Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Controllo dell'accesso con il modello del servizio wrapper del database
Un servizio wrapper è un livello di servizio che funge da facciata per il database. Questo approccio è particolarmente utile quando è necessario mantenere le funzionalità esistenti preparandosi per future decomposizioni. Questo schema segue un principio semplice: quando qualcosa è troppo disordinato, inizia a contenere il disordine. Il servizio wrapper diventa l'unico modo autorizzato per accedere al database, fornendo un'interfaccia controllata e nascondendo la complessità sottostante.
Utilizzate questo modello quando la decomposizione immediata del database non è possibile a causa di schemi complessi o quando più servizi richiedono un accesso continuo ai dati. È particolarmente utile durante i periodi di transizione perché offre il tempo necessario per un accurato refactoring mantenendo al contempo la stabilità del sistema. Il modello funziona bene quando si consolida la proprietà dei dati a team specifici o quando nuove applicazioni richiedono viste aggregate su più tabelle.
Ad esempio, applica questo schema quando:
-
La complessità dello schema impedisce la separazione immediata
-
Più team hanno bisogno di un accesso continuo ai dati
-
È preferibile una modernizzazione graduale
-
La ristrutturazione del team richiede una chiara proprietà dei dati
-
Le nuove applicazioni richiedono viste di dati consolidate
Vantaggi e limiti del modello di servizio wrapper del database
Di seguito sono riportati i vantaggi del modello wrapper del database:
-
Crescita controllata: il servizio wrapper impedisce ulteriori aggiunte incontrollate allo schema del database.
-
Confini chiari: il processo di implementazione consente di stabilire chiari limiti di proprietà e responsabilità.
-
Libertà di refactoring: un servizio wrapper consente di apportare modifiche interne senza influire sui consumatori.
-
Migliore osservabilità: un servizio wrapper è un punto unico per il monitoraggio e la registrazione.
-
Test semplificati: un servizio wrapper semplifica l'utilizzo dei servizi per creare versioni simulate semplificate per i test.
Di seguito sono riportate le limitazioni del modello wrapper del database.
-
Accoppiamento tecnologico: un servizio wrapper funziona meglio quando utilizza lo stesso stack tecnologico dei servizi che lo utilizzano.
-
Sovraccarico iniziale: il servizio wrapper richiede un'infrastruttura aggiuntiva che potrebbe influire sulle prestazioni.
-
Impegno di migrazione: per implementare il servizio wrapper, è necessario coordinarsi tra i team in modo da abbandonare l'accesso diretto.
-
Prestazioni: se il servizio di wrapping registra un traffico elevato, un utilizzo intenso o un accesso frequente, i servizi che utilizzano potrebbero avere prestazioni scadenti. Oltre al database, il servizio wrapper deve gestire l'impaginazione, i cursori e le connessioni al database. A seconda del caso d'uso, potrebbe non scalare bene e potrebbe non essere adatto ai carichi di lavoro di estrazione, trasformazione e caricamento (ETL).
Implementazione del modello di servizio wrapper del database
Esistono due fasi per implementare il modello di servizio wrapper del database. Innanzitutto, si crea il servizio wrapper del database. Quindi, dirigete tutti gli accessi attraverso di esso e documentate i modelli di accesso.
Fase 1: creazione del servizio wrapper del database
Crea un livello di servizio leggero che funga da guardiano del tuo database. Inizialmente, dovrebbe rispecchiare tutte le funzionalità esistenti. Questo servizio wrapper diventa il punto di accesso obbligatorio per tutte le operazioni del database, che converte le dipendenze dirette del database in dipendenze a livello di servizio. Implementa la registrazione e il monitoraggio dettagliati a questo livello per tenere traccia dei modelli di utilizzo, delle metriche delle prestazioni e delle frequenze di accesso. Mantieni le procedure archiviate esistenti, ma assicurati che siano accessibili solo tramite questa nuova interfaccia di servizio.
Fase 2: implementazione del controllo degli accessi
Reindirizza sistematicamente tutti gli accessi al database tramite il servizio wrapper, quindi revoca le autorizzazioni dirette al database dai sistemi esterni che accedono direttamente al database. Documenta ogni modello di accesso e dipendenza durante la migrazione dei servizi. Questo accesso controllato consente il refactoring interno dei componenti del database senza interferire con gli utenti esterni. Ad esempio, inizia con operazioni a basso rischio e di sola lettura anziché flussi di lavoro transazionali complessi.
Fase 3: monitoraggio delle prestazioni del database
Utilizza il servizio wrapper come punto di monitoraggio centralizzato per le prestazioni del database. Tieni traccia delle metriche chiave, inclusi i tempi di risposta alle query, i modelli di utilizzo, i tassi di errore e l'utilizzo delle risorse. Imposta avvisi per soglie prestazionali e modelli insoliti. Ad esempio, monitora le query a esecuzione lenta, l'utilizzo del pool di connessioni e la velocità effettiva delle transazioni per identificare in modo proattivo potenziali problemi.
Utilizza questa visualizzazione consolidata per ottimizzare le prestazioni del database tramite l'ottimizzazione delle query, gli aggiustamenti dell'allocazione delle risorse e l'analisi dei modelli di utilizzo. La natura centralizzata del servizio wrapper semplifica l'implementazione dei miglioramenti e la convalida del loro impatto su tutti i consumatori, mantenendo al contempo standard prestazionali coerenti.
Le migliori pratiche per l'implementazione di un servizio di wrapper di database
Le seguenti best practice possono aiutarti a implementare un servizio di database wrapper:
-
Inizia in piccolo: inizia con un wrapper minimo che si limita a trasferire tramite proxy le funzionalità esistenti
-
Mantieni la stabilità: mantieni stabile l'interfaccia di servizio apportando miglioramenti interni
-
Monitora l'utilizzo: implementa un monitoraggio completo per comprendere i modelli di accesso
-
Proprietà chiara: assegna un team dedicato alla manutenzione sia del wrapper che dello schema sottostante
-
Incoraggia l'archiviazione locale: motiva i team a archiviare i propri dati nei propri database
Esempio basato su scenari
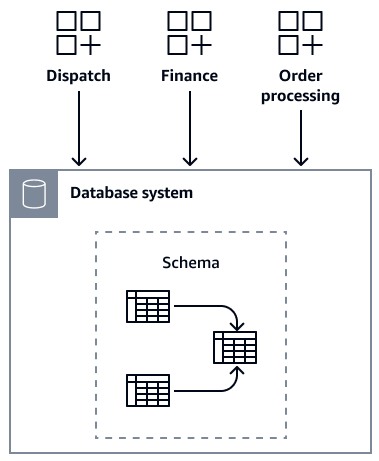
Questa sezione descrive un esempio di come un'azienda fittizia, denominata AnyCompany Books, potrebbe utilizzare il modello wrapper del database per controllare l'accesso al proprio sistema di database monolitico. In AnyCompany Books, ci sono tre servizi fondamentali: Dispatch, Finance ed Order Processing. Questi servizi condividono l'accesso a un database centrale. Ogni servizio è gestito da un team diverso. Nel tempo, modificano in modo indipendente lo schema del database per soddisfare le loro esigenze specifiche. Ciò ha portato a una rete intricata di dipendenze e a una struttura di database sempre più complessa.
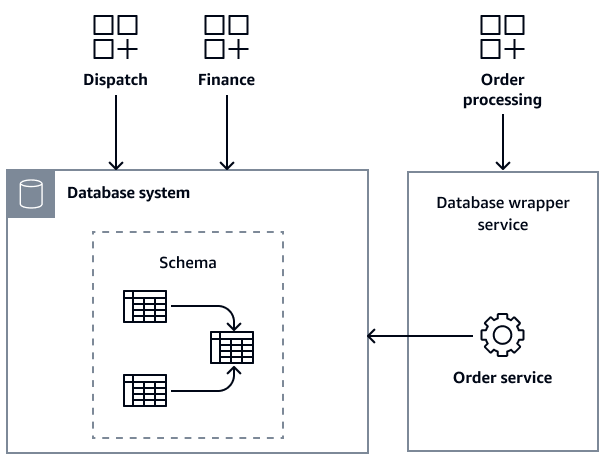
L'applicativo o l'architetto aziendale dell'azienda riconosce la necessità di scomporre questo database monolitico. Il loro obiettivo è fornire a ciascun servizio il proprio database dedicato per migliorare la manutenibilità e ridurre le dipendenze tra i team. Tuttavia, devono affrontare una sfida importante: è quasi impossibile scomporre il database mentre tutti e tre i team continuano a modificarlo attivamente per i progetti in corso. Le continue modifiche allo schema e la mancanza di coordinamento tra i team rendono estremamente rischioso tentare qualsiasi ristrutturazione significativa.
L'architetto utilizza il modello di servizio wrapper del database per iniziare a controllare l'accesso al database monolitico. Innanzitutto, hanno impostato il servizio wrapper del database per un particolare modulo, chiamato servizio Order. Quindi, reindirizzano il servizio di elaborazione degli ordini per accedere al servizio wrapper anziché accedere direttamente al database. L'immagine seguente mostra l'infrastruttura modificata.