Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Problema RunBooks
La sezione seguente contiene i problemi che possono verificarsi, come rilevarli e suggerimenti su come risolverli.
-
Notifica e-mail non ricevuta dopoCloudFormationpile create con successo
Errore rilevato per il parametro del blocco CIDR durante la creazione dell'ambiente
CloudFormation errore di creazione dello stack durante la creazione dell'ambiente
La creazione dello stack di risorse esterne (demo) non riesce con CREATE_FAILED AdDomainAdminNode
-
-
Problemi di installazione
Argomenti
Notifica e-mail non ricevuta dopoCloudFormationpile create con successo
Errore rilevato per il parametro del blocco CIDR durante la creazione dell'ambiente
CloudFormation errore di creazione dello stack durante la creazione dell'ambiente
La creazione dello stack di risorse esterne (demo) non riesce con CREATE_FAILED AdDomainAdminNode
........................
CloudFormationlo stack non riesce a creare il messaggio «messaggio non riuscito WaitCondition ricevuto». Error:States.TaskFailed»
Per identificare il problema, esamina il gruppo di CloudWatch log di Amazon denominato<stack-name>-InstallerTasksCreateTaskDefCreateContainerLogGroup<nonce>-<nonce>. Se ci sono più gruppi di log con lo stesso nome, esamina il primo disponibile. Un messaggio di errore all'interno dei log fornirà ulteriori informazioni sul problema.
Nota
Verificate che i valori dei parametri non abbiano spazi.
........................
Notifica e-mail non ricevuta dopoCloudFormationpile create con successo
Se non è stato ricevuto un invito via e-mail dopo che gli CloudFormation stack sono stati creati correttamente, verifica quanto segue:
-
Conferma che il parametro dell'indirizzo email è stato inserito correttamente.
Se l'indirizzo e-mail non è corretto o non è possibile accedervi, elimina e ridistribuisci l'ambiente Research and Engineering Studio.
-
Controlla la console Amazon EC2 per le prove delle istanze cicliche.
Se ci sono istanze Amazon EC2 con il
<envname>prefisso che appaiono come terminate e poi vengono sostituite con una nuova istanza, potrebbe esserci un problema con la configurazione di rete o di Active Directory. -
Se hai distribuito le ricette AWS High Performance Compute per creare le tue risorse esterne, verifica che il VPC, le sottoreti private e pubbliche e altri parametri selezionati siano stati creati dallo stack.
Se uno qualsiasi dei parametri non è corretto, potrebbe essere necessario eliminare e ridistribuire l'ambiente RES. Per ulteriori informazioni, consulta Disinstalla il prodotto.
-
Se hai distribuito il prodotto con risorse esterne, verifica che la rete e Active Directory corrispondano alla configurazione prevista.
È fondamentale confermare che le istanze dell'infrastruttura siano entrate a far parte di Active Directory con successo. Prova i passaggi seguenti Istanze in ciclo o vdc-controller in stato di errore per risolvere il problema.
........................
Istanze in ciclo o vdc-controller in stato di errore
La causa più probabile di questo problema è l'impossibilità delle risorse di connettersi o unirsi ad Active Directory.
Per verificare il problema:
-
Dalla riga di comando, avvia una sessione con SSM sull'istanza in esecuzione del vdc-controller.
-
Esegui
sudo su -. -
Esegui
systemctl status sssd.
Se lo stato è inattivo, non riuscito o vengono visualizzati errori nei log, l'istanza non è riuscita a entrare in Active Directory.
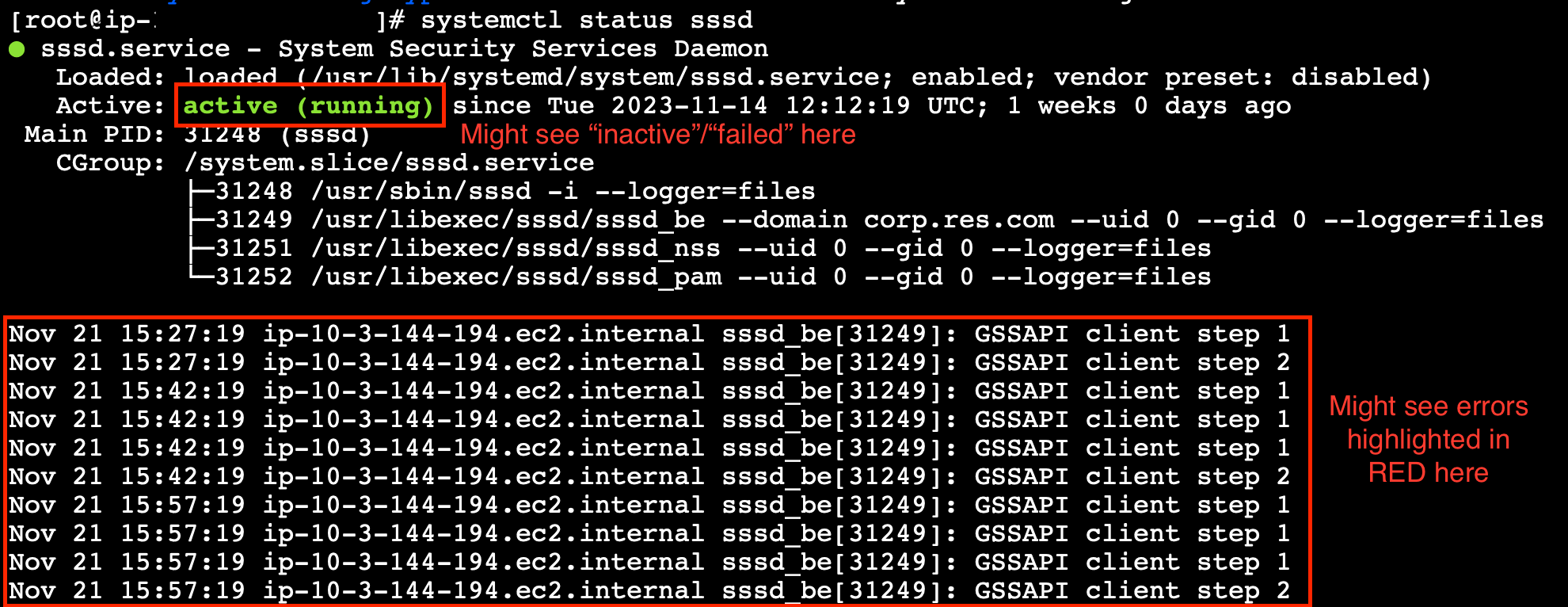
Registro degli errori SSM
Per risolvere il problema:
-
Dalla stessa istanza della riga di comando,
cat /root/bootstrap/logs/userdata.logesegui per esaminare i log.
Il problema potrebbe avere una delle tre possibili cause principali.
Esamina i log. Se vedi quanto segue ripetuto più volte, significa che l'istanza non è riuscita a entrare in Active Directory.
+ local AD_AUTHORIZATION_ENTRY= + [[ -z '' ]] + [[ 0 -le 180 ]] + local SLEEP_TIME=34 + log_info '(0 of 180) waiting for AD authorization, retrying in 34 seconds ...' ++ date '+%Y-%m-%d %H:%M:%S,%3N' + echo '[2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ...' [2024-01-16 22:02:19,802] [INFO] (0 of 180) waiting for AD authorization, retrying in 34 seconds ... + sleep 34 + (( ATTEMPT_COUNT++ ))
-
Verifica che i valori dei parametri per quanto segue siano stati inseriti correttamente durante la creazione dello stack RES.
-
directoryservice.ldap_connection_uri
-
directoryservice.ldap_base
-
directoryservice.users.ou
-
directoryservice.groups.ou
-
directoryservice.sudoers.ou
-
directoryservice.computers.ou
-
directoryservice.name
-
-
Aggiorna eventuali valori errati nella tabella DynamoDB. La tabella si trova nella console DynamoDB in Tabelle. Il nome della tabella dovrebbe essere.
<stack name>.cluster-settings -
Dopo aver aggiornato la tabella, eliminate il cluster-manager e il vdc-controller che attualmente eseguono le istanze di ambiente. La scalabilità automatica avvierà nuove istanze utilizzando i valori più recenti della tabella DynamoDB.
Se i log vengono restituitiInsufficient permissions to modify computer account, il ServiceAccount nome inserito durante la creazione dello stack potrebbe essere errato.
-
Dalla AWS console, apri Secrets Manager.
-
Cercare
directoryserviceServiceAccountUsername. Il segreto dovrebbe essere<stack name>-directoryservice-ServiceAccountUsername -
Apri il segreto per visualizzare la pagina dei dettagli. In Valore segreto, scegli Recupera valore segreto e scegli Testo normale.
-
Se il valore è stato aggiornato, elimina le istanze cluster-manager e vdc-controller attualmente in esecuzione dell'ambiente. La scalabilità automatica avvierà nuove istanze utilizzando il valore più recente di Secrets Manager.
Se vengono visualizzati i logInvalid credentials, la ServiceAccount password inserita durante la creazione dello stack potrebbe essere errata.
-
Dalla AWS console, apri Secrets Manager.
-
Cercare
directoryserviceServiceAccountPassword. Il segreto dovrebbe essere<stack name>-directoryservice-ServiceAccountPassword -
Apri il segreto per visualizzare la pagina dei dettagli. In Valore segreto, scegli Recupera valore segreto e scegli Testo normale.
-
Se hai dimenticato la password o non sei sicuro che la password inserita sia corretta, puoi reimpostarla in Active Directory and Secrets Manager.
-
Per reimpostare la password in: AWS Managed Microsoft AD
-
Apri la AWS console e vai aDirectory Service.
-
Seleziona l'ID della directory RES e scegli Azioni.
-
Seleziona Reimposta la password dell'utente.
-
Inserisci il ServiceAccount nome utente.
-
Inserisci una nuova password e scegli Reimposta password.
-
-
Per reimpostare la password in Secrets Manager:
-
Apri la AWS console e vai a Secrets Manager.
-
Cercare
directoryserviceServiceAccountPassword. Il segreto dovrebbe essere<stack name>-directoryservice-ServiceAccountPassword -
Apri il segreto per visualizzare la pagina dei dettagli. In Valore segreto, scegli Recupera valore segreto, quindi scegli Testo normale.
-
Scegli Modifica.
-
Imposta una nuova password per l' ServiceAccount utente e scegli Salva.
-
-
-
Se hai aggiornato il valore, elimina le istanze cluster-manager e vdc-controller attualmente in esecuzione dell'ambiente. La scalabilità automatica avvierà nuove istanze utilizzando il valore più recente.
........................
Impossibile eliminare CloudFormation lo stack di ambiente a causa di un errore dell'oggetto dipendente
Se l'eliminazione dello <env-name>-vdcvdcdcvhostsecuritygroup, ciò potrebbe essere dovuto a un'istanza Amazon EC2 che è stata lanciata in RES-created una sottorete o in un gruppo di sicurezza utilizzando la Console. AWS
Per risolvere il problema, trova e termina tutte le istanze Amazon EC2 avviate in questo modo. È quindi possibile riprendere l'eliminazione dell'ambiente.
........................
Errore rilevato per il parametro del blocco CIDR durante la creazione dell'ambiente
Durante la creazione di un ambiente, viene visualizzato un errore per il parametro di blocco CIDR con uno stato di risposta di [FAILED].
Esempio di errore:
Failed to update cluster prefix list: An error occurred (InvalidParameterValue) when calling the ModifyManagedPrefixList operation: The specified CIDR (52.94.133.132/24) is not valid. For example, specify a CIDR in the following form: 10.0.0.0/16.
Per risolvere il problema, il formato previsto è x.x.x. 0/24 o x.x.x. 0/32
........................
CloudFormation errore di creazione dello stack durante la creazione dell'ambiente
La creazione di un ambiente implica una serie di operazioni di creazione di risorse. In alcune regioni, può verificarsi un problema di capacità che impedisce la creazione di uno CloudFormation stack.
In tal caso, elimina l'ambiente e riprova a creare. In alternativa, puoi riprovare la creazione in un'altra regione.
........................
La creazione dello stack di risorse esterne (demo) non riesce con CREATE_FAILED AdDomainAdminNode
Se la creazione dello stack dell'ambiente demo fallisce con il seguente errore, potrebbe essere dovuto all'applicazione di patch di Amazon EC2 avvenuta in modo imprevisto durante il provisioning dopo il lancio dell'istanza.
AdDomainAdminNode CREATE_FAILED Failed to receive 1 resource signal(s) within the specified duration
Per determinare la causa dell'errore:
-
In SSM State Manager, controlla se l'applicazione delle patch è configurata e se è configurata per tutte le istanze.
-
Nella cronologia di esecuzione di SSM, controlla se RunCommand/Automation l'esecuzione di un documento SSM relativo all'applicazione di patch coincide con l'avvio di un'istanza.
-
Nei file di registro per le istanze Amazon EC2 dell'ambiente, esamina la registrazione dell'istanza locale per determinare se l'istanza è stata riavviata durante il provisioning.
Se il problema è stato causato dall'applicazione di patch, ritarda l'applicazione delle patch per le istanze RES di almeno 15 minuti dopo l'avvio.
........................
Problemi di gestione delle identità
La maggior parte dei problemi con il Single Sign-On (SSO) e la gestione delle identità si verificano a causa di una configurazione errata. Per informazioni sulla configurazione SSO, consulta:
Per risolvere altri problemi relativi alla gestione delle identità, consulta i seguenti argomenti di risoluzione dei problemi:
Argomenti
........................
Non sono autorizzato a eseguire iam: PassRole
Se ricevi un messaggio di errore indicante che non sei autorizzato a eseguire l'PassRole azione iam:, le tue politiche devono essere aggiornate per consentirti di trasferire un ruolo a RES.
Alcuni AWS servizi consentono di trasferire un ruolo esistente a quel servizio anziché creare un nuovo ruolo di servizio o un ruolo collegato al servizio. Per eseguire questa operazione, è necessario disporre delle autorizzazioni per trasmettere il ruolo al servizio.
L'errore di esempio seguente si verifica quando un utente IAM di nome marymajor tenta di utilizzare la console per eseguire un'azione in RES. Tuttavia, l’azione richiede che il servizio disponga delle autorizzazioni concesse da un ruolo di servizio. Mary non dispone delle autorizzazioni per trasmettere il ruolo al servizio.
User: arn:aws:iam::123456789012:user/marymajor is not authorized to perform: iam:PassRole
In questo caso, le politiche di Mary devono essere aggiornate per consentirle di eseguire l'azione iam:PassRole . Se hai bisogno di aiuto, contatta il tuo AWS amministratore. L’amministratore è la persona che ti ha fornito le credenziali di accesso.
........................
Voglio consentire l'accesso a persone esterne al mioAWSaccount per accedere al mio studio di ricerca e ingegneria suAWSrisorse
È possibile creare un ruolo con il quale utenti in altri account o persone esterne all’organizzazione possono accedere alle tue risorse. È possibile specificare chi è attendibile per l’assunzione del ruolo. Per servizi che supportano policy basate su risorse o liste di controllo degli accessi (ACL), utilizzare tali policy per concedere alle persone l’accesso alle proprie risorse.
Per maggiori informazioni, consulta gli argomenti seguenti:
-
Per scoprire come fornire l'accesso alle tue risorse su più AWS account di tua proprietà, consulta Fornire l'accesso a un utente IAM in un altro AWS account di tua proprietà nella IAM User Guide.
-
Per scoprire come fornire l'accesso alle tue risorse ad AWS account di terze parti, consulta Fornire l'accesso agli AWS account di proprietà di terze parti nella IAM User Guide.
-
Per scoprire come fornire l'accesso tramite la federazione delle identità, consulta Fornire l'accesso agli utenti autenticati esternamente (federazione delle identità) nella Guida per l'utente IAM.
-
Per scoprire la differenza tra l'utilizzo dei ruoli e delle politiche basate sulle risorse per l'accesso tra account diversi, consulta In che modo i ruoli IAM differiscono dalle politiche basate sulle risorse nella Guida per l'utente IAM.
........................
Quando accedo all'ambiente, torno immediatamente alla pagina di accesso
Questo problema si verifica quando l'integrazione SSO non è configurata correttamente. Per determinare il problema, controlla i registri delle istanze del controller e verifica la presenza di errori nelle impostazioni di configurazione.
Per controllare i log:
-
Apri la CloudWatch console
. -
Da Gruppi di log, trova il gruppo denominato
/.<environment-name>/cluster-manager -
Apri il gruppo di log per cercare eventuali errori nei flussi di log.
Per verificare le impostazioni di configurazione:
-
Apri la console DynamoDB
-
In Tabelle, trova la tabella denominata.
<environment-name>.cluster-settings -
Apri la tabella e scegli Esplora gli elementi della tabella.
-
Espandi la sezione dei filtri e inserisci le seguenti variabili:
-
Nome dell'attributo: chiave
-
Condizione: contiene
-
Valore: sso
-
-
Scegli Esegui.
-
Nella stringa restituita, verifica che i valori di configurazione SSO siano corretti. Se non sono corretti, modifica il valore della chiave sso_enabled su False.
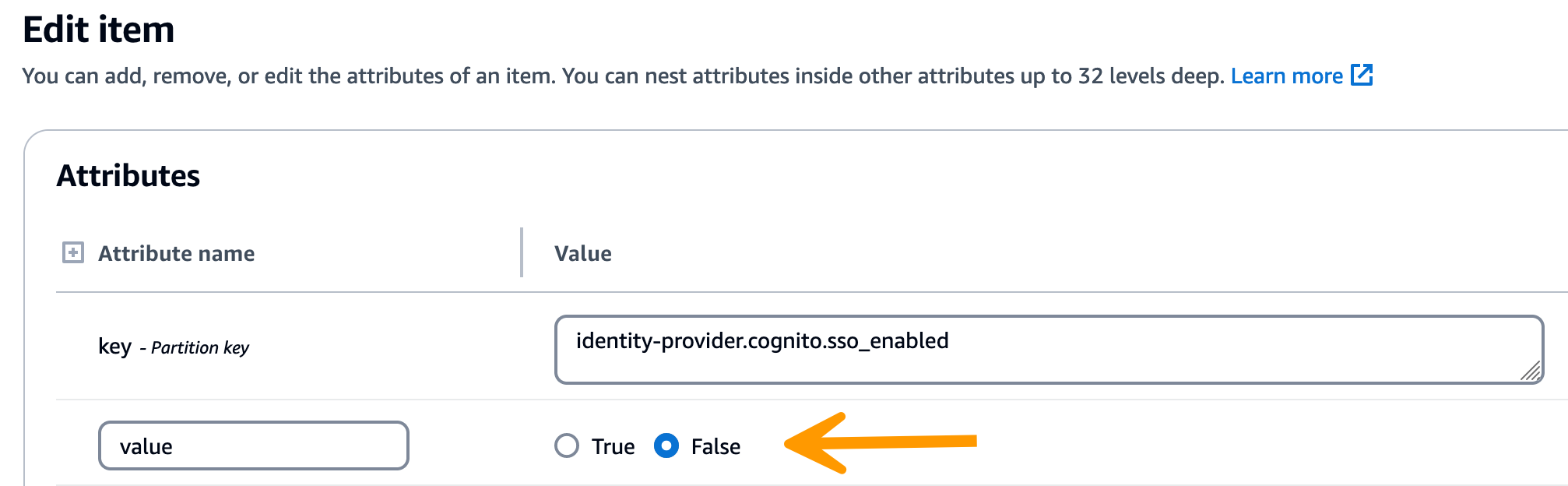
-
Tornate all'interfaccia utente RES per riconfigurare l'SSO.
........................
Errore «Utente non trovato» durante il tentativo di accesso
Se un utente riceve l'errore «Utente non trovato» quando tenta di accedere all'interfaccia RES e l'utente è presente in Active Directory:
-
Se l'utente non è presente in RES e l'hai recentemente aggiunto ad AD
-
È possibile che l'utente non sia ancora sincronizzato con RES. RES si sincronizza ogni ora, quindi potrebbe essere necessario attendere e verificare che l'utente sia stato aggiunto dopo la sincronizzazione successiva. Per eseguire la sincronizzazione immediata, segui la procedura riportata di seguito. Utente aggiunto in Active Directory, ma mancante in RES
-
-
Se l'utente è presente in RES:
-
Assicurati che la mappatura degli attributi sia configurata correttamente. Per ulteriori informazioni, consulta Configurazione del provider di identità per il Single Sign-On (SSO).
-
Assicurati che l'oggetto SAML e l'e-mail SAML corrispondano entrambi all'indirizzo e-mail dell'utente.
-
........................
Utente aggiunto in Active Directory, ma mancante in RES
Nota
Questa sezione si applica a RES 2024.10 e versioni precedenti. Per RES 2024.12 e versioni successive, vedere. Come eseguire manualmente la sincronizzazione (release 2024.12 e 2024.12.01) Per RES 2025.03 e versioni successive, vedere. Come avviare o interrompere manualmente la sincronizzazione (versione 2025.03 e successive)
Se hai aggiunto un utente ad Active Directory ma non è presente in RES, è necessario attivare la sincronizzazione AD. La sincronizzazione AD viene eseguita ogni ora da una funzione Lambda che importa le voci AD nell'ambiente RES. A volte, dopo l'aggiunta di nuovi utenti o gruppi, si verifica un ritardo fino all'esecuzione del processo di sincronizzazione successivo. Puoi avviare la sincronizzazione manualmente da Amazon Simple Queue Service.
Avvia il processo di sincronizzazione manualmente:
-
Apri la console Amazon SQS
. -
Da Queues, seleziona.
<environment-name>-cluster-manager-tasks.fifo -
Scegli Invia e ricevi messaggi.
-
Per il corpo del messaggio, inserisci:
{ "name": "adsync.sync-from-ad", "payload": {} } -
Per ID del gruppo di messaggi, inserisci:
adsync.sync-from-ad -
Per ID di deduplicazione dei messaggi, inserisci una stringa alfanumerica casuale. Questa immissione deve essere diversa da tutte le chiamate effettuate negli ultimi cinque minuti o la richiesta verrà ignorata.
........................
Utente non disponibile durante la creazione di una sessione
Se sei un amministratore che crea una sessione, ma scopri che un utente che si trova in Active Directory non è disponibile durante la creazione di una sessione, potrebbe essere necessario accedere per la prima volta. Le sessioni possono essere create solo per utenti attivi. Gli utenti attivi devono accedere all'ambiente almeno una volta.
........................
Il limite di dimensione è stato superato (errore nel registro del gestore del CloudWatch cluster)
2023-10-31T18:03:12.942-07:00 ldap.SIZELIMIT_EXCEEDED: {'msgtype': 100, 'msgid': 11, 'result': 4, 'desc': 'Size limit exceeded', 'ctrls': []}
Se si riceve questo errore nel registro del CloudWatch gestore del cluster, la ricerca ldap potrebbe aver restituito troppi record utente. Per risolvere questo problema, aumenta il limite dei risultati di ricerca ldap del tuo IDP.
........................
Archiviazione
Argomenti
........................
Ho creato il file system tramite RES ma non si monta sugli host VDI
I file system devono essere nello stato «Disponibile» prima di poter essere montati dagli host VDI. Segui i passaggi seguenti per verificare che il file system sia nello stato richiesto.
Amazon EFS
-
Vai alla console Amazon EFS
. -
Verifica che lo stato del file system sia Disponibile.
-
Se lo stato del file system non è Disponibile, attendi prima di avviare gli host VDI.
Amazon FSx ONTAP
-
Vai alla console Amazon FSx
. -
Verifica che lo stato sia disponibile.
-
Se Status non è disponibile, attendi prima di avviare gli host VDI.
........................
Ho effettuato l'onboarding di un file system tramite RES ma non viene montato sugli host VDI
I file system integrati su RES devono avere le regole di gruppo di sicurezza richieste configurate per consentire agli host VDI di montare i file system. Poiché questi file system vengono creati esternamente a RES, RES non gestisce le regole dei gruppi di sicurezza associati.
Il gruppo di sicurezza associato ai file system integrati dovrebbe consentire il seguente traffico in entrata:
Traffico NFS (porta: 2049) dagli host Linux VDC
Traffico SMB (porta: 445) proveniente dagli host Windows VDC
........................
Non riesco ad accedervi dagli read/write host VDI
ONTAP supporta lo stile di sicurezza UNIX, NTFS e MIXED per i volumi. Gli stili di sicurezza determinano il tipo di autorizzazioni utilizzate da ONTAP per controllare l'accesso ai dati e il tipo di client che può modificare tali autorizzazioni.
Ad esempio, se un volume utilizza lo stile di sicurezza UNIX, i client SMB possono comunque accedere ai dati (a condizione che si autentichino e autorizzino correttamente) grazie alla natura multiprotocollo di ONTAP. Tuttavia, ONTAP utilizza autorizzazioni UNIX che solo i client UNIX possono modificare utilizzando strumenti nativi.
Esempi di casi d'uso per la gestione delle autorizzazioni
Utilizzo di volumi in stile UNIX con carichi di lavoro Linux
Le autorizzazioni possono essere configurate dal sudoer per altri utenti. Ad esempio, quanto segue fornirebbe a tutti i membri le read/write autorizzazioni <group-ID> complete sulla directory: /<project-name>
sudo chown root:<group-ID>/<project-name>sudo chmod 770 /<project-name>
Utilizzo di volumi in stile NTFS con carichi di lavoro Linux e Windows
Le autorizzazioni di condivisione possono essere configurate utilizzando le proprietà di condivisione di una cartella particolare. Ad esempio, in base a un utente user_01 e a una cartellamyfolder, è possibile impostare le autorizzazioni di Full ControlChange, o Read su Allow o: Deny

Se il volume verrà utilizzato da client Linux e Windows, è necessario impostare una mappatura dei nomi su SVM che assocerà qualsiasi nome utente Linux allo stesso nome utente con il formato del nome di dominio NetBIOS domain\ username. Questo è necessario per tradurre tra utenti Linux e Windows. Per riferimento, consulta Abilitazione dei carichi di lavoro multiprotocollo con Amazon FSx
........................
Ho creato Amazon FSx per NetApp ONTAP da RES ma non è entrato a far parte del mio dominio
Attualmente, quando crei Amazon FSx for NetApp ONTAP dalla console RES, il file system viene fornito ma non entra a far parte del dominio. Per aggiungere la SVM del file system ONTAP creata al tuo dominio, consulta Unire le SVM a Microsoft Active Directory e segui i passaggi sulla console Amazon FSx
Dopo averlo aggiunto al dominio, modifica la chiave di configurazione DNS SMB nella tabella DynamoDB delle impostazioni del cluster:
-
Vai alla console Amazon DynamoDB
. -
Scegli Tabelle, quindi scegli.
<stack-name>-cluster-settings -
In Esplora gli elementi della tabella, espandi Filtri e inserisci il seguente filtro:
Nome dell'attributo: chiave
Condizione: uguale a
-
Valore -
shared-storage.<file-system-name>.fsx_netapp_ontap.svm.smb_dns
-
Seleziona l'articolo restituito, quindi Azioni, Modifica articolo.
-
Aggiorna il valore con il nome DNS SMB che hai copiato in precedenza.
-
Selezionare Save and close (Salva e chiudi).
Inoltre, assicurati che il gruppo di sicurezza associato al file system consenta il traffico come consigliato in File System Access Control with Amazon VPC. I nuovi host VDI che utilizzano il file system saranno ora in grado di montare SVM e file system uniti al dominio.
In alternativa, è possibile effettuare l'onboarding di un file system esistente che fa già parte del dominio utilizzando la funzionalità RES Onboard File System: da Environment Management scegli File Systems, Onboard File System.
........................
Snapshot
Argomenti
........................
Lo stato di un'istantanea è Fallito
Nella pagina RES Snapshots, se uno snapshot ha lo stato Failed, la causa può essere determinata accedendo al gruppo di CloudWatch log di Amazon per il gestore del cluster per il momento in cui si è verificato l'errore.
[2023-11-19 03:39:20,208] [INFO] [snapshots-service] creating snapshot in S3 Bucket: asdf at path s31 [2023-11-19 03:39:20,381] [ERROR] [snapshots-service] An error occurred while creating the snapshot: An error occurred (TableNotFoundException) when calling the UpdateContinuousBackups operation: Table not found: res-demo.accounts.sequence-config
........................
Uno snapshot non viene applicato con i log che indicano che le tabelle non possono essere importate.
Se un'istantanea scattata da un ambiente precedente non viene applicata in un nuovo ambiente, esamina i CloudWatch log di Cluster-Manager per identificare il problema. Se il problema indica che le tabelle richieste dal cloud non possono essere importate, verifica che lo snapshot sia in uno stato valido.
-
Scaricate il file metadata.json e verificate che lo stato delle varie tabelle sia ExportStatus COMPLETATO. Assicurati che il campo sia impostato nelle varie tabelle.
ExportManifestSe non trovi i campi precedenti impostati, l'istantanea è in uno stato non valido e non può essere utilizzata con la funzionalità di applicazione dell'istantanea. -
Dopo aver avviato la creazione di un'istantanea, assicurati che lo stato dell'istantanea diventi su COMPLETATO in RES. Il processo di creazione dell'istantanea richiede da 5 a 10 minuti. Ricarica o rivisita la pagina di gestione delle istantanee per assicurarti che l'istantanea sia stata creata correttamente. Ciò garantirà che l'istantanea creata sia in uno stato valido.
........................
Infrastruttura
........................
Gruppi target di Load Balancer senza istanze integre
Se nell'interfaccia utente vengono visualizzati problemi come messaggi di errore del server o se le sessioni desktop non riescono a connettersi, ciò potrebbe indicare un problema nell'infrastruttura delle istanze Amazon EC2.
I metodi per determinare l'origine del problema consistono innanzitutto nel controllare nella console Amazon EC2 eventuali istanze Amazon EC2 che sembrano terminare ripetutamente e essere sostituite da nuove istanze. In tal caso, il controllo dei CloudWatch log di Amazon può determinarne la causa.
Un altro metodo è controllare i sistemi di bilanciamento del carico nel sistema. Un'indicazione che potrebbero esserci problemi di sistema è se alcuni sistemi di bilanciamento del carico, presenti sulla console Amazon EC2, non mostrano alcuna istanza integra registrata.
Di seguito è riportato un esempio di aspetto normale:

Se la voce Healthy è 0, ciò indica che nessuna istanza Amazon EC2 è disponibile per elaborare le richieste.
Se la voce Unhealthy è diversa da 0, ciò indica che un'istanza Amazon EC2 potrebbe essere in ciclo. Ciò può essere dovuto al fatto che il software delle applicazioni installate non supera i controlli di integrità.
Se entrambe le voci Healthy e Unhealthy sono 0, ciò indica una potenziale configurazione errata della rete. Ad esempio, le sottoreti pubbliche e private potrebbero non avere AZ corrispondenti. Se si verifica questa condizione, è possibile che sulla console sia presente un testo aggiuntivo che indica l'esistenza dello stato della rete.
........................
Avvio di desktop virtuali
Argomenti
........................
L'account di accesso per Windows Virtual Desktop è impostato su Amministratore
Se è possibile avviare un desktop virtuale Windows nel portale Web RES ma il relativo account di accesso è impostato su Amministratore al momento della connessione, è possibile che il VDI di Windows non si sia unito correttamente ad Active Directory.
Per verificare, connettiti all'istanza Windows dalla console Amazon EC2 e controlla i log di bootstrap sotto. C:\Users\Administrator\RES\Bootstrap\virtual-desktop-host-windows\ Un messaggio di errore che inizia con [Join AD] authorization failed: indica che l'istanza non è riuscita a unirsi all'AD. Controlla che Cluster Manager acceda CloudWatch con il nome del gruppo di log / per maggiori dettagli sull'errore:<res-environment-name>/cluster-manager
-
Insufficient permissions to modify computer account-
Questo errore indica che il tuo account di servizio non dispone delle autorizzazioni appropriate per aggiungere computer all'AD. Controlla la Configurare un account di servizio per Microsoft Active Directory sezione per le autorizzazioni richieste dall'account di servizio.
-
-
Invalid Credentials-
Le credenziali del tuo account di servizio in AD sono scadute o hai fornito credenziali errate. Per controllare o aggiornare le credenziali del tuo account di servizio, accedi al segreto che memorizza la password nella console Secrets Manager
. Assicurati che l'ARN di questo segreto sia corretto nel campo Service Account Credentials Secret ARN in Active Directory Domain nella pagina Identity Management del tuo ambiente RES.
-
........................
Il certificato scade quando si utilizza una risorsa esterna CertificateRenewalNode
Se hai distribuito la ricetta External Resources e riscontri un errore "The connection has been closed. Transport error" durante la connessione a Linux VDI, la causa più probabile è un certificato scaduto che non viene aggiornato automaticamente a causa di un percorso di installazione pip errato su Linux. I certificati scadono dopo 3 mesi.
Il gruppo di CloudWatch log di Amazon <envname>/vdc/dcv-connection-gateway
| 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Error in connection task: TLS handshake error: received fatal alert: CertificateUnknown | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 | | 2024-07-29T21:46:02.651Z | Jul 29 21:46:01.702 WARN HTTP:Splicer Connection{id=341 client_address="x.x.x.x:50682"}: Certificate error: AlertReceived(CertificateUnknown) | redacted:/res-demo/vdc/dcv-connection-gateway | dcv-connection-gateway_10.3.146.195 |
Per risolvere il problema:
-
Nel tuo AWS account, accedi a EC2
. Se è presente un'istanza denominata *-CertificateRenewalNode-*, interrompi l'istanza. -
Vai a Lambda
. Dovresti vedere una funzione Lambda denominata *-CertificateRenewalLambda-*, controlla il codice Lambda per qualcosa di simile alla seguente:export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py python3 ./get-pip.py pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates git clone https://github.com/Neilpang/acme.sh.git cd acme.sh -
Trova il modello di stack Certs per risorse esterne più recente qui.
Trova il codice Lambda nel modello: Risorse → → Proprietà CertificateRenewalLambda→ Codice. Potresti trovare qualcosa di simile al seguente: sudo yum install -y wget export HOME=/tmp/home mkdir -p $HOME cd /tmp wget https://bootstrap.pypa.io/pip/3.7/get-pip.py mkdir -p pip python3 ./get-pip.py --target $PWD/pip $PWD/pip/bin/pip3 install boto3 eval $(python3 -c "from botocore.credentials import InstanceMetadataProvider, InstanceMetadataFetcher; provider = InstanceMetadataProvider(iam_role_fetcher=InstanceMetadataFetcher(timeout=1000, num_attempts=2)); c = provider.load().get_frozen_credentials(); print(f'export AWS_ACCESS_KEY_ID={c.access_key}'); print(f'export AWS_SECRET_ACCESS_KEY={c.secret_key}'); print(f'export AWS_SESSION_TOKEN={c.token}')") mkdir certificates cd certificates VERSION=3.1.0 wget https://github.com/acmesh-official/acme.sh/archive/refs/tags/$VERSION.tar.gz -O acme-$VERSION.tar.gz tar -xvf acme-$VERSION.tar.gz cd acme.sh-$VERSION -
Sostituisci la sezione del passaggio 2 della funzione
*-CertificateRenewalLambda-*Lambda con il codice del passaggio 3. Seleziona Deploy e attendi che la modifica al codice abbia effetto. -
Per attivare manualmente la funzione Lambda, vai alla scheda Test e seleziona Test. Non è richiesto alcun input aggiuntivo. Questo dovrebbe creare un'istanza EC2 del certificato che aggiorni il certificato e PrivateKey i segreti in Secret Manager.
-
Termina l'istanza dcv-gateway esistente
<env-name>-vdc-gateway
........................
Un desktop virtuale che funzionava in precedenza non è più in grado di connettersi correttamente
Se una connessione desktop si chiude o non è più possibile connetterti ad essa, il problema potrebbe essere dovuto al guasto dell'istanza Amazon EC2 sottostante o l'istanza Amazon EC2 potrebbe essere stata terminata o interrotta al di fuori dell'ambiente RES. Lo stato dell'interfaccia utente di amministrazione può continuare a mostrare uno stato pronto, ma i tentativi di connessione non riescono.
La console Amazon EC2 deve essere utilizzata per determinare se l'istanza è stata interrotta o interrotta. Se è interrotta, prova a riavviarla. Se lo stato viene terminato, sarà necessario creare un altro desktop. Tutti i dati archiviati nella home directory dell'utente dovrebbero essere ancora disponibili all'avvio della nuova istanza.
Se l'istanza che aveva avuto esito negativo in precedenza è ancora presente nell'interfaccia utente di amministrazione, potrebbe essere necessario chiuderla utilizzando l'interfaccia utente di amministrazione.
........................
Sono in grado di avviare solo 5 desktop virtuali
Il limite predefinito per il numero di desktop virtuali che un utente può avviare è 5. Questo può essere modificato da un amministratore utilizzando l'interfaccia utente di amministrazione come segue:
Vai a Impostazioni del desktop.
Seleziona la scheda Generale.
Seleziona l'icona di modifica a destra del campo Sessioni consentite predefinite per utente per progetto e modifica il valore con il nuovo valore desiderato.
Seleziona Invia.
Aggiorna la pagina per confermare che la nuova impostazione è attiva.
........................
I tentativi di connessione su Desktop Windows falliscono e viene visualizzato il messaggio «La connessione è stata chiusa. Errore di trasporto»
Se una connessione desktop Windows fallisce e viene visualizzato l'errore dell'interfaccia utente «La connessione è stata chiusa. «Errore di trasporto», la causa può essere dovuta a un problema nel software del server DCV relativo alla creazione di certificati sull'istanza di Windows.
Il gruppo di CloudWatch log di Amazon <envname>/vdc/dcv-connection-gateway può registrare l'errore del tentativo di connessione con messaggi simili ai seguenti:
Nov 24 20:24:27.631 DEBUG HTTP:Splicer Connection{id=9}: Websocket{session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd"}: Resolver lookup{client_ip=Some(52.94.36.19) session_id="1291e75f-7816-48d9-bbb2-7371b3b911cd" protocol_type=WebSocket extension_data=None}:NoStrictCertVerification: Additional stack certificate (0): [s/n: 0E9E9C4DE7194B37687DC4D2C0F5E94AF0DD57E] Nov 24 20:25:15.384 INFO HTTP:Splicer Connection{id=21}:Websocket{ session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Connection initiated error: unreachable, server io error Custom { kind: InvalidData, error: General("Invalid certificate: certificate has expired (code: 10)") } Nov 24 20:25:15.384 WARN HTTP:Splicer Connection{id=21}: Websocket{session_id="d1d35954-f29d-4b3f-8c23-6a53303ebc3f"}: Error in websocket connection: Server unreachable: Server error: IO error: unexpected error: Invalid certificate: certificate has expired (code: 10)
In tal caso, una soluzione potrebbe essere quella di utilizzare SSM Session Manager per aprire una connessione all'istanza di Windows e rimuovere i seguenti 2 file relativi al certificato:
PS C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv> dir Directory: C:\Windows\system32\config\systemprofile\AppData\Local\NICE\dcv Mode LastWriteTime Length Name ---- ------------- ------ ---- -a---- 8/4/2022 12:59 PM 1704 dcv.key -a---- 8/4/2022 12:59 PM 1265 dcv.pem
I file devono essere ricreati automaticamente e un successivo tentativo di connessione potrebbe avere successo.
Se questo metodo risolve il problema e se i nuovi avvii dei desktop Windows generano lo stesso errore, utilizzate la funzione Create Software Stack per creare un nuovo stack software Windows dell'istanza fissa con i file di certificato rigenerati. Ciò può produrre uno stack di software Windows che può essere utilizzato per avvii e connessioni di successo.
........................
I VDI sono bloccati nello stato di provisioning
Se il lancio di un desktop rimane nello stato di provisioning nell'interfaccia utente di amministrazione, ciò può essere dovuto a diversi motivi.
Per determinare la causa, esamina i file di registro sull'istanza desktop e cerca gli errori che potrebbero causare il problema. Questo documento contiene un elenco di file di log e gruppi di CloudWatch log Amazon che contengono informazioni pertinenti nella sezione denominata Fonti utili di informazioni su log ed eventi.
Di seguito sono elencate le possibili cause di questo problema.
-
L'ID AMI utilizzato è stato registrato come stack software ma non è supportato da RES.
Lo script di provisioning bootstrap non è stato completato perché Amazon Machine Image (AMI) non dispone della configurazione o degli strumenti previsti richiesti. I file di registro sull'istanza, ad esempio
/root/bootstrap/logs/su un'istanza Linux, possono contenere informazioni utili in merito. Gli ID AMI presi dal AWS Marketplace potrebbero non funzionare per le istanze desktop RES. Richiedono dei test per confermare se sono supportati. -
Gli script dei dati utente non vengono eseguiti quando l'istanza del desktop virtuale di Windows viene avviata da un'AMI personalizzata.
Per impostazione predefinita, gli script dei dati utente vengono eseguiti una sola volta all'avvio di un'istanza Amazon EC2. Se crei un'AMI da un'istanza di desktop virtuale esistente, quindi registri uno stack software con l'AMI e provi ad avviare un altro desktop virtuale con questo stack software, gli script dei dati utente non verranno eseguiti sulla nuova istanza di desktop virtuale.
Per risolvere il problema, apri una finestra di PowerShell comando come amministratore sull'istanza del desktop virtuale originale che hai usato per creare l'AMI ed esegui il seguente comando:
C:\ProgramData\Amazon\EC2-Windows\Launch\Scripts\InitializeInstance.ps1 –ScheduleQuindi crea una nuova AMI dall'istanza. È possibile utilizzare la nuova AMI per registrare stack software e avviare successivamente nuovi desktop virtuali. Tieni presente che puoi anche eseguire lo stesso comando sull'istanza che rimane nello stato di provisioning e riavviare l'istanza per correggere la sessione del desktop virtuale, ma riscontrerai nuovamente lo stesso problema all'avvio di un altro desktop virtuale dall'AMI non configurata correttamente.
........................
I VDI entrano nello stato di errore dopo l'avvio
- Possibile problema 1: il filesystem home ha una directory per l'utente con permessi POSIX diversi.
-
Questo potrebbe essere il problema che stai affrontando se si verificano i seguenti scenari:
-
La versione RES implementata è 2024.01 o successiva.
-
Durante la distribuzione dello stack RES l'attributo for
EnableLdapIDMappingè stato impostato su.True -
Il filesystem home specificato durante l'implementazione dello stack RES è stato utilizzato nella versione precedente a RES 2024.01 o è stato utilizzato in un ambiente precedente con impostato su.
EnableLdapIDMappingFalse
Fasi di risoluzione: eliminare le directory utente nel filesystem.
-
SSM all'host del gestore del cluster.
-
cd /home. -
ls- dovrebbe elencare le directory con nomi di directory che corrispondono ai nomi utenteadmin1,admin2come.. e così via. -
Eliminare le directory,.
sudo rm -r 'dir_name'Non eliminate le directory ssm-user ed ec2-user. -
Se gli utenti sono già sincronizzati con il nuovo env, elimina l'utente dalla tabella DDB dell'utente (eccetto clusteradmin).
-
Avvia la sincronizzazione AD: eseguila
sudo /opt/idea/python/3.9.16/bin/resctl ldap sync-from-adnel gestore di cluster Amazon EC2. -
Riavvia l'istanza VDI nello stato della pagina Web RES.
ErrorVerifica che il VDI passi allo stato in circa 20 minuti.Ready
-
........................
La sessione VDI passa a una schermata vuota dopo l'accesso
Quando una sessione VDI con tipo Console Session è vuota e non risponde dopo l'accesso, significa che il server X è guasto. Ciò è probabilmente dovuto a un problema del sistema operativo in cui DCV sta tentando di trasmettere in streaming il desktop, ma non ce n'è uno da trasmettere. La causa più probabile di ciò è un problema con la configurazione di Xorg. Il seguente comando può essere eseguito per fare meno affidamento sulla configurazione predefinita di Xorg.
Linux basato su Debian:
dpkg-divert --package nice-xdcv --divert /usr/bin/Xorg.orig --rename /usr/bin/Xorg ln -sf /usr/bin/Xdcv-console /usr/bin/Xorg
Linux basato su Red Hat:
rpm -q --whatprovides /usr/bin/Xorg && \ cp /usr/bin/Xorg /usr/bin/Xorg.orig && \ ln -sf /usr/bin/Xdcv-console /usr/bin/Xorg
........................
Componente Virtual Desktop
Argomenti
........................
L'istanza Amazon EC2 viene ripetutamente visualizzata come terminata nella console
Se un'istanza dell'infrastruttura viene ripetutamente visualizzata come terminata nella console Amazon EC2, la causa potrebbe essere correlata alla sua configurazione e dipendere dal tipo di istanza dell'infrastruttura. Di seguito sono riportati i metodi per determinare la causa.
Se l'istanza vdc-controller mostra stati terminati ripetuti nella console Amazon EC2, ciò può essere dovuto a un tag segreto errato. I segreti gestiti da RES hanno tag che vengono utilizzati come parte delle politiche di controllo degli accessi IAM collegate alle istanze dell'infrastruttura Amazon EC2. Se il controller vdc è in esecuzione ciclica e nel gruppo di CloudWatch log viene visualizzato il seguente errore, la causa potrebbe essere che un segreto non è stato etichettato correttamente. Nota che il segreto deve essere etichettato con quanto segue:
{ "res:EnvironmentName": "<envname>" # e.g. "res-demo" "res:ModuleName": "virtual-desktop-controller" }
Il messaggio di CloudWatch log di Amazon relativo a questo errore apparirà simile al seguente:
An error occurred (AccessDeniedException) when calling the GetSecretValue operation: User: arn:aws:sts::160215750999:assumed-role/<envname>-vdc-gateway-role-us-east-1/i-043f76a2677f373d0 is not authorized to perform: secretsmanager:GetSecretValue on resource: arn:aws:secretsmanager:us-east-1:160215750999:secret:Certificate-res-bi-Certs-5W9SPUXF08IB-F1sNRv because no identity-based policy allows the secretsmanager:GetSecretValue action
Controlla i tag sull'istanza Amazon EC2 e verifica che corrispondano all'elenco precedente.
........................
L'istanza vdc-controller è ciclica a causa del mancato accesso al modulo AD/eVDI mostra Failed API Health Check
Se il modulo eVDI non funziona, durante il controllo dello stato dell'ambiente verrà visualizzato quanto segue nella sezione Environment Status.

In questo caso, il percorso generale per il debug consiste nell'esaminare i log del gestore del cluster. CloudWatch<env-name>/cluster-manager
Problemi possibili:
-
Se i log contengono il testo
Insufficient permissions, assicurati che il ServiceAccount nome utente fornito al momento della creazione dello stack res sia digitato correttamente.Esempio di riga di registro:
Insufficient permissions to modify computer account: CN=IDEA-586BD25043,OU=Computers,OU=RES,OU=CORP,DC=corp,DC=res,DC=com: 000020E7: AtrErr: DSID-03153943, #1: 0: 000020E7: DSID-03153943, problem 1005 (CONSTRAINT_ATT_TYPE), data 0, Att 90008 (userAccountControl):len 4 >> 432 ms - request will be retried in 30 seconds-
È possibile accedere al ServiceAccount nome utente fornito durante l'implementazione di RES dalla SecretsManager console
. Trova il segreto corrispondente in Secrets Manager e scegli Recupera testo normale. Se il nome utente non è corretto, scegli Modifica per aggiornare il valore segreto. Termina le istanze correnti di cluster-manager e vdc-controller. Le nuove istanze verranno visualizzate in uno stato stabile. -
Il nome utente deve essere "ServiceAccount" se si utilizzano le risorse create dallo stack di risorse esterne fornito. Se il
DisableADJoinparametro è stato impostato su False durante la distribuzione di RES, assicuratevi che l'utente "ServiceAccount" disponga delle autorizzazioni per creare oggetti Computer in AD.
-
-
Se il nome utente utilizzato era corretto, ma i log contengono il testo
Invalid credentials, la password inserita potrebbe essere errata o scaduta.Esempio di riga di registro:
{'msgtype': 97, 'msgid': 1, 'result': 49, 'desc': 'Invalid credentials', 'ctrls': [], 'info': '80090308: LdapErr: DSID-0C090569, comment: AcceptSecurityContext error, data 532, v4563'}-
Puoi leggere la password che hai inserito durante la creazione dell'ambiente accedendo al segreto che memorizza la password nella console Secrets Manager
. Seleziona il segreto (ad esempio <env_name>directoryserviceServiceAccountPassword) e scegli Recupera testo normale. -
Se la password nel segreto non è corretta, scegli Modifica per aggiornarne il valore nel segreto. Termina le istanze correnti di cluster-manager e vdc-controller. Le nuove istanze utilizzeranno la password aggiornata e si presenteranno in uno stato stabile.
-
Se la password è corretta, è possibile che sia scaduta nell'Active Directory connessa. Dovrai prima reimpostare la password in Active Directory e quindi aggiornare il segreto. È possibile reimpostare la password dell'utente in Active Directory dalla console Directory Service
: -
Scegli l'ID di directory appropriato
-
Scegli Azioni, Reimposta la password dell'utente, quindi compila il modulo con il nome utente (ad esempio, "ServiceAccount«) e la nuova password.
-
Se la password appena impostata è diversa dalla password precedente, aggiorna la password nel segreto del Secret Manager corrispondente (ad esempio,
<env_name>directoryserviceServiceAccountPassword. -
Termina le istanze correnti di cluster-manager e vdc-controller. Le nuove istanze verranno visualizzate in uno stato stabile.
-
-
........................
Il progetto non viene visualizzato nel menu a discesa quando si modifica lo stack software per aggiungerlo
Questo problema può essere correlato al seguente problema associato alla sincronizzazione dell'account utente con AD. Se si verifica questo problema, verifica l'errore "<user-home-init> account not available yet. waiting for user to be synced" nel gruppo di CloudWatch log Amazon cluster-manager per determinare se la causa è la stessa o correlata.
........................
Il CloudWatch log di Amazon cluster-manager mostra «l'>account < user-home-init non è ancora disponibile in attesa della sincronizzazione dell'utente» (dove l'account è un nome utente)
L'abbonato SQS è occupato e bloccato in un ciclo infinito perché non può accedere all'account utente. Questo codice viene attivato quando si tenta di creare un filesystem home per un utente durante la sincronizzazione dell'utente.
Il motivo per cui non è possibile accedere all'account utente potrebbe essere che RES non è stato configurato correttamente per l'AD in uso. Un esempio potrebbe essere che il ServiceAccountCredentialsSecretArn parametro utilizzato per la creazione BI/RES dell'ambiente non era il valore corretto.
........................
Il desktop di Windows al tentativo di accesso dice «Il tuo account è stato disabilitato. Rivolgiti al tuo amministratore»

Se l'utente non è in grado di accedere nuovamente a una schermata bloccata, ciò potrebbe indicare che l'utente è stato disabilitato nell'AD configurato per RES dopo aver effettuato correttamente l'accesso tramite SSO.
L'accesso SSO dovrebbe fallire se l'account utente è stato disabilitato in AD.
........................
Problemi relativi alle opzioni DHCP con external/customer la configurazione AD
Se riscontri un errore durante l'utilizzo di "The connection has been closed. Transport
error" desktop virtuali Windows quando usi RES con il tuo Active Directory, controlla il registro CloudWatch Amazon dcv-connection-gateway per qualcosa di simile al seguente:
Oct 28 00:12:30.626 INFO HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Connection initiated error: unreachable, server io error Custom { kind: Uncategorized, error: "failed to lookup address information: Name or service not known" } Oct 28 00:12:30.626 WARN HTTP:Splicer Connection{id=263}: Websocket{session_id="96cffa6e-cf2e-410f-9eea-6ae8478dc08a"}: Error in websocket connection: Server unreachable: Server error: IO error: failed to lookup address information: Name or service not known Oct 28 00:12:30.627 DEBUG HTTP:Splicer Connection{id=263}: ConnectionGuard dropped
Se utilizzi un controller di dominio AD per le opzioni DHCP per il tuo VPC, devi:
-
Aggiungere AmazonProvided DNS ai due IP dei controller di dominio.
-
Imposta il nome di dominio su ec2.internal.
Un esempio è mostrato qui. Senza questa configurazione, il desktop di Windows restituirà l'errore Transport, perché RES/DCV cerca ip-10-0-x-xx.ec2.internal hostname.

........................
Errore Firefox MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING
Quando si utilizza il browser Web Firefox, è possibile che venga visualizzato il messaggio di errore del tipo MOZILLA_PKIX_ERROR_REQUIRED_TLS_FEATURE_MISSING quando si tenta di connettersi a un desktop virtuale.
La causa è che il server web RES è configurato con TLS + Stapling On ma non risponde con Stapling Validation (vedi. https://support.mozilla.org/en-US/questions/1372483
Puoi risolvere questo problema seguendo le istruzioni su:. https://really-simple-ssl.com/mozilla_pkix_error_required_tls_feature_missing
........................
Eliminazione di Env
Argomenti
........................
Lo stack res-xxx-cluster si trova nello stato «DELETE_FAILED» e non può essere eliminato manualmente a causa dell'errore «Il ruolo non è valido o non può essere assunto»
Se noti che lo stack «res-xxx-cluster» è nello stato «DELETE_FAILED» e non può essere eliminato manualmente, puoi eseguire le seguenti operazioni per eliminarlo.
Se vedi lo stack nello stato «DELETE_FAILED», prova innanzitutto a eliminarlo manualmente. Potrebbe apparire una finestra di dialogo che conferma Delete Stack. Scegli Elimina.
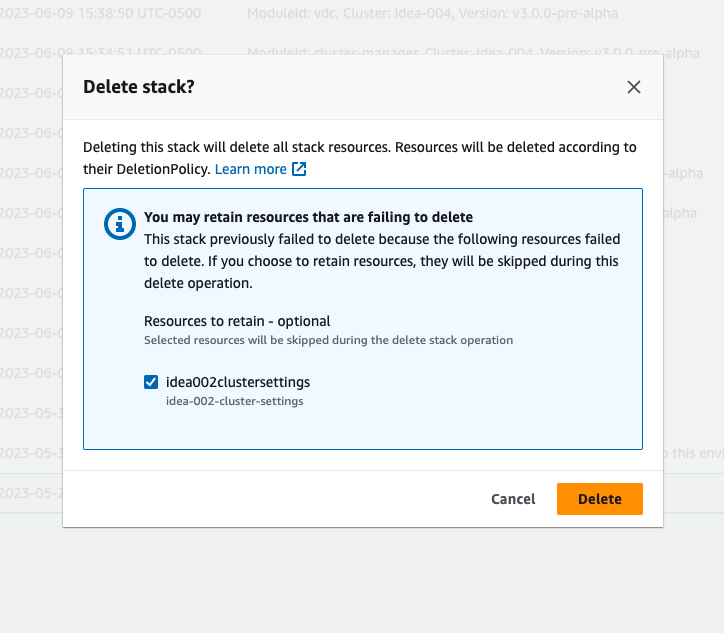
A volte, anche se elimini tutte le risorse dello stack richieste, potresti comunque visualizzare il messaggio che richiede di selezionare le risorse da conservare. In tal caso, seleziona tutte le risorse come «risorse da conservare» e scegli Elimina.
È possibile che venga visualizzato un errore simile a Role: arn:aws:iam::... is Invalid or cannot
be assumed
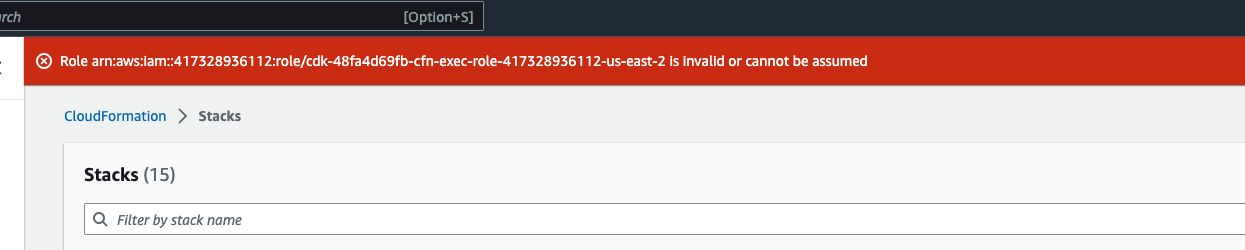
Ciò significa che il ruolo richiesto per eliminare lo stack è stato eliminato prima dello stack. Per ovviare a questo problema, copia il nome del ruolo. Vai alla console IAM e crea un ruolo con quel nome utilizzando i parametri mostrati qui, che sono:
-
Per il tipo di entità affidabile scegli AWSil servizio.
-
Per il caso d'uso, in
Use cases for otherAWS servicesScegliCloudFormation.

Scegli Next (Successivo). Assicurati di concedere le autorizzazioni al ruolo AWSCloudFormationFullAccess «» e AdministratorAccess «». La tua pagina di recensione dovrebbe avere il seguente aspetto:

Quindi torna alla CloudFormation console ed elimina lo stack. Ora dovresti essere in grado di eliminarlo dopo aver creato il ruolo. Infine, vai alla console IAM ed elimina il ruolo che hai creato.
........................
Raccolta dei registri
Accesso a un'istanza EC2 dalla console EC2
-
Segui queste istruzioni per accedere alla tua istanza Linux EC2.
-
Segui queste istruzioni per accedere alla tua istanza Windows EC2. Quindi apri Windows PowerShell per eseguire qualsiasi comando.
Raccolta dei registri degli host dell'infrastruttura
-
Cluster-manager: Ottieni i log per il gestore del cluster dai seguenti punti e allegali al ticket.
-
Tutti i log del gruppo di CloudWatch log.
<env-name>/cluster-manager -
Tutti i log
/root/bootstrap/logsnella directory sull'istanza<env-name>-cluster-managerEC2. Segui le istruzioni riportate in «Accesso a un'istanza EC2 dalla console EC2» all'inizio di questa sezione per accedere alla tua istanza.
-
-
Vdc-controller: Recupera i log per il controller vdc dai seguenti punti e allegali al ticket.
-
Tutti i log del gruppo di log. CloudWatch
<env-name>/vdc-controller -
Tutti i log
/root/bootstrap/logsnella directory sull'istanza<env-name>-vdc-controllerEC2. Segui le istruzioni riportate in «Accesso a un'istanza EC2 dalla console EC2» all'inizio di questa sezione per accedere alla tua istanza.
-
Uno dei modi per ottenere facilmente i log è seguire le istruzioni contenute nella sezione. Scaricamento dei log dalle istanze Linux EC2 Il nome del modulo sarebbe il nome dell'istanza.
Raccolta dei registri VDI
- Identifica l'istanza Amazon EC2 corrispondente
-
Se un utente avviasse una VDI con nome di sessione
VDI1, il nome corrispondente dell'istanza sulla console Amazon EC2 sarebbe.<env-name>-VDI1-<user name> - Raccogli i log VDI di Linux
-
Accedi all'istanza Amazon EC2 corrispondente dalla console Amazon EC2 seguendo le istruzioni collegate a «Accesso a un'istanza EC2 dalla console EC2» all'inizio di questa sezione. Ottieni tutti i log
/var/log/dcv/nelle directory/root/bootstrap/logsand sull'istanza VDI Amazon EC2.Uno dei modi per ottenere i log sarebbe caricarli su s3 e poi scaricarli da lì. Per questo, puoi seguire questi passaggi per ottenere tutti i log da una directory e poi caricarli:
-
Segui questi passaggi per copiare i log dcv nella directory:
/root/bootstrap/logssudo su - cd /root/bootstrap mkdir -p logs/dcv_logs cp -r /var/log/dcv/* logs/dcv_logs/ -
Ora, segui i passaggi elencati nella prossima sezione Scaricamento dei registri VDI per scaricare i log.
-
- Raccogli i registri VDI di Windows
-
Accedi all'istanza Amazon EC2 corrispondente dalla console Amazon EC2 seguendo le istruzioni collegate a «Accesso a un'istanza EC2 dalla console EC2» all'inizio di questa sezione. Ottieni tutti i log nella
$env:SystemDrive\Users\Administrator\RES\Bootstrap\Log\directory dell'istanza VDI EC2.Uno dei modi per ottenere i log sarebbe caricarli su S3 e poi scaricarli da lì. Per farlo, segui i passaggi elencati nella sezione successiva-. Scaricamento dei registri VDI
........................
Scaricamento dei registri VDI
Aggiorna il ruolo IAM dell'istanza VDI EC2 per consentire l'accesso a S3.
Vai alla console EC2 e seleziona la tua istanza VDI.
Seleziona il ruolo IAM che sta utilizzando.
-
Nella sezione Politiche di autorizzazione dal menu a discesa Aggiungi autorizzazioni, scegli Allega politiche, quindi seleziona la AmazonS3FullAccesspolitica.
Scegli Aggiungi autorizzazioni per allegare quella politica.
-
Dopodiché, segui i passaggi elencati di seguito in base al tipo di VDI in uso per scaricare i log. Il nome del modulo sarebbe il nome dell'istanza.
-
Infine, modifica il ruolo per rimuovere la
AmazonS3FullAccesspolitica.
Nota
Tutti i VDI utilizzano lo stesso ruolo IAM che è <env-name>-vdc-host-role-<region>
........................
Scaricamento dei log dalle istanze Linux EC2
Accedi all'istanza EC2 da cui desideri scaricare i log ed esegui i seguenti comandi per caricare tutti i log in un bucket s3:
sudo su - ENV_NAME=<environment_name>REGION=<region>ACCOUNT=<aws_account_number>MODULE=<module_name>cd /root/bootstrap tar -czvf ${MODULE}_logs.tar.gz logs/ --overwrite aws s3 cp ${MODULE}_logs.tar.gz s3://${ENV_NAME}-cluster-${REGION}-${ACCOUNT}/${MODULE}_logs.tar.gz
Dopodiché, vai alla console S3, seleziona il bucket con il nome <environment_name>-cluster-<region>-<aws_account_number> e scarica il file precedentemente caricato. <module_name>_logs.tar.gz
........................
Scaricamento dei log dalle istanze di Windows EC2
Accedi all'istanza EC2 da cui desideri scaricare i log ed esegui i seguenti comandi per caricare tutti i log in un bucket S3:
$ENV_NAME="<environment_name>" $REGION="<region>" $ACCOUNT="<aws_account_number>" $MODULE="<module_name>" $logDirPath = Join-Path -Path $env:SystemDrive -ChildPath "Users\Administrator\RES\Bootstrap\Log" $zipFilePath = Join-Path -Path $env:TEMP -ChildPath "logs.zip" Remove-Item $zipFilePath Compress-Archive -Path $logDirPath -DestinationPath $zipFilePath $bucketName = "${ENV_NAME}-cluster-${REGION}-${ACCOUNT}" $keyName = "${MODULE}_logs.zip" Write-S3Object -BucketName $bucketName -Key $keyName -File $zipFilePath
Dopodiché, vai alla console S3, seleziona il bucket con il nome <environment_name>-cluster-<region>-<aws_account_number> e scarica il file precedentemente caricato. <module_name>_logs.zip
........................
Raccolta dei log ECS relativi all'errore WaitCondition
-
Vai allo stack distribuito e seleziona la scheda Risorse.
-
Espandi Deploy → ResearchAndEngineeringStudio→ Installer → Tasks → → CreateTaskDefCreateContainer→ LogGroupe seleziona il gruppo di log per aprire i log. CloudWatch
-
Recupera il registro più recente da questo gruppo di log.
........................
Errore di cancellazione dell'interfaccia di rete
Se noti un errore di detachvpcfromlambdacustomresource eliminazione nella sezione Eventi dell'eliminazione dello stack di RES finalizer, molto probabilmente significa che il servizio Lambda non è riuscito a eliminare o non ha eliminato in tempo le interfacce di rete collegate a RES Lambdas.
Puoi eliminare manualmente queste interfacce di rete obsolete accedendo alla pagina Interfacce di rete all'interno della console Amazon EC2 e filtrandole in base alle descrizioni che le contengonoAWS Lambda VPC ENI- Dovrebbero esserci fino a 14 interfacce di rete, anche se potrebbero essere meno a seconda del numero di interfacce Lambda che Lambda è riuscita a eliminare. Elimina manualmente queste interfacce di rete, quindi riavvia l'eliminazione dello stack RES.{RES-Environment-Name}
Ambiente dimostrativo
Argomenti
........................
Errore di accesso all'ambiente demo durante la gestione della richiesta di autenticazione al provider di identità
Problema
Se tenti di accedere e ricevi un «Errore imprevisto durante la gestione della richiesta di autenticazione al provider di identità», le tue password potrebbero essere scadute. Potrebbe essere la password dell'utente con cui stai tentando di accedere o il tuo account di Active Directory Service.
Attenuazione
-
Reimposta le password degli utenti e degli account di servizio nella console del servizio Directory
. -
Aggiorna le password degli account di servizio in Secrets Manager
in modo che corrispondano alla nuova password che hai inserito sopra: -
per lo stack Keycloak: -... PasswordSecret - ResExternal -... - DirectoryService-... con descrizione: Password per Microsoft Active Directory
-
per RES: res- ServiceAccountPassword -... con descrizione: password dell'account del servizio Active Directory Service
-
-
Vai alla console EC2
e termina l'istanza del gestore del cluster. Le regole di Auto Scaling attiveranno automaticamente la distribuzione di una nuova istanza.
........................
Il keycloak dello stack demo non funziona
Problema
Se il server keycloak si è bloccato e, al riavvio del server, l'IP dell'istanza è cambiato, ciò potrebbe aver provocato l'interruzione del keycloak: la pagina di accesso del portale RES non viene caricata o si blocca in uno stato di caricamento che non si risolve mai.
Attenuazione
Dovrai eliminare l'infrastruttura esistente e ridistribuire lo stack Keycloak per ripristinare Keycloak a uno stato integro. Completare la procedura riportata di seguito.
-
Vai a Cloudformation. Lì dovreste vedere due pile relative al keycloak:
-
<env-name>-RESSsoKeycloak-<random characters><env-name>-RESSsoKeycloak-<random characters>-RESSsoKeycloak-*
-
-
Elimina Stack1. Se viene richiesto di eliminare lo stack nidificato, selezionate Sì per eliminare lo stack nidificato.
Assicurati che lo stack sia stato eliminato completamente.
-
Distribuisci questo stack manualmente con gli stessi valori di parametro dello stack eliminato. Distribuiscilo dalla CloudFormation console andando su Crea stack → Con nuove risorse (standard) → Scegli un modello esistente → Carica un file modello. Compila i parametri richiesti utilizzando gli stessi input dello stack eliminato. Puoi trovare questi input nello stack eliminato cambiando il filtro sulla CloudFormation console e andando alla scheda Parametri. Assicurati che il nome dell'ambiente, la key pair e gli altri parametri corrispondano ai parametri dello stack originale.
-
Una volta distribuito lo stack, l'ambiente è pronto per essere riutilizzato. Puoi trovarlo ApplicationUrl nella scheda Output dello stack distribuito.
........................
Problemi con Active Directory
Argomenti
La mia VDI è bloccata nello stato di provisioning da molto tempo oppure non riesco ad accedere alla mia VDI come utente AD dopo che la VDI è pronta
Controlla innanzitutto i registri di installazione e configurazione VDI (/root/bootstrap/logs/e /opt/idea/app/logs/ le directory per Linux o C:\Users\Administrator\RES\Bootstrap\Log\ le directory per Windows) per eventuali C:\Program Files\RES\app\logs\ errori di installazione o configurazione.
Se viene visualizzato un messaggio di errore che indica che l'istanza non è riuscita ad accedere ad Active Directory, in genere ciò è dovuto al fatto che Cluster Manager non è in grado di preimpostare l'account del computer per l'istanza nell'AD. Controlla i log di Cluster Manager nel gruppo di / CloudWatch log e filtra i messaggi di errore che contengono. environment-name/cluster-manager[preset-computer] I problemi comuni includono:
-
Le credenziali per l'account del servizio AD non sono valide.
-
Controlla il segreto dell'account di servizio che hai fornito a RES. Assicurati che il nome utente e la password siano forniti come coppia chiave-valore
{e che le credenziali siano valide. Dovrai eseguire un ciclo dell'istanza di Cluster Manager terminando l'istanza esistente e consentendo al gruppo di scalabilità automatica di avviarne una nuova automaticamente dopo aver modificato il segreto dell'account di servizio. Quindi avvia nuovi VDI per applicare la modifica.username:password}
-
-
Service Account non dispone dell'autorizzazione per creare account di computer in AD.
-
Assicurati che il tuo account di servizio disponga di tutte le autorizzazioni richieste elencate inConfigurare un account di servizio per Microsoft Active Directory. Dovrai avviare nuovi VDI dopo aver corretto le autorizzazioni del Service Account in AD.
-
-
Impossibile connettersi al server LDAP.
-
Assicurati che la tua configurazione AD consenta la LDAP/LDAPS connessione all'interno del VPC e che l'opzione DHCP del tuo VPC sia impostata correttamente dopo aver creato o modificato un set di opzioni DHCP per Managed AWS Microsoft AD se utilizzi Managed Microsoft AD. AWS
-
Per la connessione LDAPS, il
DomainTLSCertificateSecretArnparametro è obbligatorio ed è necessario fornire un certificato CA valido per proteggere la connessione. Dovrai ciclicamente l'istanza di Cluster Manager terminando l'istanza esistente e consentendo al gruppo di scalabilità automatica di avviarne una nuova automaticamente dopo aver modificato il segreto del certificato TLS. Quindi avvia nuovi VDI per applicare la modifica. -
Per testare la connessione tra RES e AD, esegui il seguente comando ldapsearch sull'istanza di Cluster Manager (sostituisci l'unità organizzativa Users, l'URI di connessione LDAP, il nome utente e la password dell'account di servizio). Questo comando dovrebbe restituire tutti gli utenti dell'unità organizzativa fornita se l'AD è configurato correttamente per consentire la connessione.
ldapsearch -x -b "OU=Users,OU=RES,OU=CORP,DC=corp,DC=res,DC=com" -D "ServiceAccount@corp.res.com" -H ldap://corp.res.com -wservice-account-password"(objectClass=group)"
-
Se imposti DisableAdJoin su true durante l'installazione di RES, i tuoi VDI Linux si connettono solo ad Active Directory invece di unirsi a esso tramite il servizio SSSD. Connect alla tua istanza VDI dalla console EC2 ed esegui il comando id su di essa. Se il comando non è in grado di restituire l'UID/GID dell'utente AD corrispondente, controlla lo stato del servizio SSSD utilizzando il comando usernamesudo systemctl status sssd sull'istanza VDI e i log del servizio SSSD presenti nella directory. /var/log/sssd/
Se è necessario personalizzare le configurazioni SSSD per connettersi all'AD, è possibile modificare manualmente il file di configurazione SSSD (/etc/sssd/sssd.conf) e riavviare il servizio SSSD utilizzando il comando sudo systemctl restart sssd sull'host infra/VDI (versione 2024.12.01 e precedenti), oppure fornire configurazioni SSSD aggiuntive dal portale Web RES, Sincronizzazione con Active Directory che verranno applicate automaticamente ai VDI esistenti o nuovi (versione 2025.03 e successive).
........................
Non riesco ad accedere al portale web RES dopo aver configurato l'SSO
Controlla le tabelle environment-name.accounts.usersenvironment-name.accounts.groups/ CloudWatch log (precedente alla versione 2024.12) o nel gruppo di environment-name/cluster-manager/ CloudWatch log (versione 2024.12 e successive).environment-name/ad-sync
Oltre ai comuni problemi di configurazione AD menzionati in, altri errori possono includere: La mia VDI è bloccata nello stato di provisioning da molto tempo oppure non riesco ad accedere alla mia VDI come utente AD dopo che la VDI è pronta
-
L'account di servizio non dispone dell'autorizzazione per interrogare utenti e gruppi in AD.
-
Assicurati che il tuo account di servizio disponga di tutte le autorizzazioni richieste elencate inConfigurare un account di servizio per Microsoft Active Directory.
-
-
Agli utenti/gruppi in Active Directory mancano gli attributi obbligatori come l'indirizzo e-mail.
-
Aggiorna gli attributi utente/gruppo di conseguenza per risolvere il problema.
-
Dopo aver risolto il problema di sincronizzazione AD, puoi attendere la successiva sincronizzazione AD pianificata che si verifica ogni ora o attivarla manualmente seguendo le istruzioni in Come eseguire manualmente la sincronizzazione (release 2024.12 e 2024.12.01) (versione 2024.12 e 2024.12.01) o Come avviare o interrompere manualmente la sincronizzazione (versione 2025.03 e successive) (versione 2025.03 e successive).
........................
L'utente AD non può accedere alla home directory utilizzando File Browser anche dopo aver avviato con successo i VDI Linux
Verifica se l'utente AD è visibile in Cluster Manager eseguendo il comando id sull'istanza di Cluster Manager. Se il comando non è in grado di restituire l'UID/GID dell'utente AD corrispondente, controlla i log di Cluster Manager nel gruppo di username/ CloudWatch log e cerca eventuali errori relativi all'avvio del servizio SSSD. Se non ci sono errori nei log di Cluster Manager, controlla lo stato del servizio SSSD utilizzando il comando environment-name/cluster-managersudo systemctl status sssd sull'istanza di Cluster Manager e i log del servizio SSSD nella directory. /var/log/sssd/
Se l'utente AD è visibile al Cluster Manager, controlla l'UID/GID nella home directory dell'utente () /home/ eseguendo il comando. usernamels -n /home Confronta l'UID/ GID della home directory dell'utente con l'UID/ GID restituito dal comando. id Se l'UID/GID non corrisponde, significa che la home directory dell'utente potrebbe essere stata creata al di fuori di RES o da una precedente distribuzione RES. Esegui il backup di tutti i dati utente importanti, elimina la home directory e avvia una nuova VDI Linux con l'utente. La home directory verrà ricreata con l'UID/GID appropriati dopo il corretto provisioning del nuovo VDI.username
........................
L'utente amministratore di AD non può accedere a Bastion Host dopo aver abilitato l'accesso SSH
Verifica se l'utente AD è visibile su Bastion Host eseguendo il comando id sull'istanza Bastion Host. Se il comando non è in grado di restituire l'UID/GID dell'utente AD corrispondente, controlla i log di Bastion Host nel gruppo di username/ CloudWatch log e cerca eventuali errori sull'avvio del servizio SSSD. Se non ci sono errori nei log di Bastion Host, controlla lo stato del servizio SSSD utilizzando il comando environment-name/bastion-hostsudo systemctl status sssd sull'istanza Bastion Host e i log del servizio SSSD nella directory. /var/log/sssd/
........................
Visualizza e gestisci il mio Active Directory distribuito dallo stack di risorse esterne RES
Se la tua Active Directory AWS gestita viene distribuita da uno stack di risorse esterno RES, dovrebbe esserci un'istanza con un nome che inizia con AdDomainWindowsNode- distribuita sotto il tuo AWS account che possa essere utilizzata per accedere e gestire Active Directory. Puoi accedere all'istanza tramite Fleet Manager nella console EC2 con le seguenti credenziali:external-resource-stack-name-WindowsManagementHost
nome utente: Admin
password: AdminPassword parametro fornito durante la distribuzione dello stack di risorse esterne
Per gestire la tua Active Directory AWS gestita, consulta Gestisci utenti e gruppi con un'istanza Amazon EC2 nella AWSDirectory Service Administration Guide.
........................
