Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica
Questo è il processo concettuale di migrazione dei database Oracle all' AWS utilizzo dei backup incrementali Oracle XTTS e RMAN con Snowball Edge e per Lustre. Direct Connect FSx
Il diagramma seguente mostra le fasi di migrazione di alto livello per un database Oracle tra diversi formati endian.
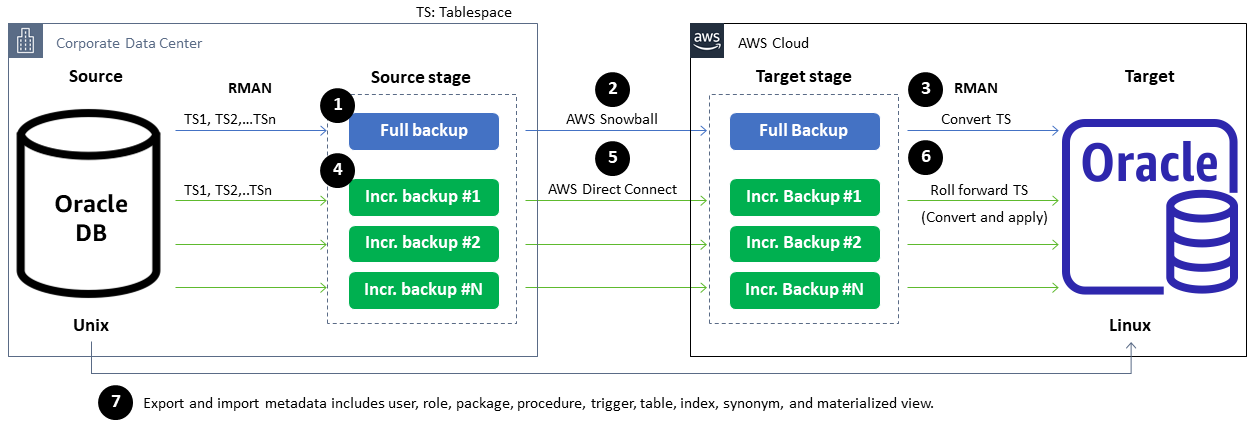
-
Effettua un backup completo di tutte le tablespace.
-
Usa Snowball Edge per spostare il backup dallo stadio di origine a quello di destinazione.
-
Convertite le tablespace nel database di destinazione.
-
Effettua backup incrementali.
-
Utilizzare Direct Connect per trasferire backup incrementali dalla fase di origine alla fase di destinazione.
-
Esegui il rollforward dei backup incrementali, convertendoli e applicandoli al database di destinazione.
-
Esporta e importa i metadati per tutte le tablespace trasportate.
Prima del cutover, potete ridurre al minimo i tempi di inattività effettuando le seguenti operazioni:
-
Esportazione e importazione dei metadati di oggetti non basati su segmenti, tra cui,,, e
USERPACKAGE_SPECPACKAGE_BODYPROCEDUREFUNCTION -
Aumento del parallelismo per il backup completo e il backup incrementale
-
Conversione di file di dati
-
Backup avanzati durante la migrazione
Il documento Oracle Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup (2471245.1
Questa guida fornisce un modo per parallelizzare le fasi, riducendo al minimo i tempi di inattività della migrazione in ambienti di sistema mission-critical con dimensioni di dati estremamente grandi.
Dopo una fase di configurazione iniziale, i passaggi di alto livello per l'utilizzo di Oracle XTTS con i backup incrementali RMAN includono le seguenti fasi.
Fase 1: fase di preparazione
La fase di preparazione prevede le seguenti fasi:
-
Un backup completo iniziale (level=0) dei tablespace viene trasferito dal database di origine allo stadio di origine, che è lo storage NAS.
-
Le copie di backup vengono trasferite utilizzando Snowball Edge allo stadio di destinazione, che è FSx per Lustre integrato con Amazon Simple Storage Service (Amazon S3) Simple Storage Service (Amazon S3).
-
I tablespace di Backup vengono ripristinati e convertiti nel database di destinazione con il formato little-endian.
I passaggi di questa fase vengono eseguiti una sola volta durante la migrazione. I dati trasportati sono completamente accessibili nel database di origine durante questa fase.
Fase 2: fase di roll-forward
La fase di roll-forward consiste nelle seguenti fasi:
-
Viene eseguito un backup incrementale dal database di origine allo stadio di origine.
-
Le copie di backup incrementali vengono trasferite nuovamente nella fase di destinazione. Direct Connect
-
Le copie di backup incrementali vengono convertite nel database di destinazione con il formato little-endian. Le copie vengono quindi applicate al database di destinazione iniziale, operazione denominata fase di roll-forward.
È possibile eseguire questa fase più volte. Ogni backup incrementale successivo dovrebbe richiedere meno tempo e aggiornerà le copie del file di dati di destinazione con il database di origine. Come nella fase 1, i dati di origine trasportati sono completamente accessibili durante questa fase.
Fase 3 — Fase di trasporto
La terza fase prevede le seguenti fasi:
-
Le tablespace trasportate vengono modificate in modalità di sola lettura.
-
Un backup incrementale finale viene eseguito dal database di origine.
-
I metadati vengono esportati.
-
I backup vengono trasferiti e applicati alla destinazione.
-
I metadati degli oggetti vengono importati.
A questo punto, il numero di modifica del sistema (SCN) del database di destinazione è coerente con quello del database di origine.
I metadati delle tablespace trasportabili vengono esportati dal database di origine e importati nel database di destinazione. I metadati includono informazioni sull'utente, il ruolo, il pacchetto, la procedura, la funzione, la tabella e l'indice.
Infine, i tablespace vengono resi in lettura/scrittura per un accesso completo al database di destinazione dall'applicazione.
Questa fase è seguita da una fase di convalida.
