Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Analisi della coesione e dell'accoppiamento per la scomposizione del database
Questa sezione consente di analizzare i modelli di accoppiamento e coesione nel database monolitico per guidarne la scomposizione. Comprendere come i componenti del database interagiscono e dipendono gli uni dagli altri è fondamentale per identificare i punti di interruzione naturali, valutare la complessità e pianificare un approccio di migrazione graduale. Questa analisi rivela le dipendenze nascoste, evidenzia le aree adatte alla separazione immediata e aiuta a dare priorità agli sforzi di decomposizione riducendo al minimo i rischi di trasformazione. Esaminando sia l'accoppiamento che la coesione, è possibile prendere decisioni informate sulla sequenza di separazione dei componenti al fine di mantenere la stabilità del sistema durante l'intero processo di trasformazione.
Questa sezione contiene i seguenti argomenti:
Informazioni sulla coesione e l'accoppiamento
L'accoppiamento misura il grado di interdipendenza tra i componenti del database. In un sistema ben progettato, si desidera ottenere un accoppiamento libero, in cui le modifiche a un componente abbiano un impatto minimo sugli altri. La coesione misura l'efficacia con cui gli elementi all'interno di un componente del database interagiscono per raggiungere un unico scopo ben definito. Un'elevata coesione indica che gli elementi di un componente sono strettamente correlati e focalizzati su una funzione specifica. Quando si scompone un database monolitico, è necessario analizzare sia la coesione all'interno dei singoli componenti sia l'accoppiamento tra di essi. Questa analisi consente di prendere decisioni informate su come suddividere il database mantenendo al contempo l'integrità e le prestazioni del sistema.
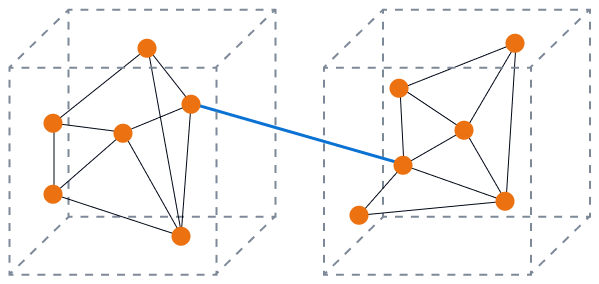
L'immagine seguente mostra un accoppiamento libero con un'elevata coesione. I componenti del database interagiscono per eseguire una funzione specifica e voi riducete al minimo l'impatto delle modifiche su un singolo componente. Questo è lo stato ideale.
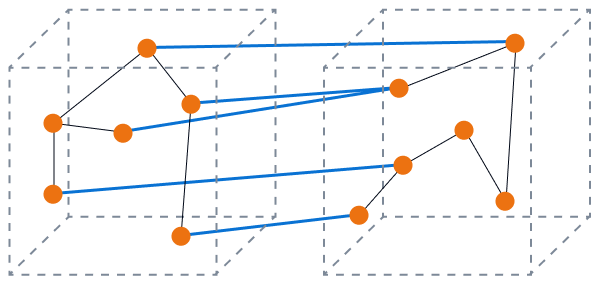
L'immagine seguente mostra un accoppiamento elevato con una bassa coesione. I componenti del database sono disconnessi ed è molto probabile che le modifiche influiscano su altri componenti.
Schemi di accoppiamento comuni nei database monolitici
Esistono diversi modelli di accoppiamento che si trovano comunemente quando si scompone un database monolitico in database specifici per microservizi. La comprensione di questi modelli è fondamentale per iniziative di modernizzazione dei database di successo. Questa sezione descrive ogni modello, le relative sfide e le migliori pratiche per ridurre l'accoppiamento.
Modello di accoppiamento dell'implementazione
Definizione: i componenti sono strettamente interconnessi a livello di codice e schema. Ad esempio, la modifica della struttura di una customer tabella influisce su orderinventory, e sui servizi. billing
Impatto della modernizzazione: ogni microservizio richiede uno schema di database e un livello di accesso ai dati dedicati.
Sfide:
-
Le modifiche alle tabelle condivise influiscono su più servizi
-
Alto rischio di effetti collaterali indesiderati
-
Maggiore complessità dei test
-
Difficile modificare i singoli componenti
Migliori pratiche per ridurre l'accoppiamento:
-
Definire interfacce chiare tra i componenti
-
Usa i livelli di astrazione per nascondere i dettagli di implementazione
-
Implementa schemi specifici del dominio
Schema di accoppiamento temporale
Definizione: le operazioni devono essere eseguite in una sequenza specifica. Ad esempio, l'elaborazione degli ordini non può procedere fino al completamento degli aggiornamenti dell'inventario.
Impatto della modernizzazione: ogni microservizio richiede un controllo autonomo dei dati.
Sfide:
-
Interruzione delle dipendenze sincrone tra i servizi
-
Colli di bottiglia in termini di prestazioni
-
Difficile da ottimizzare
-
Elaborazione parallela limitata
Migliori pratiche per ridurre l'accoppiamento:
-
Implementare l'elaborazione asincrona ove possibile
-
Utilizza architetture basate sugli eventi
-
Progetta per garantire la coerenza finale, se necessario
Schema di accoppiamento dell'implementazione
Definizione: i componenti del sistema devono essere distribuiti come una singola unità. Ad esempio, una modifica minore alla logica di elaborazione dei pagamenti richiede la ridistribuzione dell'intero database.
Impatto della modernizzazione: implementazioni di database indipendenti per servizio
Sfide:
-
Implementazioni ad alto rischio
-
Frequenza di implementazione limitata
-
Procedure di rollback complesse
Migliori pratiche per ridurre l'accoppiamento:
-
Suddivisione in componenti distribuibili in modo indipendente
-
Implementa strategie di condivisione del database
-
Utilizza modelli di distribuzione blu-verdi
Schema di accoppiamento del dominio
Definizione: i domini aziendali condividono la struttura e la logica del database. Ad esempio, i inventory domini customerorder, e condividono tabelle e stored procedure.
Impatto della modernizzazione: isolamento dei dati specifico del dominio
Sfide:
-
Confini di dominio complessi
-
Difficile scalare i singoli domini
-
Regole aziendali intricate
Le migliori pratiche per ridurre l'accoppiamento:
-
Identifica confini di dominio chiari
-
Separa i dati per contesto di dominio
-
Implementa servizi specifici del dominio
Modelli di coesione comuni nei database monolitici
Esistono diversi modelli di coesione che si riscontrano comunemente quando si valutano i componenti del database per la decomposizione. La comprensione di questi modelli è fondamentale per identificare componenti di database ben strutturati. Questa sezione descrive ogni modello, le sue caratteristiche e le migliori pratiche per rafforzare la coesione.
Modello di coesione funzionale
Definizione: tutti gli elementi supportano e contribuiscono direttamente all'esecuzione di un'unica funzione ben definita. Ad esempio, tutte le procedure e le tabelle memorizzate in un modulo di elaborazione dei pagamenti gestiscono solo le operazioni relative ai pagamenti.
Impatto sulla modernizzazione: modello ideale per la progettazione di database a microservizi
Sfide:
-
Identificazione di confini funzionali chiari
-
Separazione di componenti a uso misto
-
Mantenimento di un'unica responsabilità
Migliori pratiche per rafforzare la coesione:
-
Raggruppa le funzioni correlate
-
Rimuovi funzionalità non correlate
-
Definisci confini chiari dei componenti
Modello di coesione sequenziale
Definizione: l'output di un elemento diventa input per un altro. Ad esempio, i risultati di convalida di un ordine inserito nell'elaborazione degli ordini.
Impatto della modernizzazione: richiede un'attenta analisi del flusso di lavoro e una mappatura del flusso di dati
Sfide:
-
Gestione delle dipendenze tra i passaggi
-
Gestione degli scenari di errore
-
Mantenimento dell'ordine del processo
Migliori pratiche per rafforzare la coesione:
-
Documenta flussi di dati chiari
-
Implementa una corretta gestione degli errori
-
Progetta interfacce chiare tra i passaggi
Modello di coesione comunicativa
Definizione: gli elementi operano sugli stessi dati. Ad esempio, le funzioni di gestione dei profili dei clienti funzionano tutte con i dati dei clienti.
Impatto sulla modernizzazione: aiuta a identificare i limiti dei dati per la separazione dei servizi per ridurre l'accoppiamento tra i moduli
Sfide:
-
Definizione della proprietà dei dati
-
Gestione dell'accesso condiviso ai dati
-
Mantenere la coerenza dei dati
Migliori pratiche per rafforzare la coesione:
-
Definire una chiara proprietà dei dati
-
Implementa modelli di accesso ai dati adeguati
-
Progetta un partizionamento dei dati efficace
Modello procedurale di coesione
Definizione: gli elementi sono raggruppati perché devono essere eseguiti in un ordine specifico, ma potrebbero non essere correlati dal punto di vista funzionale. Ad esempio, nell'elaborazione degli ordini, una procedura memorizzata che gestisce sia la convalida degli ordini che la notifica all'utente viene raggruppata semplicemente perché avvengono in sequenza, anche se hanno scopi diversi e potrebbero essere gestite da servizi separati.
Impatto della modernizzazione: richiede un'attenta separazione delle procedure mantenendo al contempo il flusso dei processi
Sfide:
-
Mantenimento del corretto flusso di processo dopo la decomposizione
-
Identificazione dei veri limiti funzionali rispetto alle dipendenze procedurali
Migliori pratiche per rafforzare la coesione:
-
Procedure separate in base al loro scopo funzionale piuttosto che all'ordine di esecuzione
-
Utilizza modelli di orchestrazione per gestire il flusso dei processi
-
Implementa sistemi di gestione del flusso di lavoro per sequenze complesse
-
Progetta architetture basate sugli eventi per gestire le fasi del processo in modo indipendente
Modello di coesione temporale
Definizione: gli elementi sono correlati da requisiti temporali. Ad esempio, quando viene effettuato un ordine, è necessario eseguire più operazioni contemporaneamente: controllo dell'inventario, elaborazione dei pagamenti, conferma dell'ordine e notifica di spedizione devono avvenire tutte entro una finestra temporale specifica per mantenere uno stato dell'ordine coerente.
Impatto della modernizzazione: potrebbe richiedere una gestione speciale nei sistemi distribuiti
Sfide:
-
Coordinamento delle dipendenze temporali tra i servizi distribuiti
-
Gestione delle transazioni distribuite
-
Conferma del completamento del processo su più componenti
Migliori pratiche per rafforzare la coesione:
-
Implementare meccanismi e timeout di pianificazione adeguati
-
Utilizza architetture basate sugli eventi con una gestione chiara delle sequenze
-
Progettazione per una eventuale coerenza con i modelli di compensazione
-
Implementa modelli saga per transazioni distribuite
Modello di coesione logico o casuale
Definizione: Gli elementi sono classificati logicamente per fare le stesse cose, anche se hanno relazioni deboli o prive di significato. Un esempio è l'archiviazione dei dati degli ordini dei clienti, dei conteggi delle scorte di magazzino e dei modelli di e-mail di marketing nello stesso schema di database, poiché tutti si riferiscono alle operazioni di vendita, nonostante abbiano modelli di accesso, gestione del ciclo di vita e requisiti di scalabilità diversi. Un altro esempio è la combinazione dell'elaborazione dei pagamenti degli ordini e della gestione del catalogo dei prodotti all'interno dello stesso componente del database, poiché entrambi fanno parte del sistema di e-commerce, anche se svolgono funzioni aziendali distinte con esigenze operative diverse.
Impatto della modernizzazione: dovrebbe essere rifattorizzato o riorganizzato
Sfide:
-
Identificazione di modelli organizzativi migliori
-
Rompere le dipendenze non necessarie
-
Ristrutturazione di componenti raggruppati arbitrariamente
Migliori pratiche per rafforzare la coesione:
-
Riorganizza in base a confini funzionali e domini aziendali reali
-
Rimuovi i raggruppamenti arbitrari basati su relazioni superficiali
-
Implementa una corretta separazione degli elementi in base alle capacità aziendali
-
Allinea i componenti del database ai relativi requisiti operativi specifici
Implementazione di basso accoppiamento e alta coesione
Best practice
Le seguenti best practice possono aiutarti a ottenere un accoppiamento basso:
-
Riduci al minimo le dipendenze tra i componenti del database
-
Utilizza interfacce ben definite per l'interazione tra i componenti
-
Evita strutture di dati globali e statali condivise
Le seguenti best practice possono aiutarti a raggiungere un'elevata coesione:
-
Raggruppa i dati e le operazioni correlati
-
Assicurati che ogni componente abbia un'unica e chiara responsabilità
-
Mantieni confini chiari tra i diversi domini aziendali
Fase 1: mappare le dipendenze dei dati
Mappa le relazioni tra i dati e identifica i confini naturali. È possibile utilizzare strumenti, ad esempio SchemaSpy
È inoltre possibile esportare gli schemi del database in un database grafico o in un Jupiter taccuino. Quindi, è possibile applicare algoritmi di clustering o di componenti interconnessi per identificare confini e dipendenze naturali. Altri AWS Partner strumenti, ad esempio CAST Imaging
Fase 2: analisi dei limiti delle transazioni e dei modelli di accesso
Analizza i modelli di transazione per mantenere le proprietà di atomicità, coerenza, isolamento, durabilità (ACID) e scopri come i dati vengono accessibili e modificati. È possibile utilizzare strumenti di analisi e diagnosi del database, come Oracle Automatic Workload Repository (AWR)
Gli strumenti di intelligenza artificiale, ad esempio vFunction
Fase 3: Identificazione delle tabelle autonome
Cerca tabelle che dimostrino due caratteristiche chiave:
-
Elevata coesione: i contenuti della tabella sono strettamente correlati tra loro
-
Basso accoppiamento: hanno una dipendenza minima dalle altre tabelle.
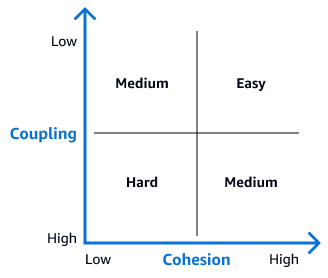
La seguente matrice di accoppiamento e coesione può aiutarvi a identificare la difficoltà di disaccoppiamento di ogni tabella. Le tabelle che appaiono nel quadrante in alto a destra di questa matrice sono le candidate ideali per le operazioni iniziali di disaccoppiamento perché sono le più facili da separare. In un diagramma ER, queste tabelle hanno poche relazioni con chiavi esterne o altre dipendenze. Dopo aver disaccoppiato queste tabelle, passa a tabelle con relazioni più complesse.
Nota
La struttura del database spesso rispecchia l'architettura dell'applicazione. Le tabelle più facili da disaccoppiare a livello di database corrispondono in genere a componenti più facili da convertire in microservizi a livello di applicazione.
