Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
GitHub archivi
Per avviare un processo di formazione, si utilizzano file provenienti da due archivi distinti GitHub:
Questi repository contengono componenti essenziali per l’avvio, la gestione e la personalizzazione dei job di addestramento dei modelli linguistici di grandi dimensioni (LLM). Utilizza gli script dei repository per configurare ed eseguire i job di addestramento per gli LLM.
HyperPod archivio di ricette
Usa l'archivio delle SageMaker HyperPod ricette
-
main.py: Questo file funge da punto di ingresso principale per l'avvio del processo di invio di un lavoro di formazione a un cluster o a un processo di formazione. SageMaker -
launcher_scripts: questa directory contiene una raccolta di script utilizzati di frequente progettati per facilitare il job di addestramento per vari modelli linguistici di grandi dimensioni (LLM). -
recipes_collection: questa cartella contiene una raccolta di ricette LLM predefinite fornite dagli sviluppatori. Gli utenti possono sfruttare queste ricette insieme ai propri dati personalizzati per addestrare modelli LLM personalizzati in base alle loro esigenze specifiche.
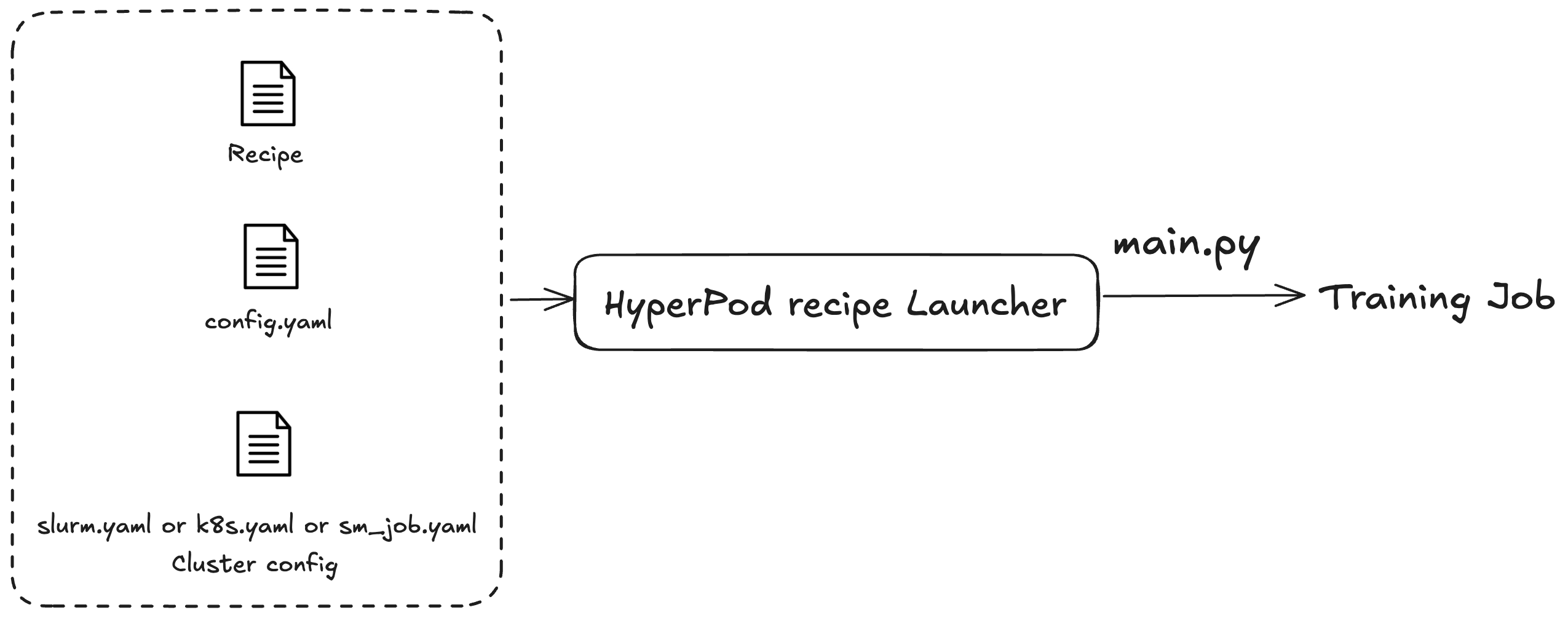
Le SageMaker HyperPod ricette vengono utilizzate per avviare lavori di formazione o perfezionamento. Indipendentemente dal cluster che stai utilizzando, il processo di invio del processo è lo stesso. Ad esempio, puoi utilizzare lo stesso script per inviare un processo a un cluster Slurm o Kubernetes. L’utilità di avvio invia un job di addestramento in base a tre file di configurazione:
-
Configurazione generale (
config.yaml): include impostazioni comuni come i parametri predefiniti o le variabili di ambiente utilizzate nel job di addestramento. -
Configurazione del cluster (cluster): per i job di addestramento che utilizzano solo i cluster. Se stai inviando un job di addestramento a un cluster Kubernetes, potresti dover specificare informazioni come volume, etichetta o policy di riavvio. Per i cluster Slurm, potrebbe essere necessario specificare il nome del processo Slurm. Tutti i parametri sono correlati al cluster specifico che stai utilizzando.
-
Ricetta (ricette): le ricette contengono le impostazioni per il job di addestramento, come i tipi di modello, il grado di sharding o i percorsi dei set di dati. Ad esempio, puoi specificare Llama come modello di addestramento e addestrarlo utilizzando tecniche di parallelizzazione del modello o dei dati come Fully Sharded Distributed Parallel (FSDP) su otto computer. Puoi anche specificare frequenze o percorsi di checkpoint diversi per il tuo job di addestramento.
Dopo aver specificato una ricetta, esegui lo script di avvio per specificare un job di addestramento completo su un cluster in base alle configurazioni attraverso il punto di ingresso main.py. Per ogni ricetta che utilizzi, sono disponibili script shell di accompagnamento nella cartella launch_scripts. Questi esempi ti guidano nelle procedure di invio e avvio dei job di addestramento. La figura seguente illustra come un lanciatore di SageMaker HyperPod ricette invia un processo di formazione a un cluster in base a quanto sopra. Attualmente, il lanciatore di SageMaker HyperPod ricette è basato su Nvidia Framework Launcher. NeMo Per ulteriori informazioni, consulta NeMo Launcher Guide.
HyperPod archivio di adattatori per ricette
L'adattatore SageMaker HyperPod di formazione è un framework di formazione. Puoi utilizzarlo per gestire l’intero ciclo di vita dei tuoi job di addestramento. Utilizza l’adattatore per implementare il preaddestramento o il fine-tuning dei modelli in più computer. L’adattatore utilizza diverse tecniche di parallelizzazione per distribuire l’addestramento. Gestisce anche l’implementazione e la gestione del salvataggio dei checkpoint. Per ulteriori dettagli, consultare Impostazioni avanzate.
Usa il repository degli adattatori per SageMaker HyperPod ricette
-
src: Questa directory contiene l'implementazione dell'addestramento Large-scale Language Model (LLM), che comprende varie funzionalità come il parallelismo dei modelli, l'addestramento a precisione mista e la gestione dei checkpoint. -
examples: questa cartella fornisce una raccolta di esempi che mostrano come creare un punto di ingresso per l’addestramento di un modello LLM e funge da guida pratica per gli utenti.
