Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Interpretabilità locale
I metodi più diffusi per l'interpretabilità locale di modelli complessi si basano su Shapley Additive Explanations (SHAP) [8] o gradienti integrati [11]. Ogni metodo presenta una serie di varianti specifiche per un tipo di modello.
Per i modelli con insieme di alberi, utilizzate tree SHAP
Nel caso dei modelli basati su alberi, la programmazione dinamica consente un calcolo rapido ed esatto dei valori di Shapley
Per le reti neurali e i modelli differenziabili, usa gradienti e conduttanza integrati
I gradienti integrati forniscono un modo semplice per calcolare le attribuzioni di funzionalità nelle reti neurali. La conduttanza si basa su gradienti integrati per aiutarvi a interpretare le attribuzioni provenienti da porzioni di reti neurali come strati e singoli neuroni. (Vedi [3,11], l'implementazione è disponibile su https://captum.ai/.)
Per tutti gli altri casi, usa Kernel SHAP
È possibile utilizzare Kernel SHAP per calcolare le attribuzioni di funzionalità per qualsiasi modello, ma è un'approssimazione al calcolo dei valori completi di Shapley e rimane costoso dal punto di vista computazionale (vedi [8]). Le risorse di calcolo richieste per Kernel SHAP crescono rapidamente con il numero di funzionalità. Ciò richiede metodi di approssimazione in grado di ridurre la fedeltà, la ripetibilità e la robustezza delle spiegazioni. Amazon SageMaker AI Clarify offre metodi pratici che distribuiscono contenitori predefiniti per il calcolo dei valori Kernal SHAP in istanze separate. (Per un esempio, consulta il GitHub repository Fairness
Per i modelli ad albero singolo, le variabili di divisione e i valori delle foglie forniscono un modello immediatamente spiegabile e i metodi discussi in precedenza non forniscono informazioni aggiuntive. Analogamente, per i modelli lineari, i coefficienti forniscono una chiara spiegazione del comportamento del modello. (I metodi SHAP e quelli a gradiente integrato restituiscono entrambi contributi determinati dai coefficienti.)
Sia SHAP che i metodi integrati basati sul gradiente presentano punti deboli. SHAP richiede che le attribuzioni siano derivate da una media ponderata di tutte le combinazioni di funzionalità. Le attribuzioni ottenute in questo modo possono essere fuorvianti quando si stima l'importanza delle caratteristiche se esiste una forte interazione tra le caratteristiche. I metodi basati su gradienti integrati possono essere difficili da interpretare a causa del gran numero di dimensioni presenti nelle reti neurali di grandi dimensioni e questi metodi sono sensibili alla scelta di un punto base. Più in generale, i modelli possono utilizzare le funzionalità in modi inaspettati per raggiungere un certo livello di prestazioni e questi possono variare a seconda del modello: l'importanza delle funzionalità dipende sempre dal modello.
Visualizzazioni consigliate
La tabella seguente presenta diversi modi consigliati per visualizzare le interpretazioni locali discusse nelle sezioni precedenti. Per i dati tabulari consigliamo un semplice grafico a barre che mostri le attribuzioni, in modo che possano essere facilmente confrontate e utilizzate per dedurre in che modo il modello effettua le previsioni.
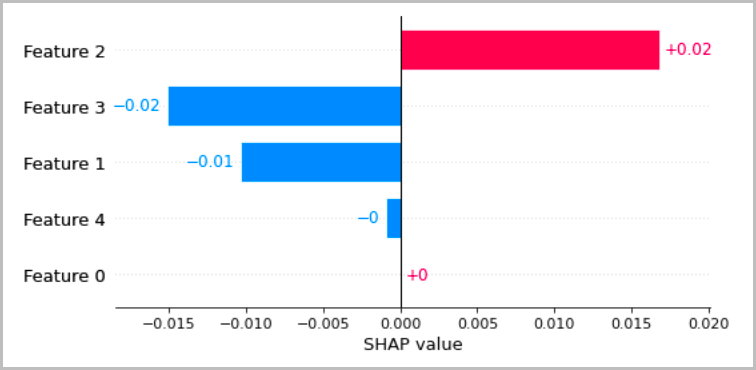
Per i dati di testo, l'incorporamento di token porta a un gran numero di input scalari. I metodi consigliati nelle sezioni precedenti producono un'attribuzione per ogni dimensione dell'incorporamento e per ogni output. Per distillare queste informazioni in una visualizzazione, è possibile sommare le attribuzioni per un determinato token. L'esempio seguente mostra la somma delle attribuzioni per il modello di risposta alle domande basato su BERT che è stato addestrato sul set di dati SQUAD. In questo caso, l'etichetta prevista e vera è il token della parola «francia».

Altrimenti, la norma vettoriale delle attribuzioni dei token può essere assegnata come valore di attribuzione totale, come mostrato nell'esempio seguente.

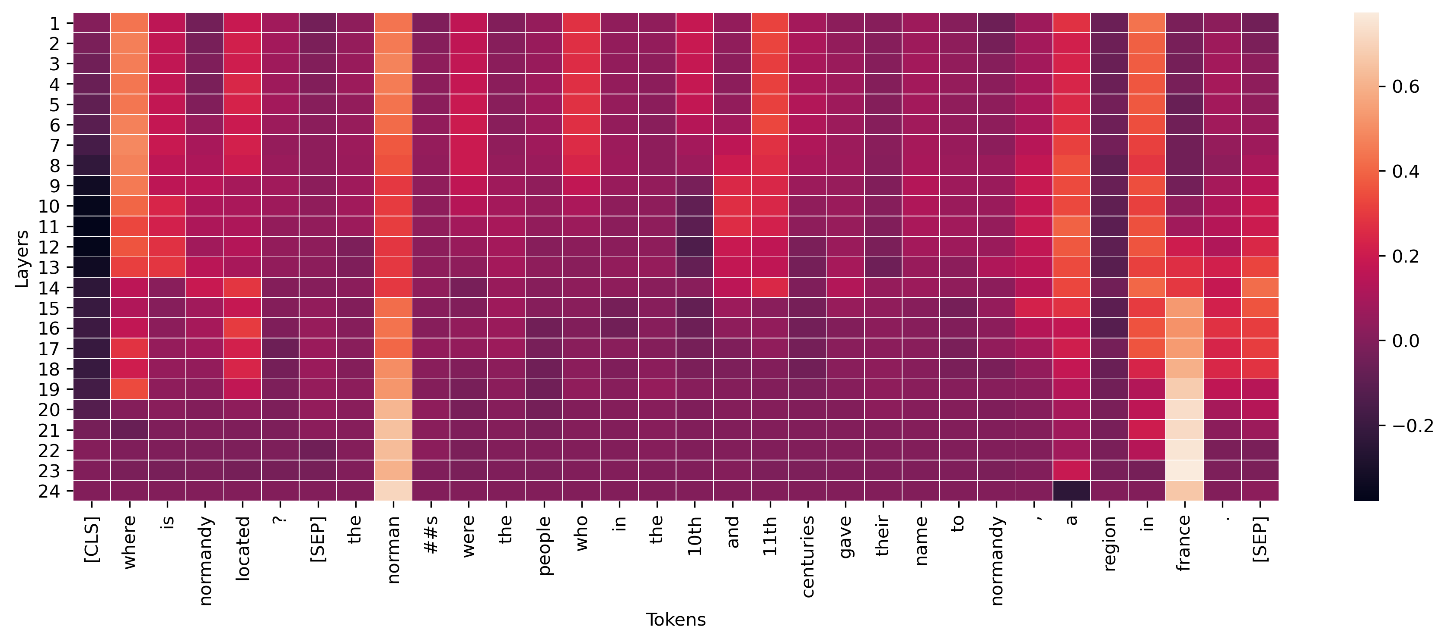
Per i livelli intermedi nei modelli di deep learning, aggregazioni simili possono essere applicate alle conduttanze per la visualizzazione, come mostrato nell'esempio seguente. Questa norma vettoriale della conduttanza dei token per gli strati del trasformatore mostra l'eventuale attivazione per la previsione del token finale («france»).
I vettori di attivazione concettuale forniscono un metodo per studiare le reti neurali profonde in modo più dettagliato [6]. Questo metodo estrae le caratteristiche da un livello di una rete già addestrata e addestra un classificatore lineare su tali caratteristiche per fare inferenze sulle informazioni presenti nel livello. Ad esempio, potreste voler determinare quale livello di un modello linguistico basato su Bert contiene la maggior parte delle informazioni sulle parti del discorso. In questo caso, potreste addestrare un part-of-speech modello lineare sull'output di ogni livello e stimare approssimativamente che il classificatore con le migliori prestazioni sia associato al livello che contiene il maggior numero di informazioni. part-of-speech Sebbene non lo raccomandiamo come metodo principale per interpretare le reti neurali, può essere un'opzione per uno studio più dettagliato e un aiuto nella progettazione dell'architettura di rete.
