Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Comprendere LLM e RAG
Per capire come il miglioramento della qualità dei documenti di origine migliori la qualità di una risposta RAG, è necessario comprendere il funzionamento interno di un LLM. Il vero potere dei LLM risiede nella loro capacità di utilizzare meccanismi di autoattenzione e architetture di trasformazione. Queste tecniche avanzate consentono ai modelli di elaborare e mettere in relazione in modo efficace diverse parti della sequenza di input, indipendentemente dalla loro posizione o distanza all'interno del testo. Questa funzionalità è in netto contrasto con i modelli linguistici tradizionali, che spesso hanno difficoltà a gestire dipendenze a lungo termine e a comprendere il contesto. Inoltre, i LLM vengono formati su una scala senza precedenti. Alcuni dei modelli più grandi comprendono trilioni di parametri e hanno assorbito terabyte di dati testuali da diverse fonti. Questa vasta scala consente agli LLM di sviluppare una comprensione approfondita del linguaggio, cogliendo sfumature sottili, idiomi e segnali contestuali che in precedenza erano difficili per i sistemi di intelligenza artificiale. Il risultato è una classe di modelli in grado di generare un testo coerente e scorrevole e dimostrare capacità straordinarie in attività come la risposta alle domande, il riepilogo del testo e persino la generazione di codice.
Per utilizzare questi modelli, possiamo rivolgerci a servizi come Amazon Bedrock, che fornisce l'accesso a una varietà di modelli di base di Amazon e di fornitori terzi, tra cui Anthropic, Cohere e Meta. Puoi usare Amazon Bedrock per sperimentare modelli all'avanguardia, personalizzarli e perfezionarli o incorporarli nelle tue soluzioni generative AI-powered tramite un'unica API.
Sebbene i LLM siano eccellenti nell'acquisizione di modelli e nella generazione di testo coerente, spesso non hanno accesso a informazioni aggiornate o specializzate. RAG combina la potenza generativa dei LLM con un componente di recupero in grado di accedere e incorporare le informazioni pertinenti da fonti esterne, come parte del prompt LLM materializzato. Esempi di fonti esterne includono Knowledge Base per Amazon Bedrock, sistemi di ricerca intelligenti come Amazon Kendra o database vettoriali come Amazon Service. OpenSearch
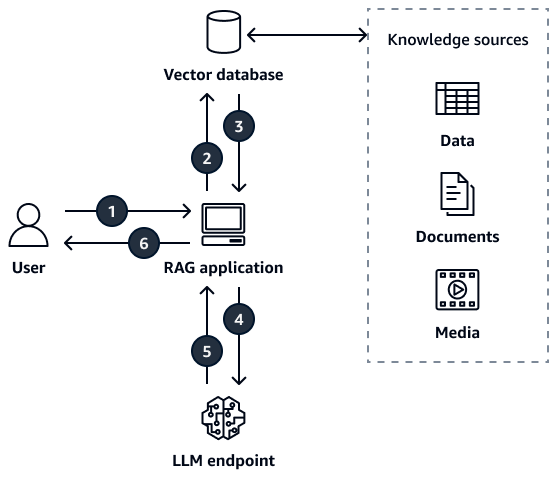
Il diagramma descrive il seguente flusso di lavoro:
-
L'utente invia una query all'applicazione RAG.
-
L'applicazione RAG interroga un database vettoriale che contiene fonti di conoscenza, come documenti, dati o contenuti multimediali.
-
L'applicazione RAG recupera le informazioni pertinenti dal database vettoriale in base alle somiglianze semantiche tra la query e i documenti archiviati.
-
L'applicazione RAG amplia il prompt originale con il contesto recuperato e lo invia all'endpoint LLM.
-
L'endpoint LLM genera una risposta e la restituisce all'applicazione RAG.
-
L'applicazione RAG restituisce la risposta generata all'utente.
Fondamentalmente, RAG utilizza un processo in due fasi. Nella prima fase, un modello di recupero identifica e recupera i documenti o i passaggi pertinenti in base alla query di input. Questo modello di recupero può essere un sistema di recupero delle informazioni tradizionale, un modello di recupero ad alta densità o una combinazione di entrambi. Nella seconda fase, le informazioni recuperate e la query originale vengono inserite in un LLM come modello di prompt completamente materializzato. I LLM dipendono in larga misura dalla qualità del contenuto sorgente fornito dal componente retriever. Applicano un meccanismo di autoattenzione per codificare matematicamente il modo in cui il contenuto recuperato si riferisce all'attività. L'LLM genera quindi una risposta basata sia sulla domanda che sulle informazioni recuperate. In RAG, il controllo della qualità dei documenti sorgente recuperati rappresenta un mezzo diretto per migliorare la rappresentazione interna di un compito da parte di un LLM. RAG amplia efficacemente i dati di formazione del LLM con dati esterni pertinenti. Questo approccio consente a RAG di sfruttare i punti di forza dei LLM e dei sistemi di recupero, consentendo la generazione di risposte più accurate e informate che incorporano conoscenze attuali e specializzate.
Vettori e incorporamenti
I vettori e gli incorporamenti sono concetti fondamentali nell'apprendimento automatico e nell'elaborazione del linguaggio naturale. I vettori sono oggetti matematici che rappresentano quantità che hanno sia grandezza che direzione. Nel contesto dell'elaborazione del linguaggio naturale (NLP), parole, frasi o documenti sono spesso rappresentati come vettori in spazi vettoriali ad alta dimensione. Gli incorporamenti, d'altra parte, sono un modo per rappresentare oggetti come parole o documenti in uno spazio vettoriale di dimensioni inferiori in cui le relazioni tra i vettori catturano somiglianze semantiche o sintattiche. Gli incorporamenti di parole, ad esempio, consentono a parole con significati simili di avere rappresentazioni vettoriali simili. Questo aiuta gli algoritmi a comprendere ed elaborare il linguaggio in modo più efficace.
Database vettoriali
Nell'intelligenza artificiale generativa, un database vettoriale è un database che archivia e gestisce rappresentazioni vettoriali di documenti, query o altri oggetti. È progettato per archiviare e recuperare i vettori in modo efficiente. Ciò supporta operazioni veloci e scalabili come la ricerca semantica e la corrispondenza per somiglianza. I database vettoriali indicizzano i vettori utilizzando strutture di dati specializzate, come i grafici Hierarchical Navigable Small World (HNSW) o gli algoritmi Neighbors (KNN). K-Nearest Queste strutture di dati consentono ricerche rapide tra i vicini più vicini, permettendo di trovare rapidamente vettori simili nel database.
Ricerca semantica
La ricerca semantica è una tecnica che migliora la pertinenza dei risultati di ricerca comprendendo l'intento e il contesto della query, anziché limitarsi a corrispondere le parole chiave. In termini tecnici, la ricerca semantica implica il confronto delle rappresentazioni vettoriali della query e dei documenti nel database per trovare le corrispondenze più pertinenti. È possibile utilizzare diverse strategie di recupero per la ricerca semantica, tra cui, a titolo esemplificativo ma non esaustivo:
-
HNSW: una struttura di dati basata su grafici che organizza i vettori in modo da rendere efficiente la ricerca dei vicini più vicini.
-
KNN — Un algoritmo che trova i K vettori più vicini a un vettore di query in base a una metrica di distanza, come la somiglianza del coseno.
-
Somiglianza del coseno: una misura di somiglianza tra due vettori diversi da zero che misura il coseno dell'angolo tra di loro. Viene spesso utilizzato nella ricerca semantica per confrontare la direzione dei vettori in uno spazio ad alta dimensione.
-
Locality-sensitive hashing (LSH): una tecnica che esegue l'hashing di vettori simili sullo stesso bucket o su quelli vicini con un'alta probabilità. Ciò consente ricerche approssimative tra i vicini più vicini, che possono essere più veloci delle ricerche esatte in spazi ad alta dimensione.
