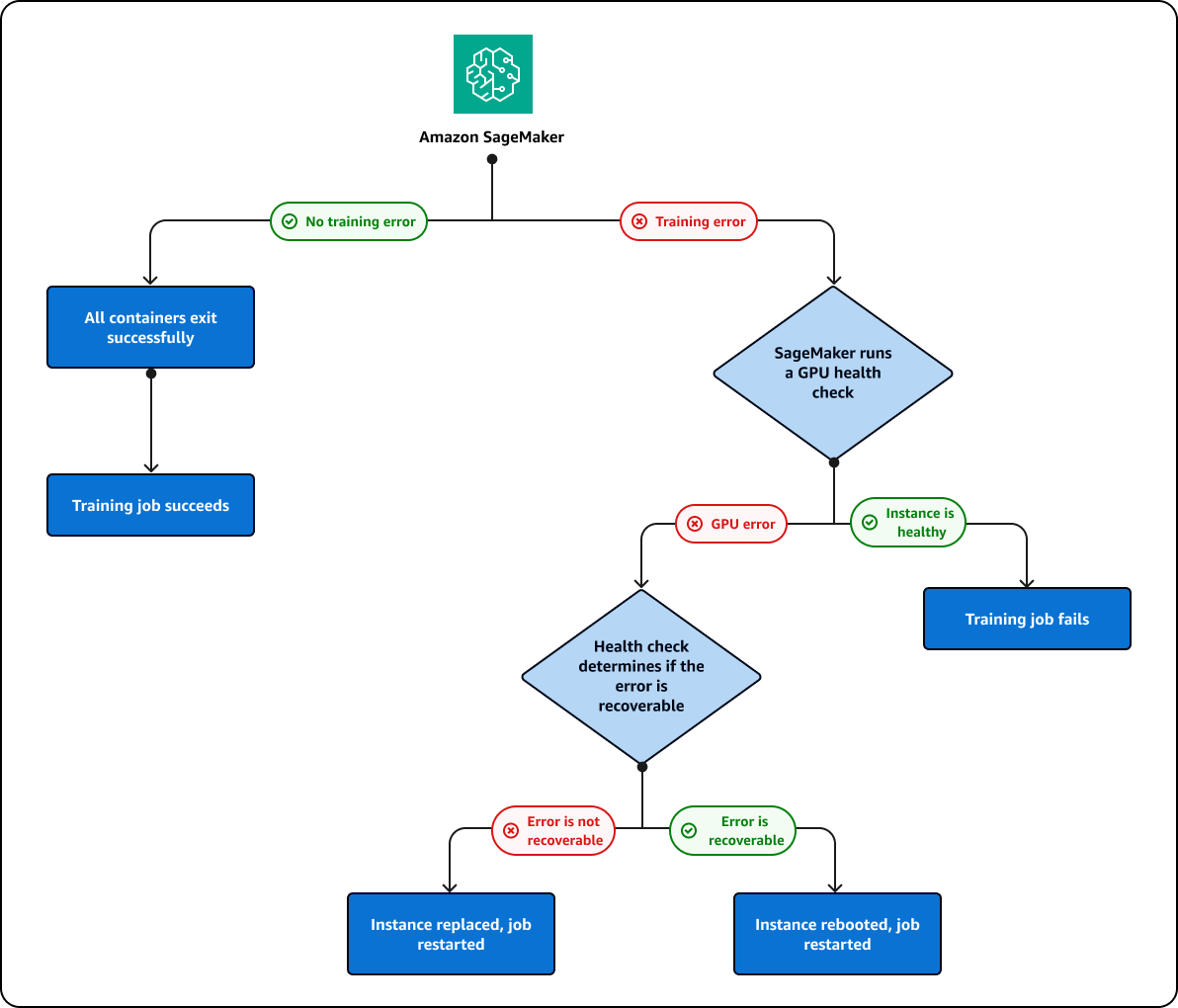
Se stai eseguendo un processo di formazione che non riesce su una GPU, SageMaker AI eseguirà un controllo dello stato della GPU per verificare se l'errore è correlato a un problema relativo alla GPU. SageMaker L'IA intraprende le seguenti azioni in base ai risultati del controllo dello stato di salute:
Se l'errore è recuperabile e può essere corretto riavviando l'istanza o reimpostando la GPU, AI riavvierà l'istanza. SageMaker
Se l'errore non è recuperabile ed è causato da una GPU che deve essere sostituita, l'intelligenza artificiale sostituirà l'istanza. SageMaker
L'istanza viene sostituita o riavviata come parte di un SageMaker processo di riparazione del cluster AI. Durante questo processo, nello stato del job di addestramento viene visualizzato il seguente messaggio:
Repairing training cluster due to hardware failure
SageMaker L'IA tenterà di riparare il cluster fino a 10 volte. Se la riparazione del cluster ha esito positivo, l' SageMaker IA riavvierà automaticamente il processo di formazione dal checkpoint precedente. Se la riparazione del cluster non riesce, anche il job di addestramento avrà esito negativo. Il processo di riparazione del cluster non viene fatturato. Le riparazioni dei cluster vengono avviate solo se il job di addestramento ha esito negativo. Se viene rilevato un problema relativo alla GPU per un cluster warmpool, il cluster entrerà in modalità di riparazione per riavviare o sostituire l’istanza difettosa. Dopo la riparazione, il cluster può ancora essere utilizzato come cluster warmpool.
Il processo di riparazione di cluster e istanze descritto in precedenza è illustrato nel diagramma seguente: