Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
# Architettura di riferimento
Il diagramma seguente mostra il flusso di lavoro dopo aver applicato la soluzione automatizzata di questa guida a un rapporto operativo giornaliero. Quando nuovi file vengono importati in Amazon Simple Storage Service (Amazon S3), possono essere immediatamente visualizzati in una dashboard Quick Sight dopo l'elaborazione.
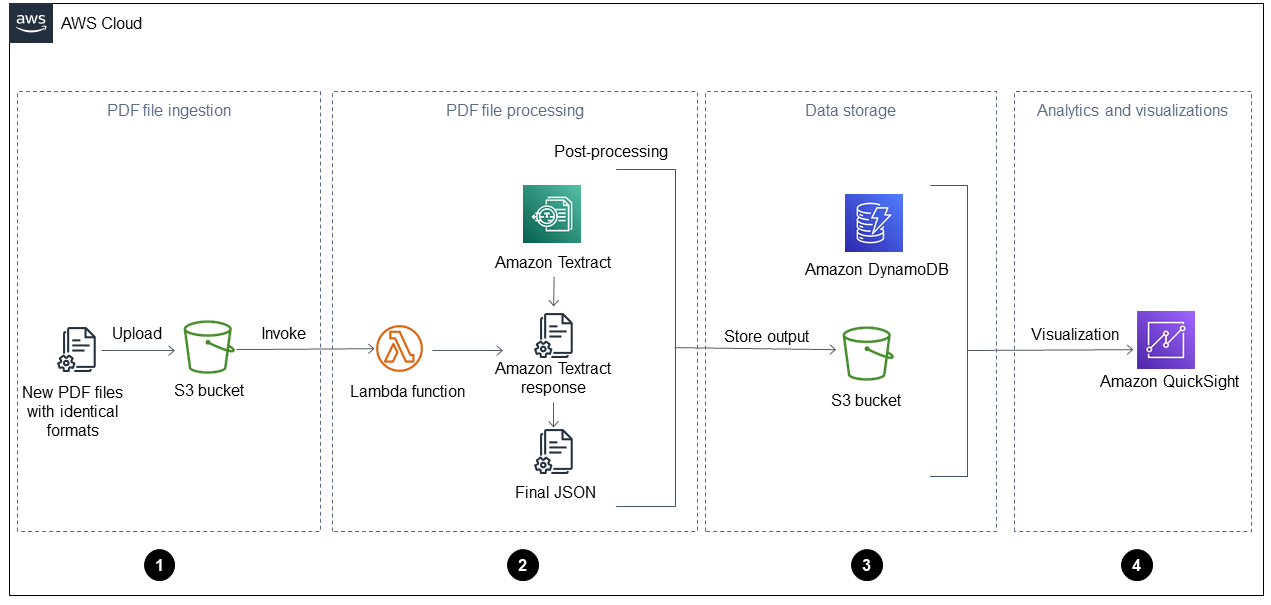
Il diagramma mostra le quattro fasi seguenti:
1. **Inserimento di file PDF**: l'applicazione inserisce automaticamente nuovi file PDF con un formato identico (ad esempio, un report operativo giornaliero) in un bucket Amazon Simple Storage Service (Amazon S3). Amazon S3 avvia un [`ObjectCreated`evento](https://docs.aws.amazon.com//AmazonS3/latest/userguide/NotificationHowTo.html) quando vengono aggiunti nuovi file PDF al bucket e questo richiama una funzione. AWS Lambda Per ulteriori informazioni su questo argomento, consulta [Usare un trigger di Amazon S3 per richiamare una funzione Lambda nella](https://docs.aws.amazon.com//lambda/latest/dg/with-s3-example.html) documentazione di Amazon S3.
1. **Elaborazione di file PDF**: la funzione Lambda invia un file PDF ad Amazon Textract, che estrae il contenuto. Uno script di post-elaborazione esegue e analizza la risposta di Amazon Textract e utilizza un modello predefinito per questo tipo di file PDF. Questo modello contiene gli attributi corretti e aiuta a estrarre correttamente tutte le coppie chiave-valore, le tabelle e altro testo non elaborato. Per ulteriori informazioni su questo argomento, consulta lo schema [Estrarre automaticamente il contenuto dai file PDF utilizzando Amazon Textract](https://docs.aws.amazon.com//prescriptive-guidance/latest/patterns/automatically-extract-content-from-pdf-files-using-amazon-textract.html?did=pg_card&trk=pg_card) sul sito Web AWS Prescriptive Guidance.
1. **Archiviazione dei dati**: i dati estratti e corretti vengono archiviati in una tabella Amazon DynamoDB, oltre a un file JSON per ogni file PDF. [https://docs.aws.amazon.com//quicksight/latest/user/welcome.html](https://docs.aws.amazon.com//quicksight/latest/user/welcome.html)
1. **Analisi e visualizzazioni**: Quick Sight analizza i dati e crea visualizzazioni che aiutano a generare approfondimenti per tutti i file PDF elaborati. Dopo aver creato i dashboard in Quick Sight, puoi condividerli con gli utenti finali e i team aziendali.
## Considerazioni
La soluzione di questa guida è appropriata per l'elaborazione di file PDF con un formato identico e un layout coerente di moduli e tabelle. Tuttavia, è necessario definire un modello e modificarlo in anticipo per automatizzare completamente il processo e rendere disponibili i dati estratti per l'analisi. Questo modello viene quindi utilizzato durante l'elaborazione con la funzione Lambda.
Sebbene questa soluzione possa essere applicata a diversi tipi di file PDF contemporaneamente, è necessario creare e definire modelli separati per ogni tipo di file PDF e archiviarli in una posizione accessibile (ad esempio, Amazon S3). Ti consigliamo di utilizzare un identificatore univoco per ogni tipo di file PDF, ad esempio un nome di file PDF o cartelle diverse nel tuo bucket S3. La funzione Lambda può quindi richiamare il modello appropriato durante l'elaborazione del tipo di file PDF.