Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Disaccoppiamento delle relazioni tra tabelle durante la scomposizione del database
Questa sezione fornisce indicazioni sulla suddivisione delle relazioni tra tabelle complesse e sulle operazioni JOIN durante la scomposizione monolitica del database. Un table join combina le righe di due o più tabelle in base a una colonna correlata tra di esse. L'obiettivo della separazione di queste relazioni è ridurre l'elevato accoppiamento tra le tabelle mantenendo al contempo l'integrità dei dati tra i microservizi.
Questa sezione contiene i seguenti argomenti:
Strategia di denormalizzazione
La denormalizzazione è una strategia di progettazione di database che prevede l'introduzione intenzionale della ridondanza combinando o duplicando i dati tra le tabelle. Quando si suddivide un database di grandi dimensioni in database di piccole dimensioni, potrebbe essere opportuno duplicare alcuni dati tra i servizi. Ad esempio, l'archiviazione dei dati di base dei clienti, come nome e indirizzi e-mail, sia in un servizio di marketing che in un servizio ordini elimina la necessità di ricerche costanti tra i diversi servizi. Il servizio di marketing potrebbe aver bisogno delle preferenze dei clienti e delle informazioni di contatto per il targeting delle campagne, mentre il servizio ordini richiede gli stessi dati per l'elaborazione degli ordini e le notifiche. Sebbene ciò crei una certa ridondanza dei dati, può migliorare significativamente le prestazioni e l'indipendenza del servizio, consentendo al team di marketing di gestire le proprie campagne senza dipendere dalle ricerche in tempo reale del servizio clienti.
Quando implementate la denormalizzazione, concentratevi sui campi ad accesso frequente che identificate attraverso un'attenta analisi dei modelli di accesso ai dati. È possibile utilizzare strumenti, ad esempio Oracle AWR report opg_stat_statements, per capire quali dati vengono comunemente recuperati insieme. Gli esperti del settore possono anche fornire informazioni preziose sui raggruppamenti di dati naturali. Ricorda che la denormalizzazione non è un all-or-nothing approccio, ma solo dati duplicati che migliorano in modo dimostrabile le prestazioni del sistema o riducono le dipendenze complesse.
Reference-by-key strategia
Una reference-by-key strategia è un modello di progettazione di database in cui le relazioni tra le entità vengono mantenute tramite chiavi univoche anziché archiviare i dati correlati effettivi. Invece delle tradizionali relazioni con chiavi esterne, i microservizi moderni spesso archiviano solo gli identificatori univoci dei dati correlati. Ad esempio, anziché conservare tutti i dettagli del cliente nella tabella degli ordini, il servizio ordini memorizza solo l'ID cliente e recupera informazioni aggiuntive sul cliente tramite una chiamata API quando necessario. Questo approccio mantiene l'indipendenza del servizio garantendo al contempo l'accesso ai dati correlati.
Modello CQRS
Il pattern Command Query Responsibility Segregation (CQRS) separa le operazioni di lettura e scrittura di un archivio dati. Questo modello è particolarmente utile in sistemi complessi con requisiti di prestazioni elevate, in particolare quelli con carichi asimmetrici. read/write Se l'applicazione necessita spesso di dati combinati da più fonti, è possibile creare un modello CQRS dedicato anziché join complessi. Ad esempio, anziché unire Inventory tabelle ad ogni richiesta ProductPricing, è consigliabile mantenere una Product Catalog tabella consolidata che contenga i dati necessari. I vantaggi di questo approccio possono superare i costi della tabella aggiuntiva.
Prendiamo in considerazione uno scenario in cui Product Price i Inventory servizi necessitano spesso di informazioni sui prodotti. Invece di configurare questi servizi per accedere direttamente alle tabelle condivise, crea un Product Catalog servizio dedicato. Questo servizio mantiene il proprio database che contiene le informazioni consolidate sul prodotto. Funziona come un'unica fonte di verità per le domande relative ai prodotti. Quando i dettagli del prodotto, i prezzi o i livelli di inventario cambiano, i rispettivi servizi possono pubblicare eventi per aggiornare il servizio. Product Catalog Ciò garantisce la coerenza dei dati mantenendo al contempo l'indipendenza del servizio. L'immagine seguente mostra questa configurazione, in cui Amazon EventBridge
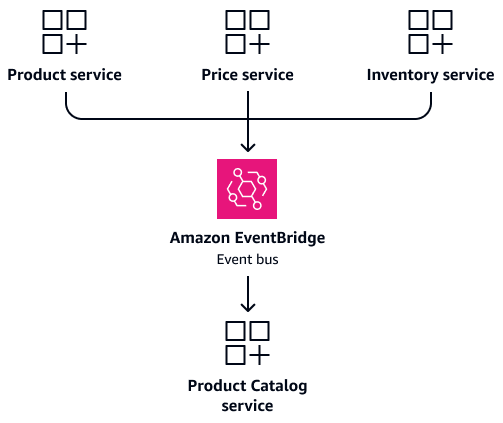
Come discusso nella sezione successivaSincronizzazione dei dati basata sugli eventi, mantenete aggiornato il modello CQRS tramite eventi. Quando i dettagli del prodotto, i prezzi o i livelli di inventario cambiano, i rispettivi servizi pubblicano eventi. Il Product Catalog servizio sottoscrive questi eventi e aggiorna la sua visualizzazione consolidata. Ciò fornisce letture veloci senza unioni complesse e mantiene l'indipendenza del servizio.
Sincronizzazione dei dati basata sugli eventi
La sincronizzazione dei dati basata sugli eventi è un modello in cui le modifiche ai dati vengono acquisite e propagate come eventi, il che consente a diversi sistemi o componenti di mantenere gli stati dei dati sincronizzati. Quando i dati cambiano, invece di aggiornare immediatamente tutti i database correlati, pubblica un evento per notificare i servizi sottoscritti. Ad esempio, quando un cliente modifica l'indirizzo di spedizione nel Customer servizio, un CustomerUpdated evento avvia gli aggiornamenti del Order servizio e del servizio in base alla Delivery pianificazione di ciascun servizio. Questo approccio sostituisce le giunzioni rigide tra tabelle con aggiornamenti flessibili e scalabili basati sugli eventi. Alcuni servizi potrebbero contenere per un breve periodo dati obsoleti, ma il compromesso è una migliore scalabilità del sistema e l'indipendenza del servizio.
Implementazione di alternative ai join tra tabelle
Inizia la scomposizione del database con le operazioni di lettura, poiché in genere sono più semplici da migrare e convalidare. Dopo che i percorsi di lettura sono stabili, affronta le operazioni di scrittura più complesse. Per requisiti critici e ad alte prestazioni, prendi in considerazione l'implementazione del modello CQRS. Utilizzate un database separato e ottimizzato per le letture e mantenetene un altro per le scritture.
Crea sistemi resilienti aggiungendo la logica di ripetizione per le chiamate tra servizi e implementando livelli di caching appropriati. Monitora attentamente le interazioni con i servizi e imposta avvisi per problemi di coerenza dei dati. L'obiettivo finale non è la perfetta coerenza ovunque, ma la creazione di servizi indipendenti che funzionino bene mantenendo al contempo una precisione dei dati accettabile per le esigenze aziendali.
La natura disaccoppiata dei microservizi introduce le seguenti nuove complessità nella gestione dei dati:
-
I dati vengono distribuiti. I dati ora risiedono in database separati, gestiti da servizi indipendenti.
-
La sincronizzazione in tempo reale tra i servizi è spesso poco pratica e richiede un eventuale modello di coerenza.
-
Le operazioni che in precedenza si svolgevano all'interno di una singola transazione di database ora si estendono su più servizi.
Per risolvere queste sfide, procedi come segue:
-
Implementa un'architettura basata sugli eventi: utilizza le code di messaggi e la pubblicazione degli eventi per propagare le modifiche ai dati tra i servizi. Per ulteriori informazioni, consulta Creazione di architetture basate sugli eventi su Serverless
Land. -
Adotta lo schema di orchestrazione della saga: questo modello ti aiuta a gestire le transazioni distribuite e a mantenere l'integrità dei dati tra i servizi. Per ulteriori informazioni, consulta Creazione di un'applicazione distribuita senza server utilizzando un modello di orchestrazione saga
sui blog. AWS -
Progettazione in caso di guasto: incorpora meccanismi di ripetizione dei tentativi, interruttori automatici e transazioni di compensazione per gestire problemi di rete o guasti del servizio.
-
Usa la marcatura delle versioni: monitora le versioni dei dati per gestire i conflitti e assicurati che vengano applicati gli aggiornamenti più recenti.
-
Riconciliazione regolare: implementa processi periodici di sincronizzazione dei dati per catturare e correggere eventuali incongruenze.
Esempio basato su scenari
L'esempio di schema seguente ha due tabelle, una Customer tabella e una tabella: Order
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
Di seguito è riportato un esempio di come è possibile utilizzare un approccio denormalizzato:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
La nuova Order tabella contiene il nome e gli indirizzi e-mail dei clienti denormalizzati. customer_idViene fatto riferimento a e non esiste alcun vincolo di chiave esterna nella tabella. Customer Di seguito sono riportati i vantaggi di questo approccio denormalizzato:
-
Il
Orderservizio può visualizzare la cronologia degli ordini con i dettagli del cliente e non richiede chiamate API al microservizio.Customer -
Se il
Customerservizio è inattivo, ilOrderservizio rimane perfettamente funzionante. -
Le richieste per l'elaborazione degli ordini e la creazione di report vengono eseguite più rapidamente.
Il diagramma seguente mostra un'applicazione monolitica che recupera i dati degli ordini utilizzando getOrder(customer_id) getOrder(order_id)getCustomerOders(customer_id), e chiamate createOrder(Order
order) API al microservizio. Order
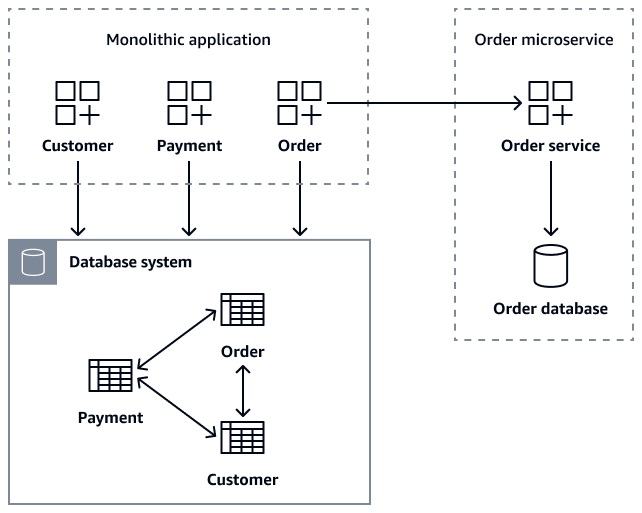
Durante la migrazione dei microservizi, è possibile mantenere la Order tabella nel database monolitico come misura di sicurezza transitoria, garantendo che l'applicazione precedente rimanga funzionale. Tuttavia, è fondamentale che tutte le nuove operazioni relative agli ordini vengano instradate tramite l'API dei Order microservizi, che mantiene il proprio database e contemporaneamente scrive nel database legacy come backup. Questo pattern a doppia scrittura fornisce una rete di sicurezza. Consente una migrazione graduale mantenendo la stabilità del sistema. Dopo che tutti i clienti hanno effettuato con successo la migrazione al nuovo microservizio, è possibile rendere obsoleta la Order tabella esistente nel database monolitico. Dopo aver scomposto l'applicazione monolitica e il relativo database in microservizi separatiCustomer, mantenere la coerenza dei dati diventa la sfida principale. Order
