Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Test della distribuzione
Puoi testare l'implementazione di un modello richiamando l'endpoint o effettuando singole richieste di previsione tramite l'applicazione Amazon SageMaker Canvas. Puoi utilizzare questa funzionalità per confermare che l'endpoint risponda alle richieste prima di invocarlo in modo programmatico in un ambiente di produzione.
Test di un’implementazione di un modello personalizzato
Puoi testare l’implementazione di un modello personalizzato accedendovi tramite la pagina MLOps ed effettuando una singola invocazione, che restituisce una previsione insieme alla probabilità che la previsione sia corretta.
Nota
La durata dell'esecuzione è una stima del tempo impiegato per invocare un endpoint e ottenere una risposta in Canvas. Per metriche dettagliate sulla latenza, consulta SageMaker AI Endpoint Invocation Metrics.
Per testare l'endpoint tramite l'applicazione Canvas, procedi come segue:
-
SageMaker Apri l'applicazione Canvas.
-
Nel riquadro di navigazione a sinistra, scegli MLOps.
-
Seleziona la scheda Distribuzioni.
-
Nell'elenco delle distribuzioni, scegli quella con l'endpoint che desideri invocare.
-
Nella pagina dei dettagli della distribuzione, scegli la scheda Testa distribuzione.
-
Nella pagina per testare la distribuzione, puoi modificare i campi Valore per specificare un nuovo punto dati. Per i modelli di previsione delle serie temporali, devi specificare l’ID elemento per il quale generare una previsione.
-
Dopo aver modificato i valori, scegli Aggiorna per ottenere il risultato della previsione.
La previsione viene caricata insieme ai campi Risultati dell'invocazione, che indicano se l’invocazione ha avuto esito positivo o meno e il tempo impiegato per l'elaborazione della richiesta.
Lo screenshot seguente mostra una previsione generata nell'applicazione Canvas nella scheda Testa distribuzione.
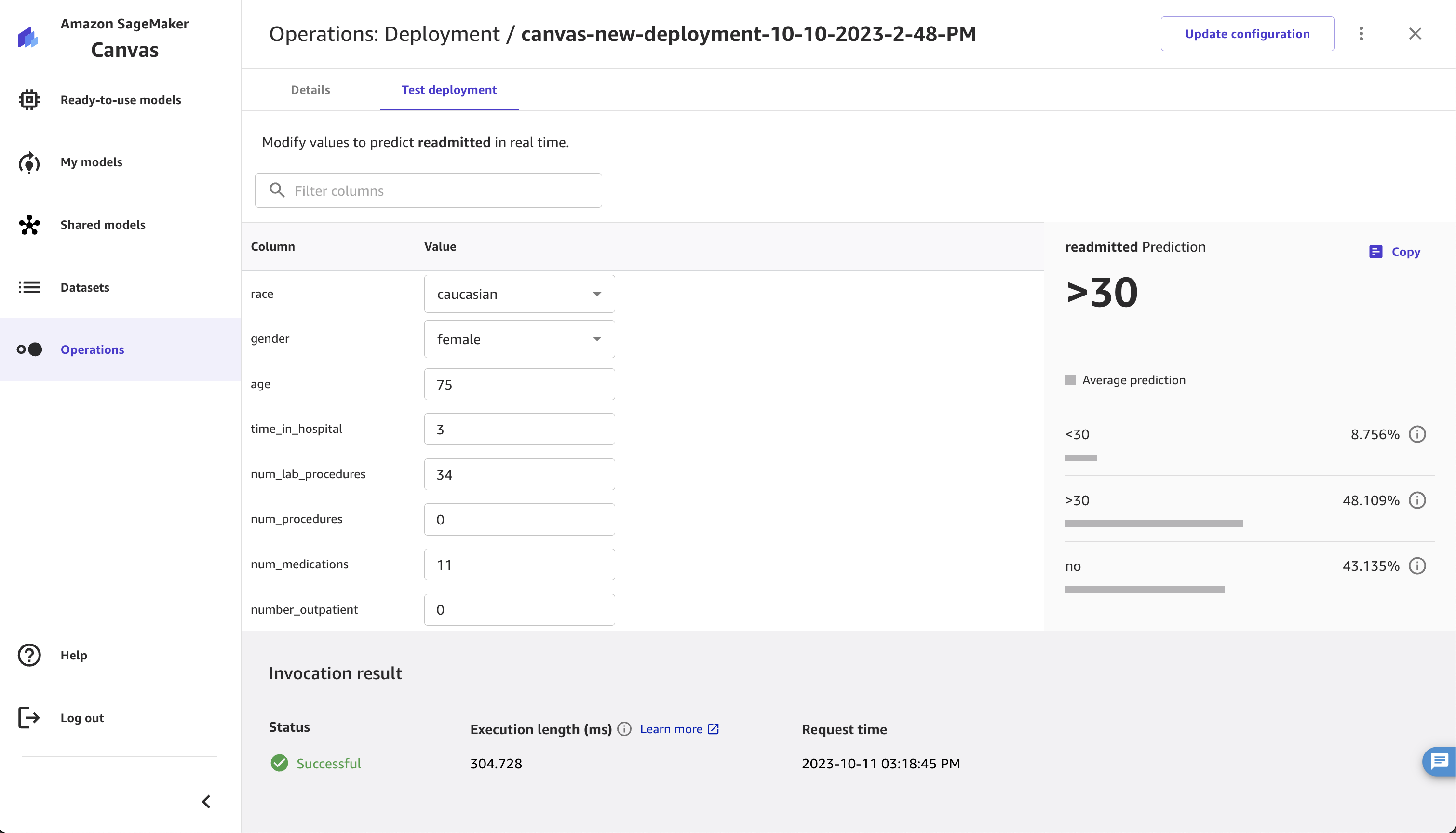
Per tutti i tipi di modello, tranne che per i tipi numerico e delle serie temporali, la previsione restituisce i seguenti campi:
-
etichetta_prevista: l'output previsto
-
probabilità: la probabilità che l'etichetta prevista sia corretta
-
etichette: l'elenco di tutte le etichette possibili
-
possibilità: le possibilità corrispondenti a ciascuna etichetta (l'ordine di questo elenco corrisponde all'ordine delle etichette)
Per i modelli di previsione numerica, la previsione contiene solo il campo punteggio, che è l'output previsto del modello, ad esempio il prezzo previsto di una casa.
Per i modelli di previsione delle serie temporali, la previsione è un grafo che mostra le previsioni per quantile. Puoi scegliere la visualizzazione Schema per vedere i valori numerici previsti per ogni quantile.
Puoi continuare a generare previsioni singole tramite la pagina di test della distribuzione oppure puoi consultare la sezione seguente Invocazione del tuo endpoint per scoprire come invocare l'endpoint in modo programmatico dalle applicazioni.
Prova l'implementazione di un modello di JumpStart base
Puoi chattare con un modello di JumpStart base distribuito tramite l'applicazione Canvas per testarne la funzionalità prima di richiamarlo tramite codice.
Per chattare con un modello di JumpStart base distribuito, procedi come segue:
-
Apri l'applicazione SageMaker Canvas.
-
Nel riquadro di navigazione a sinistra, scegli MLOps.
-
Seleziona la scheda Distribuzioni.
-
Nell’elenco delle implementazioni, individua quella che desideri invocare e scegli la relativa icona Altre opzioni (
 ).
). -
Dal menu contestuale, scegli Testa implementazione.
-
Si apre una nuova chat Genera, estrai e riassumi i contenuti con il modello JumpStart base e puoi iniziare a digitare le istruzioni. Tieni presente che i prompt di questa chat vengono inviati come richieste al tuo endpoint di AI Hosting. SageMaker
