Amazon Redshift non supporterà più la creazione di nuove UDF Python a partire dalla Patch 198. Le UDF Python esistenti continueranno a funzionare fino al 30 giugno 2026. Per ulteriori informazioni, consulta il post del blog
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Scoprire i concetti di Amazon Redshift
Amazon Redshift serverless consente di accedere e analizzare i dati senza le configurazioni di un data warehouse con provisioning. Viene eseguito automaticamente il provisioning delle risorse e la capacità del data warehouse viene dimensionata in modo intelligente per fornire prestazioni rapide per carichi di lavoro maggiormente impegnativi e imprevedibili. Quando il data warehouse è inattivo non vengono addebitati costi, si paga solo l'utilizzo. Puoi caricare i dati e iniziare subito a eseguire query nell'editor di query Amazon Redshift v2 o nello strumento di business intelligence (BI) preferito. È possibile usufruire del miglior rapporto prezzo/prestazioni e delle funzionalità SQL familiari in un ambiente facile da usare e senza alcuna amministrazione.
Se Amazon Redshift viene utilizzato per la prima volta, consigliamo di iniziare leggendo le seguenti sezioni:
-
Panoramica delle funzionalità di Amazon Redshift serverless: in questo argomento viene riportata una panoramica di Amazon Redshift serverless e le sue funzionalità principali.
-
Punti salienti del servizio e prezzi
: in questa pagina del prodotto sono disponibili i dettagli sui punti salienti e sui prezzi del servizio Amazon Redshift serverless. -
Nozioni di base sui data warehouse Amazon Redshift serverless in questo argomento puoi scoprire ulteriori informazioni su come creare un data warehouse Amazon Redshift serverless e iniziare a eseguire query sui dati utilizzando Query Editor V2.
Se preferisci gestire le risorse Amazon Redshift manualmente, puoi creare cluster con provisioning per le proprie esigenze di query sui dati. Per ulteriori informazioni, consultare Cluster Amazon Redshift.
Se la tua organizzazione è idonea e il tuo cluster viene creato in un Regione AWS paese in cui Amazon Redshift Serverless non è disponibile, potresti essere in grado di creare un cluster nell'ambito del programma di prova gratuita di Amazon Redshift. Scegli Produzione o Versione di prova gratuita per rispondere alla domanda Per cosa si intende utilizzare questo cluster? Se scegli Versione di prova gratuita, crei una configurazione con il tipo di nodo dc2.large. Per ulteriori informazioni sulla scelta di una versione prova gratuita, consulta Prova gratuita di Amazon Redshift
Di seguito sono riportati alcuni concetti chiave di Amazon Redshift serverless.
-
Spazio dei nomi: una raccolta di oggetti di database e utenti. Gli spazi dei nomi raggruppano tutte le risorse utilizzate in Amazon Redshift serverless, come schemi, tabelle, utenti, unità di condivisione dati e snapshot.
-
Gruppo di lavoro: una raccolta di risorse di calcolo. I gruppi di lavoro ospitano le risorse di calcolo utilizzate da Amazon Redshift serverless per eseguire attività di calcolo. Alcuni esempi di tali risorse includono le unità di elaborazione Redshift (RPU), i gruppi di sicurezza, i limiti di utilizzo. I gruppi di lavoro dispongono di impostazioni di rete e sicurezza che puoi configurare utilizzando la console Amazon Redshift Serverless, o AWS Command Line Interface le API Amazon Redshift Serverless.
Per ulteriori informazioni sulla configurazione dello spazio dei nomi e delle risorse del gruppo di lavoro, consulta Utilizzo dello spazio dei nomi e Utilizzo dei gruppi di lavoro.
Di seguito sono riportati alcuni concetti chiave sui cluster con provisioning di Amazon Redshift:
-
Cluster – Il componente centrale dell'infrastruttura di un data warehouse di Amazon Redshift è un cluster.
Un cluster è costituito da uno o più nodi di calcolo. I nodi di calcolo eseguono il codice compilato.
Se viene effettuato il provisioning di un cluster con due o più nodi di calcolo, un ulteriore nodo principale coordina i nodi di calcolo. Il nodo leader gestisce la comunicazione esterna con applicazioni, come strumenti di business intelligence e editor di query. L'applicazione client interagisce direttamente solo con il nodo principale. I nodi di calcolo sono trasparenti alle applicazioni esterne.
-
Database – Un cluster contiene uno o più database.
I dati utente vengono archiviati in uno o più database nei nodi di calcolo. Il client SQL comunica con il nodo principale, che a sua volta coordina l’esecuzione di query con i nodi di calcolo. Per dettagli sui nodi di calcolo e sui nodi principali, consulta Architettura del sistema di data warehouse All'interno di un database, i dati utente sono organizzati in uno o più schemi.
Amazon Redshift è un sistema di gestione di database relazionali (RDBMS, Relational Database Management System) ed è compatibile con altre applicazioni RDBMS. Offre le stesse funzionalità delle tipiche applicazioni RDBMS, tra cui funzioni di elaborazione di transazioni online (OLTP) come l'inserimento e l'eliminazione di dati. Amazon Redshift è inoltre ottimizzato per l'analisi batch ad alte prestazioni e la creazione di report dei set di dati.
Di seguito, puoi trovare una descrizione del tipico flusso di elaborazione dei dati in Amazon Redshift, insieme alle descrizioni delle diverse parti del flusso. Per ulteriori informazioni sull'architettura di sistema Amazon Redshift, consulta Architettura del sistema di data warehouse.
Il diagramma seguente illustra un tipico flusso di elaborazione dati in Amazon Redshift.
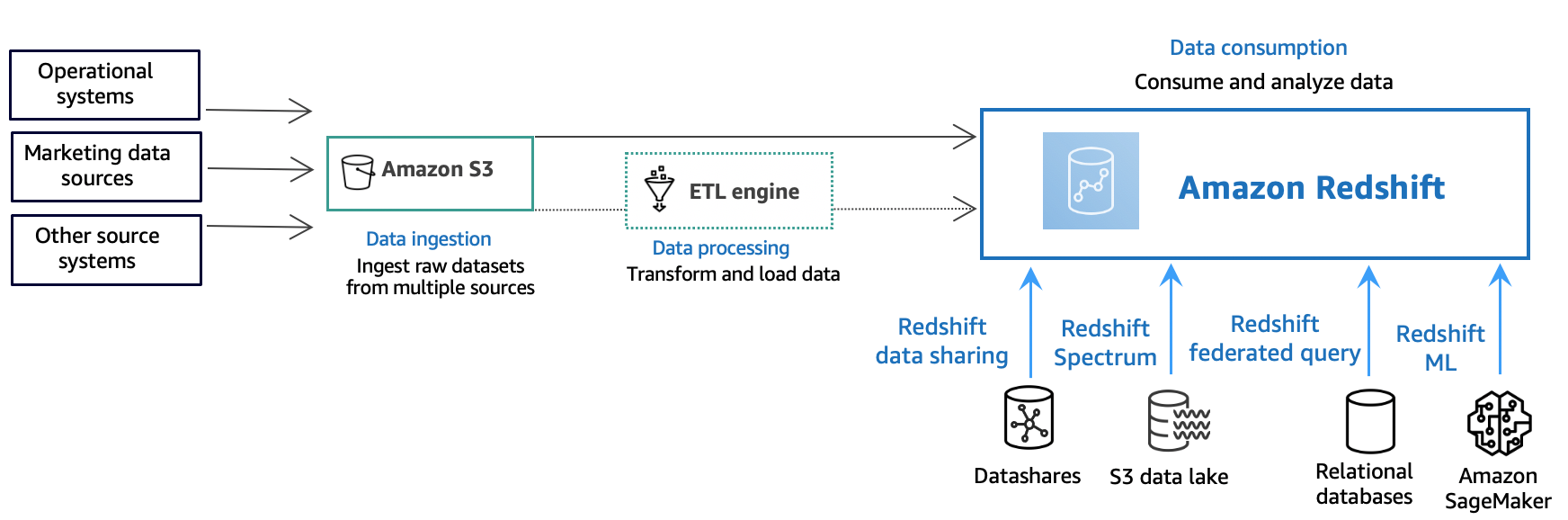
Un data warehouse di Amazon Redshift è un sistema di query e gestione di database relazionali di livello aziendale. Amazon Redshift supporta connessioni client con molti tipi di applicazioni, tra cui strumenti di business intelligence, creazione di report, gestione dei dati e analisi. Attraverso l'esecuzione di query di analisi, puoi recuperare, confrontare e valutare grandi quantità di dati in operazioni in più fasi per produrre un risultato finale.
A livello di importazione dei dati, diversi tipi di origini dati caricano continuamente dati strutturati, semistrutturati o non strutturati sul livello di archiviazione di dati. Questa area di archiviazione dei dati funge da area di gestione temporanea che memorizza i dati in diversi stati di preparazione al consumo. Un esempio di storage potrebbe essere un bucket Amazon Simple Storage Service (Amazon S3).
Al facoltativo livello elaborazione dati, i dati di origine passano attraverso la preelaborazione, la convalida e la trasformazione utilizzando pipeline di estrazione, trasformazione, caricamento (ETL) o di estrazione, caricamento, trasformazione (ELT). Questi set di dati grezzi vengono quindi perfezionati utilizzando le operazioni ETL. Un esempio di motore ETL è AWS Glue.
Presso il livello consumo di dati, i dati vengono caricati nel cluster Amazon Redshift, dove è possibile eseguire carichi di lavoro analitici.
Per alcuni esempi di carichi di lavoro analitici, consulta Esecuzione di query all'esterno delle origini dati.
