Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurazione della compressione dei dati
È possibile comprimere le tabelle e gli indici nei dati EnterpriseOne aziendali e nelle tabelle di controllo utilizzando la compressione di pagine o righe. La maggior parte dei EnterpriseOne carichi di lavoro AWS disponibili offre le migliori prestazioni con la compressione delle pagine, ma carichi di lavoro estremamente grandi (multipli di terabyte non compressi) potrebbero funzionare meglio con la compressione delle righe. Un confronto dettagliato tra la compressione delle pagine e quella delle righe esula dall'ambito di questa guida. Questa sezione si concentra principalmente sulla compressione delle pagine.
Quando si abilita la compressione per i normali EnterpriseOne carichi di lavoro, si verifica un aumento minimo dell'utilizzo della CPU, ma si ottengono vantaggi significativi per le prestazioni complessive del sistema, misurabili nelle seguenti aree:
-
Dimensioni del database e requisiti di archiviazione inferiori, poiché i dati vengono archiviati su disco in un formato compresso.
-
Tasso di occorrenze nella cache del buffer più elevato, poiché la cache del buffer può contenere molti più dati quando è compressa.
-
IOPS e velocità di trasmissione effettiva di Amazon EBS più bassi, perché ogni operazione di I/O restituisce molti più dati e sono necessarie meno operazioni, in quanto la cache del buffer è più efficace.
-
Backup più rapidi, perché i dati rimangono compressi durante tutto il processo di backup.
È possibile abilitare la compressione singolarmente per tabella o solo per indice. È inoltre possibile scegliere il tipo di compressione, di pagina o di riga, per tabella e indice. Potrebbe essere utile non comprimere le tabelle che vengono aggiornate regolarmente, come le tabelle F0002 (numero successivo) e F0902 (saldi dei conti). In molte circostanze, abilitare la compressione su tutte le tabelle e gli indici rappresenta la soluzione più semplice, poiché offre la maggior parte dei vantaggi senza richiedere un'analisi. object-by-object I passaggi riportati in questa guida comprimono tutte le tabelle e gli indici con la compressione delle pagine.
In alcune circostanze, la compressione potrebbe causare un peggioramento delle prestazioni, specialmente quando i sistemi di terze parti accedono direttamente ai database JD Edwards ed eseguono operazioni di scansione di tabelle e indici. Questo peggioramento è in genere causato da query con prestazioni scadenti. In questi casi, esamina le query lente e usa tecniche di ottimizzazione comuni per migliorarne le prestazioni. Ad esempio, potresti riscrivere le query per utilizzare gli indici esistenti o creare nuovi indici.
L'attivazione della compressione è un processo in più fasi. Molti di questi passaggi richiedono l'accesso esclusivo agli oggetti del database, il che significa che è necessario mettere offline EnterpriseOne gli altri sistemi. Segui queste istruzioni di alto livello per abilitare la compressione delle pagine su tutte le tabelle e gli indici negli schemi DTA e CTL:
Controlla l'utilizzo dello spazio su disco prima della compressione
Per verificare l'attuale utilizzo dello spazio su disco del database, esegui i seguenti script.
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
L'output visualizzato dovrebbe essere simile al seguente:
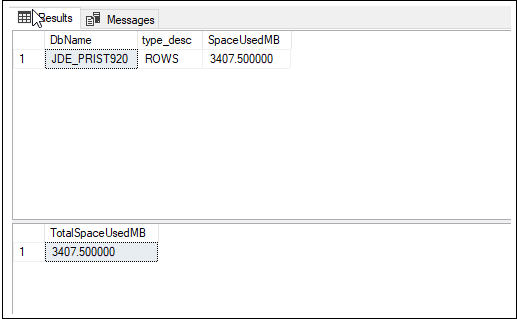
In questo esempio, le righe della tabella occupano 3.407 MB di spazio su disco.
Esecuzione dello script di enumerazione
A causa dell'elevato volume di tabelle e indici presenti nel EnterpriseOne database, è possibile utilizzare uno script per enumerare gli oggetti da comprimere. L'output dello script di enumerazione è lo script di compressione utilizzato nella sezione successiva. Prima di eseguire lo script seguente, aggiorna i nomi dei proprietari dello schema in modo che corrispondano ai proprietari delle tabelle e degli indici che desideri comprimere.
declare @tblname as varchar(100) declare @idxname as varchar(100) declare @schemaname as varchar(100) declare @sqlstatement as varchar(512) declare tblcurs CURSOR for select t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner join sys.partitions p on i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and i.type_desc='CLUSTERED' and p.data_compression_desc <> 'PAGE' open tblcurs FETCH next from tblcurs into @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from tblcurs into @tblname, @schemaname set @sqlstatement = 'alter table ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close tblcurs deallocate tblcurs declare idxcurs CURSOR for select i.name as idxname, t.name as tblname, s.name as schemaname from sys.tables t inner join sys.schemas s on t.schema_id = s.schema_id inner join sys.indexes i on i.object_id = t.object_id inner jOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id where s.name in ('PS920DTA', 'PS920CTL') and p.data_compression_desc <> 'PAGE' and i.type_desc='NONCLUSTERED' and i.name is not null open idxcurs FETCH next from idxcurs into @idxname, @tblname, @schemaname while @@FETCH_STATUS = 0 begin FETCH next from idxcurs into @idxname, @tblname, @schemaname set @sqlstatement = 'alter index ' + @idxname + ' on ' + @schemaname + '.' + @tblname + ' rebuild with (DATA_COMPRESSION = PAGE)' print @sqlstatement end close idxcurs deallocate idxcurs
Esecuzione dello script di compressione
Leggi l'output dello script di enumerazione eseguito nell'ultima sezione. È possibile suddividere questo script di compressione in script più piccoli ed eseguirli singolarmente e in parallelo.
Importante
Assicurati che il EnterpriseOne sistema sia offline quando esegui questo script sul tuo database. EnterpriseOne
Ecco un esempio dello script di compressione.
alter table PS920DTA.F07620 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F760404A rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B93Z1 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F31B65 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F47156 rebuild with (DATA_COMPRESSION = PAGE) alter table PS920DTA.F74F210 rebuild with (DATA_COMPRESSION = PAGE) ... alter index F4611_16 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F4611_17 on PS920DTA.F4611 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_PK on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_3 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F7000110_4 on PS920DTA.F7000110 rebuild with (DATA_COMPRESSION = PAGE) alter index F76A801T_PK on PS920DTA.F76A801T rebuild with (DATA_COMPRESSION = PAGE) ...
Controllo dell'utilizzo dello spazio su disco dopo la compressione
Per verificare l'attuale utilizzo dello spazio su disco del database dopo la compressione, esegui il seguente script.
USE JDE_PRIST920 SELECT DB_NAME() AS DbName, type_desc, CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0 AS SpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'; SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)/128.0) AS TotalSpaceUsedMB FROM sys.database_files WHERE type IN (0,1) AND type_desc = 'ROWS'
L'output visualizzato dovrebbe essere simile al seguente.
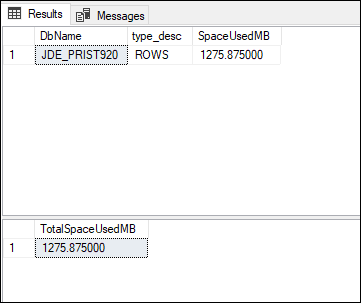
In questo esempio, si può notare che lo spazio utilizzato è sceso da 3.407 MB a 1.275 MB, il che rappresenta un risparmio del 62% grazie alla compressione. Il risparmio per il database varia in base alla distribuzione dei dati tra le tabelle del database.
