Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizza le prestazioni della tua applicazione modernizzata AWS Blu Age
Vishal Jaswani, Manish Roy e Himanshu Sah, Amazon Web Services
Riepilogo
Le applicazioni mainframe modernizzate con AWS Blu Age richiedono test di equivalenza funzionale e prestazionale prima di essere implementate in produzione. Nei test delle prestazioni, le applicazioni modernizzate possono funzionare più lentamente rispetto ai sistemi legacy, in particolare nei lavori in batch complessi. Questa disparità esiste perché le applicazioni mainframe sono monolitiche, mentre le applicazioni moderne utilizzano architetture a più livelli. Questo modello presenta tecniche di ottimizzazione per colmare queste lacune prestazionali per le applicazioni modernizzate utilizzando il refactoring automatizzato con Blu Age. AWS
Il modello utilizza il framework di modernizzazione AWS Blu Age con Java nativo e funzionalità di ottimizzazione del database per identificare e risolvere i problemi di prestazioni. Il modello descrive come utilizzare la profilazione e il monitoraggio per identificare problemi di prestazioni con metriche quali i tempi di esecuzione SQL, l'utilizzo della memoria e i modelli. I/O Spiega quindi come applicare ottimizzazioni mirate, tra cui la ristrutturazione delle query del database, la memorizzazione nella cache e il perfezionamento della logica aziendale.
I miglioramenti nei tempi di elaborazione in batch e nell'utilizzo delle risorse di sistema aiutano a raggiungere i livelli di prestazioni del mainframe nei sistemi modernizzati. Questo approccio mantiene l'equivalenza funzionale durante la transizione verso le moderne architetture basate sul cloud.
Prerequisiti e limitazioni
Prerequisiti
Un'applicazione AWS modernizzata di Blu Age
Privilegi amministrativi per installare client di database e strumenti di profilazione
AWS Certificazione Blu Age Level 3
Comprensione di livello intermedio del framework AWS Blu Age, della struttura del codice generato e della programmazione Java
Limitazioni
Le seguenti funzionalità e funzionalità di ottimizzazione non rientrano nell'ambito di questo modello:
Ottimizzazione della latenza di rete tra i livelli di applicazione
Ottimizzazioni a livello di infrastruttura tramite tipi di istanze Amazon Elastic Compute Cloud (Amazon EC2) e ottimizzazione dello storage
Test di carico utente e test di stress simultanei
Versioni del prodotto
JProfiler versione 13.0 o successiva (consigliamo la versione più recente)
pgAdmin versione 8.14 o successiva
Architecture
Questo modello imposta un ambiente di profilazione per un'applicazione AWS Blu Age utilizzando strumenti come JProfiler pgAdmin. Supporta l'ottimizzazione tramite DAOManager and SQLExecution Builder APIs fornito da Blu Age. AWS
La parte restante di questa sezione fornisce informazioni dettagliate ed esempi per identificare gli hotspot prestazionali e le strategie di ottimizzazione per le applicazioni modernizzate. I passaggi della sezione Epics fanno riferimento a queste informazioni per ulteriori indicazioni.
Identificazione degli hotspot prestazionali nelle applicazioni mainframe modernizzate
Nelle applicazioni mainframe modernizzate, gli hotspot prestazionali sono aree specifiche del codice che causano rallentamenti o inefficienze significativi. Questi hotspot sono spesso causati dalle differenze architettoniche tra le applicazioni mainframe e quelle modernizzate. Per identificare questi ostacoli prestazionali e ottimizzare le prestazioni dell'applicazione modernizzata, è possibile utilizzare tre tecniche: registrazione SQL, piano di query e analisi. EXPLAIN JProfiler
Tecnica di identificazione degli hotspot: registrazione SQL
Le moderne applicazioni Java, comprese quelle che sono state modernizzate utilizzando AWS Blu Age, dispongono di funzionalità integrate per registrare le query SQL. È possibile abilitare logger specifici nei progetti AWS Blu Age per tracciare e analizzare le istruzioni SQL eseguite dall'applicazione. Questa tecnica è particolarmente utile per identificare modelli di accesso al database inefficienti, come query individuali eccessive o chiamate al database mal strutturate, che potrebbero essere ottimizzati mediante il raggruppamento in batch o il perfezionamento delle query.
Per implementare la registrazione SQL nella tua applicazione modernizzata AWS Blu Age, imposta il livello di registro su affinché le istruzioni SQL nel file acquisiscano DEBUG i dettagli sull'esecuzione delle application.properties query:
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
Monitora le query ad alta frequenza e con prestazioni lente utilizzando i dati registrati per identificare gli obiettivi di ottimizzazione. Concentrati sulle query all'interno dei processi batch perché in genere hanno il massimo impatto sulle prestazioni.
Tecnica di identificazione degli hotspot: piano Query EXPLAIN
Questo metodo utilizza le funzionalità di pianificazione delle interrogazioni dei sistemi di gestione di database relazionali. È possibile utilizzare comandi come EXPLAIN PostgreSQL o MySQL EXPLAIN PLAN o Oracle per esaminare in che modo il database intende eseguire una determinata query. L'output di questi comandi fornisce informazioni preziose sulla strategia di esecuzione delle query, incluso se verranno utilizzati gli indici o verranno eseguite scansioni complete della tabella. Queste informazioni sono fondamentali per ottimizzare le prestazioni delle query, specialmente nei casi in cui un'indicizzazione corretta può ridurre significativamente i tempi di esecuzione.
Estrai le query SQL più ripetitive dai log delle applicazioni e analizza il percorso di esecuzione delle query con prestazioni lente utilizzando il comando specifico del tuo database. EXPLAIN Ecco un esempio di database PostgreSQL.
Query:
SELECT * FROM tenk1 WHERE unique1 < 100;
EXPLAINcomando:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
Output:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
È possibile interpretare l'EXPLAINoutput come segue:
Leggete il
EXPLAINpiano dalle operazioni più interne a quelle più esterne (dal basso verso l'alto).Cerca i termini chiave. Ad esempio,
Seq Scanindica la scansione completa della tabella eIndex Scanmostra l'utilizzo dell'indice.Verifica i valori dei costi: il primo numero è il costo iniziale e il secondo numero è il costo totale.
Vedi il
rowsvalore per il numero stimato di righe di output.
In questo esempio, il motore di query utilizza una scansione dell'indice per trovare le righe corrispondenti, quindi recupera solo quelle righe (Bitmap Heap Scan). Ciò è più efficiente rispetto alla scansione dell'intera tabella, nonostante il costo più elevato dell'accesso alle singole righe.
Le operazioni di scansione delle tabelle nell'output di un EXPLAIN piano indicano un indice mancante. L'ottimizzazione richiede la creazione di un indice appropriato.
Tecnica di identificazione degli hotspot: analisi JProfiler
JProfiler è uno strumento completo di profilazione Java che consente di risolvere i problemi di prestazioni identificando le chiamate lente al database e le chiamate che richiedono un uso intensivo della CPU. Questo strumento è particolarmente efficace per identificare le query SQL lente e l'utilizzo inefficiente della memoria.
Esempio di analisi per le interrogazioni:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
La visualizzazione JProfiler Hot Spots fornisce le seguenti informazioni:
Colonna relativa all'ora
Mostra la durata totale dell'esecuzione (ad esempio, 329 secondi)
Visualizza la percentuale del tempo totale di applicazione (ad esempio, 58,7%)
Aiuta a identificare le operazioni che richiedono più tempo
Colonna Tempo medio
Mostra la durata per esecuzione (ad esempio, 2.692 microsecondi)
Indica le prestazioni delle singole operazioni
Aiuta a individuare le singole operazioni lente
Colonna Eventi
Mostra il conteggio delle esecuzioni (ad esempio, 122.387 volte)
Indica la frequenza operativa
Aiuta a identificare i metodi chiamati di frequente
Per i risultati di esempio:
Alta frequenza: 122.387 esecuzioni indicano un potenziale di ottimizzazione
Problema relativo alle prestazioni: il tempo medio di 2.692 microsecondi indica un'inefficienza
Impatto critico: il 58,7% del tempo totale indica un grave ostacolo
JProfiler è in grado di analizzare il comportamento di esecuzione dell'applicazione per individuare punti critici che potrebbero non essere visibili mediante l'analisi statica del codice o la registrazione SQL. Queste metriche aiutano a identificare le operazioni che necessitano di ottimizzazione e a determinare la strategia di ottimizzazione più efficace. Per ulteriori informazioni sulle JProfiler funzionalità, consulta la JProfiler documentazione
Quando si utilizzano queste tre tecniche (registrazione SQL, EXPLAIN piano di query e JProfiler) in combinazione, è possibile ottenere una visione olistica delle caratteristiche prestazionali dell'applicazione. Identificando e risolvendo gli hotspot prestazionali più critici, è possibile colmare il divario prestazionale tra l'applicazione mainframe originale e il sistema modernizzato basato sul cloud.
Dopo aver identificato gli hotspot prestazionali dell'applicazione, è possibile applicare le strategie di ottimizzazione, illustrate nella sezione successiva.
Strategie di ottimizzazione per la modernizzazione del mainframe
Questa sezione descrive le strategie chiave per ottimizzare le applicazioni che sono state modernizzate dai sistemi mainframe. Si concentra su tre strategie: utilizzo delle strategie esistenti APIs, implementazione di un caching efficace e ottimizzazione della logica aziendale.
Strategia di ottimizzazione: utilizzo delle soluzioni esistenti APIs
AWS Blu Age offre diverse potenti APIs interfacce DAO che è possibile utilizzare per ottimizzare le prestazioni. Due interfacce principali, DAOManager e SQLExecution Builder, offrono funzionalità per migliorare le prestazioni delle applicazioni.
DAOManager
DAOManager funge da interfaccia principale per le operazioni di database nelle applicazioni modernizzate. Offre diversi metodi per migliorare le operazioni del database e migliorare le prestazioni delle applicazioni, in particolare per le semplici operazioni di creazione, lettura, aggiornamento ed eliminazione (CRUD) e l'elaborazione in batch.
Usa. SetMaxResults Nell' DAOManager API, è possibile utilizzare il SetMaxResultsmetodo per specificare il numero massimo di record da recuperare in una singola operazione di database. Per impostazione predefinita, DAOManager recupera solo 10 record alla volta, il che può portare a più chiamate al database durante l'elaborazione di set di dati di grandi dimensioni. Utilizzate questa ottimizzazione quando l'applicazione deve elaborare un gran numero di record e attualmente sta effettuando più chiamate al database per recuperarli. Ciò è particolarmente utile negli scenari di elaborazione in batch in cui si esegue l'iterazione su un set di dati di grandi dimensioni. Nell'esempio seguente, il codice a sinistra (prima dell'ottimizzazione) utilizza il valore di recupero dei dati predefinito di 10 record. Il codice a destra (dopo l'ottimizzazione) è impostato setMaxResultsper recuperare 100.000 record alla volta.

Nota
Scegliete con attenzione batch di dimensioni maggiori e controllate le dimensioni degli oggetti, poiché questa ottimizzazione aumenta l'ingombro di memoria.
Sostituisci SetOnGreatorOrEqual con SetOnEqual. Questa ottimizzazione comporta la modifica del metodo utilizzato per impostare la condizione per il recupero dei record. Il SetOnGreatorOrEqualmetodo recupera i record che sono maggiori o uguali a un valore specificato, mentre SetOnEqualrecupera solo i record che corrispondono esattamente al valore specificato.
Utilizza SetOnEqualcome illustrato nel seguente esempio di codice, quando sai di aver bisogno di corrispondenze esatte e stai attualmente utilizzando il SetOnGreatorOrEqualmetodo seguito da readNextEqual (). Questa ottimizzazione riduce il recupero di dati non necessario.

Utilizza operazioni di scrittura e aggiornamento in batch. È possibile utilizzare le operazioni batch per raggruppare più operazioni di scrittura o aggiornamento in un'unica transazione di database. Ciò riduce il numero di chiamate al database e può migliorare significativamente le prestazioni per le operazioni che coinvolgono più record.
Nell'esempio seguente, il codice a sinistra esegue operazioni di scrittura in un ciclo, il che rallenta le prestazioni dell'applicazione. È possibile ottimizzare questo codice utilizzando un'operazione di scrittura in batch: durante ogni iterazione del
WHILEciclo, si aggiungono record a un batch finché la dimensione del batch non raggiunge una dimensione predeterminata di 100. È quindi possibile svuotare il batch quando raggiunge la dimensione predeterminata e quindi scaricare tutti i record rimanenti nel database. Ciò è particolarmente utile negli scenari in cui si elaborano set di dati di grandi dimensioni che richiedono aggiornamenti.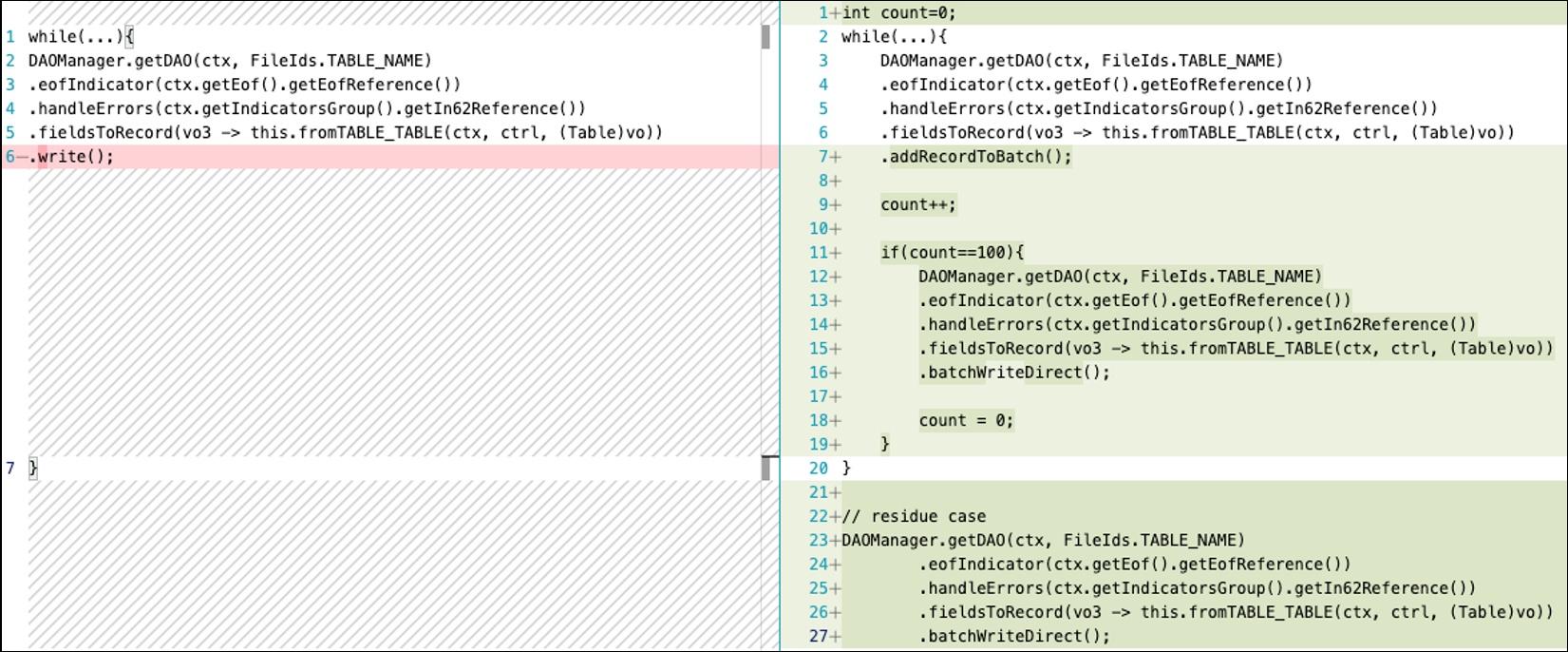
Aggiungere indici. L'aggiunta di indici è un'ottimizzazione a livello di database che può migliorare significativamente le prestazioni delle query. Un indice consente al database di individuare rapidamente le righe con un valore di colonna specifico senza eseguire la scansione dell'intera tabella. Utilizza l'indicizzazione sulle colonne utilizzate di frequente in
WHEREclausole,JOINcondizioni o istruzioni.ORDER BYCiò è particolarmente importante per tabelle di grandi dimensioni o quando il recupero rapido dei dati è fondamentale.
SQLExecutionCostruttore
SQLExecutionBuilder è un'API flessibile che puoi utilizzare per assumere il controllo delle query SQL che verranno eseguite, recuperare solo determinate colonne, utilizzare e utilizzare nomi INSERT di tabelle SELECT dinamici. Nell'esempio seguente, SQLExecutor Builder utilizza una query personalizzata definita dall'utente.

Scelta tra DAOManager e Builder SQLExecution
La scelta tra questi APIs dipende dal caso d'uso specifico:
Usalo DAOManager quando vuoi che AWS Blu Age Runtime generi le query SQL invece di scriverle tu stesso.
Scegli SQLExecution Builder quando devi scrivere query SQL per sfruttare le funzionalità specifiche del database o scrivere query SQL ottimali.
Strategia di ottimizzazione: caching
Nelle applicazioni modernizzate, l'implementazione di strategie di caching efficaci può ridurre significativamente le chiamate al database e migliorare i tempi di risposta. Questo aiuta a colmare il divario di prestazioni tra ambienti mainframe e cloud.
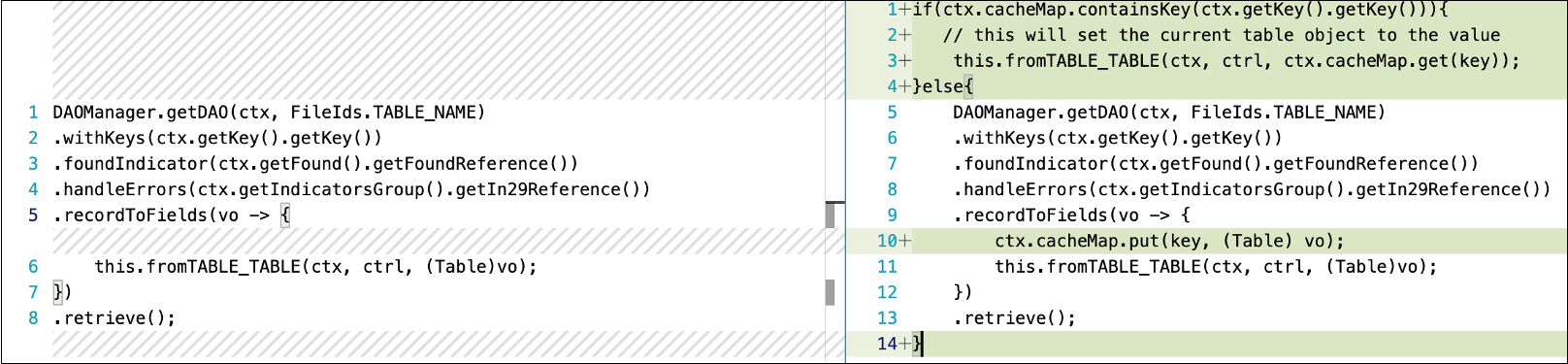
Nelle applicazioni AWS Blu Age, le semplici implementazioni di caching utilizzano strutture di dati interne come mappe hash o elenchi di array, quindi non è necessario configurare una soluzione di caching esterna che richieda una ristrutturazione dei costi e del codice. Questo approccio è particolarmente efficace per i dati a cui si accede frequentemente ma che vengono modificati raramente. Quando implementi la memorizzazione nella cache, considera i vincoli di memoria e i modelli di aggiornamento per garantire che i dati memorizzati nella cache rimangano coerenti e offrano vantaggi effettivi in termini di prestazioni.
La chiave per una corretta memorizzazione nella cache è identificare i dati giusti da memorizzare nella cache. Nell'esempio seguente, il codice a sinistra legge sempre i dati dalla tabella, mentre il codice a destra legge i dati dalla tabella quando la mappa hash locale non ha un valore per una determinata chiave. cacheMapè un oggetto di mappa hash creato nel contesto del programma e cancellato nel metodo di pulizia del contesto del programma.
Memorizzazione nella cache con: DAOManager
Memorizzazione nella cache con Builder: SQLExecution

Strategia di ottimizzazione: ottimizzazione della logica aziendale
L'ottimizzazione della logica aziendale si concentra sulla ristrutturazione del codice generato automaticamente da AWS Blu Age per allinearlo meglio alle funzionalità dell'architettura moderna. Ciò diventa necessario quando il codice generato mantiene la stessa struttura logica del codice mainframe legacy, il che potrebbe non essere ottimale per i sistemi moderni. L'obiettivo è migliorare le prestazioni mantenendo l'equivalenza funzionale con l'applicazione originale.
Questo approccio di ottimizzazione va oltre le semplici modifiche alle API e le strategie di memorizzazione nella cache. Implica modifiche al modo in cui l'applicazione elabora i dati e interagisce con il database. Le ottimizzazioni più comuni includono l'eliminazione di operazioni di lettura non necessarie per semplici aggiornamenti, la rimozione delle chiamate ridondanti al database e la ristrutturazione dei modelli di accesso ai dati per allinearli meglio alla moderna architettura applicativa. Di seguito si riportano alcuni esempi:
Aggiornamento dei dati direttamente nel database.Ristruttura la logica di business utilizzando gli aggiornamenti SQL diretti anziché più DAOManager operazioni con loop. Ad esempio, il codice seguente (lato sinistro) effettua più chiamate al database e utilizza una quantità eccessiva di memoria. In particolare, utilizza più operazioni di lettura e scrittura del database all'interno dei loop, aggiornamenti individuali anziché l'elaborazione in batch e la creazione di oggetti non necessari per ogni iterazione.
Il seguente codice ottimizzato (lato destro) utilizza una singola operazione di aggiornamento Direct SQL. In particolare, utilizza una singola chiamata al database anziché più chiamate e non richiede cicli perché tutti gli aggiornamenti vengono gestiti in un'unica istruzione. Questa ottimizzazione offre prestazioni e utilizzo delle risorse migliori e riduce la complessità. Previene l'iniezione di SQL, offre una migliore memorizzazione nella cache del piano di query e aiuta a migliorare la sicurezza.

Nota
Utilizza sempre query parametrizzate per impedire l'iniezione di SQL e garantire una corretta gestione delle transazioni.
Riduzione delle chiamate ridondanti al database. Le chiamate ridondanti al database possono influire in modo significativo sulle prestazioni delle applicazioni, in particolare quando avvengono all'interno di loop. Una tecnica di ottimizzazione semplice ma efficace consiste nell'evitare di ripetere più volte la stessa query sul database. Il seguente confronto di codice dimostra come lo spostamento della chiamata al
retrieve()database all'esterno del ciclo impedisca l'esecuzione ridondante di query identiche, migliorando l'efficienza.
Riduzione delle chiamate al database utilizzando la clausola SQL.
JOINImplementa SQLExecution Builder per ridurre al minimo le chiamate al database. SQLExecutionBuilder offre un maggiore controllo sulla generazione di SQL ed è particolarmente utile per query complesse che DAOManager non possono essere gestite in modo efficiente. Ad esempio, il codice seguente utilizza più DAOManager chiamate:List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }Il codice ottimizzato utilizza una singola chiamata al database in SQLExecution Builder:
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
Utilizzo congiunto di strategie di ottimizzazione
Queste tre strategie funzionano in modo sinergico: APIs forniscono gli strumenti per un accesso efficiente ai dati, la memorizzazione nella cache riduce la necessità di recuperi ripetuti dei dati e l'ottimizzazione della logica aziendale garantisce che questi APIs vengano utilizzati nel modo più efficace possibile. Il monitoraggio e la regolazione regolari di queste ottimizzazioni garantiscono continui miglioramenti delle prestazioni, pur mantenendo l'affidabilità e la funzionalità dell'applicazione modernizzata. La chiave del successo sta nel capire quando e come applicare ciascuna strategia in base alle caratteristiche e agli obiettivi prestazionali dell'applicazione.
Tools (Strumenti)
JProfiler
è uno strumento di profilazione Java progettato per sviluppatori e ingegneri delle prestazioni. Analizza le applicazioni Java e aiuta a identificare rallentamenti nelle prestazioni, perdite di memoria e problemi di threading. JProfiler offre la profilazione di CPU, memoria e thread, nonché il monitoraggio di database e macchine virtuali Java (JVM) per fornire informazioni sul comportamento delle applicazioni. Nota
In alternativa JProfiler, è possibile utilizzare Java VisualVM.
Si tratta di uno strumento gratuito e open source di profilazione e monitoraggio delle prestazioni per applicazioni Java che offre il monitoraggio in tempo reale dell'utilizzo della CPU, del consumo di memoria, della gestione dei thread e delle statistiche sulla raccolta dei rifiuti. Poiché Java VisualVM è uno strumento JDK integrato, è più conveniente rispetto alle esigenze di profilazione di base. JProfiler pgAdmin
è uno strumento di amministrazione e sviluppo open source per PostgreSQL. Fornisce un'interfaccia grafica che consente di creare, gestire e utilizzare oggetti di database. È possibile utilizzare pgAdmin per eseguire un'ampia gamma di attività, dalla scrittura di semplici query SQL allo sviluppo di database complessi. Le sue funzionalità includono un editor SQL che evidenzia la sintassi, un editor di codice lato server, un agente di pianificazione per attività SQL, shell e batch e il supporto per tutte le funzionalità di PostgreSQL sia per utenti PostgreSQL principianti che esperti.
Best practice
Identificazione degli hotspot prestazionali:
Documenta le metriche prestazionali di base prima di iniziare le ottimizzazioni.
Stabilisci obiettivi chiari di miglioramento delle prestazioni in base ai requisiti aziendali.
Durante il benchmarking, disabilita la registrazione dettagliata, poiché può influire sulle prestazioni.
Configura una suite di test delle prestazioni ed eseguila periodicamente.
Usa l'ultima versione di pgAdmin. (Le versioni precedenti non supportano il piano di
EXPLAINinterrogazione).Per il benchmarking, scollegatelo JProfiler dopo aver completato le ottimizzazioni perché aumenta la latenza.
Per il benchmarking, assicuratevi di eseguire il server in modalità start anziché in modalità debug, perché la modalità di debug aumenta la latenza.
Strategie di ottimizzazione:
Configura SetMaxResultsi valori nel
application.yamlfile per specificare i batch delle dimensioni corrette in base alle specifiche del sistema.Configura SetMaxResultsi valori in base al volume di dati e ai vincoli di memoria.
Passa SetOnGreatorOrEquala SetOnEqualsolo in caso di chiamate successive.
.readNextEqual()Nelle operazioni di scrittura o aggiornamento in batch, gestite l'ultimo batch separatamente, poiché potrebbe essere inferiore alla dimensione del batch configurato e potrebbe non essere rilevato dall'operazione di scrittura o aggiornamento.
Memorizzazione nella cache:
I campi introdotti per la memorizzazione nella cache
processImpl, che mutano ad ogni esecuzione, devono sempre essere definiti nel contesto di tale operazione.processImplI campi devono essere cancellati anche utilizzando ildoReset()metodo or.cleanUp()Quando implementate la memorizzazione nella cache in memoria, dimensionate correttamente la cache. Le cache molto grandi archiviate in memoria possono occupare tutte le risorse, il che potrebbe influire sulle prestazioni complessive dell'applicazione.
SQLExecutionCostruttore:
Per le query che intendi utilizzare in SQLExecution Builder, utilizza nomi chiave come.
PROGRAMNAME_STATEMENTNUMBERQuando usi SQLExecution Builder, controlla sempre il campo.
SqlcodQuesto campo contiene un valore che specifica se la query è stata eseguita correttamente o se sono stati rilevati errori.Utilizza query con parametri per impedire l'iniezione di SQL.
Ottimizzazione della logica aziendale:
Mantieni l'equivalenza funzionale durante la ristrutturazione del codice ed esegui test di regressione e confronto tra database per il sottoinsieme di programmi pertinente.
Conserva istantanee di profilazione per il confronto.
Epiche
| Operazione | Description | Competenze richieste |
|---|---|---|
Installa e configura JProfiler. |
| Sviluppatore di app |
Installa e configura pgAdmin. | In questo passaggio, si installa e si configura un client DB per interrogare il database. Questo modello utilizza un database PostgreSQL e pgAdmin come client di database. Se utilizzi un altro motore di database, segui la documentazione per il client DB corrispondente.
| Sviluppatore di app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Abilita la registrazione delle query SQL nell'applicazione AWS Blu Age. | Sviluppatore di app | |
Genera e analizza i | Per i dettagli, consulta la sezione Architettura. | Sviluppatore di app |
Crea un' JProfiler istantanea per analizzare un test case con prestazioni lente. |
| Sviluppatore di app |
Analizza l' JProfiler istantanea per identificare i punti deboli in termini di prestazioni. | Segui questi passaggi per analizzare l'istantanea. JProfiler
Per ulteriori informazioni sull'utilizzo JProfiler, consulta la sezione Architettura e la JProfiler documentazione | Sviluppatore di app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Stabilisci una linea di base delle prestazioni prima di implementare le ottimizzazioni. |
| Sviluppatore di app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Ottimizza le chiamate di lettura. | Ottimizza il recupero dei dati utilizzando il DAOManager SetMaxResultsmetodo. Per ulteriori informazioni su questo approccio, consulta la sezione Architettura. | Sviluppatore di app, DAOManager |
Rifattorizza la logica aziendale per evitare chiamate multiple al database. | Riduci le chiamate al database utilizzando una | Sviluppatore di app, SQLExecution Builder |
Rifattorizza il codice per utilizzare la memorizzazione nella cache per ridurre la latenza delle chiamate di lettura. | Per informazioni su questa tecnica, consulta la sezione Caching nella sezione Architettura. | Sviluppatore di app |
Riscrivi codice inefficiente che utilizza più DAOManager operazioni per semplici operazioni di aggiornamento. | Per ulteriori informazioni sull'aggiornamento dei dati direttamente nel database, consulta Ottimizzazione della logica aziendale nella sezione Architettura. | Sviluppatore di app |
| Operazione | Description | Competenze richieste |
|---|---|---|
Convalida ogni modifica di ottimizzazione in modo iterativo mantenendo l'equivalenza funzionale. |
NotaL'utilizzo di metriche di base come riferimento garantisce una misurazione accurata dell'impatto di ogni ottimizzazione, mantenendo al contempo l'affidabilità del sistema. | Sviluppatore di app |
risoluzione dei problemi
| Problema | Soluzione |
|---|---|
Quando si esegue l'applicazione moderna, viene visualizzata un'eccezione con l'errore. | Per risolvere il problema:
|
Hai aggiunto degli indici, ma non vedi alcun miglioramento delle prestazioni. | Segui questi passaggi per assicurarti che il motore di query utilizzi l'indice:
|
Si verifica un' out-of-memoryeccezione. | Verificate che il codice rilasci la memoria contenuta nella struttura dei dati. |
Le operazioni di scrittura in batch provocano la mancanza di record nella tabella | Esamina il codice per assicurarti che venga eseguita un'ulteriore operazione di scrittura quando il conteggio dei batch è diverso da zero. |
La registrazione SQL non viene visualizzata nei registri delle applicazioni. |
|
Risorse correlate
