Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase di elaborazione
Amazon Textract estrae il contenuto dei file PDF come stringhe che non possono essere utilizzate direttamente dalle applicazioni downstream (ad esempio, per generare statistiche aggregando numeri). I valori dei dati identificati e trasformati correttamente sono necessari perché possono essere utilizzati più facilmente dalle applicazioni a valle (ad esempio, per tracciare le tendenze dei costi sotto forma di serie temporali). Per implementare l'elaborazione dei file PDF, un file PDF per ogni nuovo tipo di file PDF deve essere elaborato una sola volta tramite Amazon Textract, che genera quindi un Template file in formato JSON.
Una volta avviata in, la AWS Lambda funzione esegue i passaggi illustrati nel Fase di ingestione diagramma seguente.
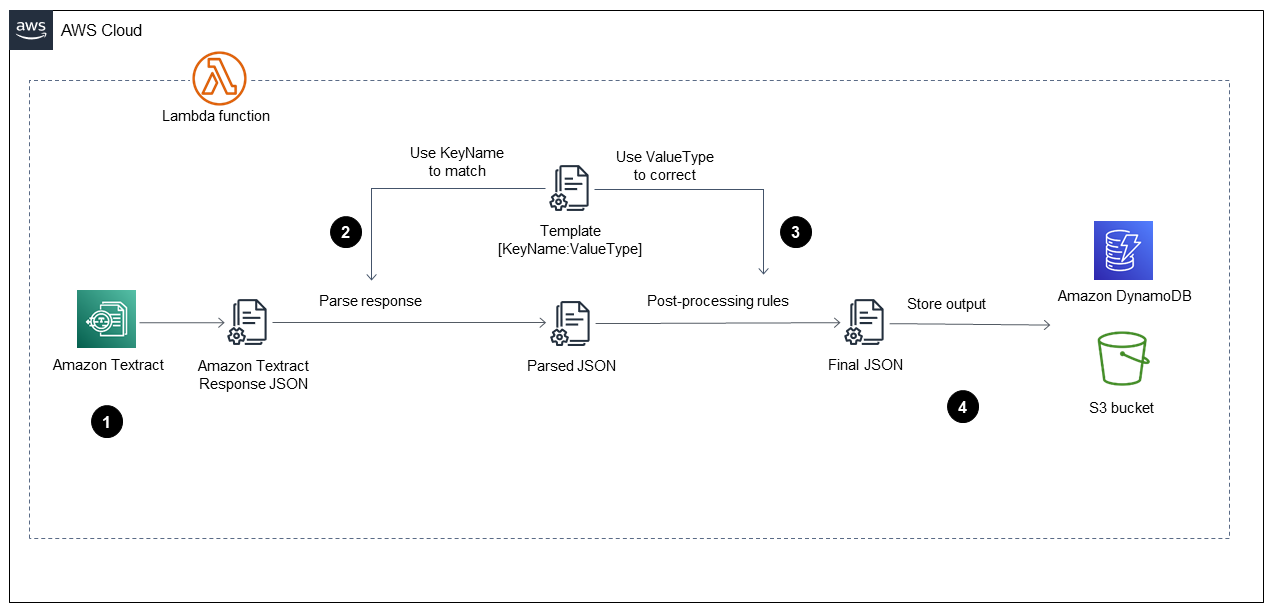
Il diagramma mostra la funzione Lambda che implementa i seguenti passaggi:
-
Richiama Amazon Textract per elaborare il file PDF, estrarre il contenuto e restituire un file in formato JSON.
-
Prende il file JSON e analizza moduli e tabelle utilizzando un file
TemplateJSON predefinito con il nome chiave e il tipo di valore corretti per ogni campo. Questo processo fornisce un file JSON analizzato. -
Applica le regole di post-elaborazione e utilizza il file
TemplateJSON per correggere ogni valore nel file JSON analizzato. Questo produce il file JSON.FinalIl fileTemplateJSON predefinito può essere archiviato nel bucket S3. -
Memorizza il file
FinalJSON in Amazon DynamoDB come un record per ogni file PDF, oltre a un file JSON per ogni file PDF in un bucket di output S3.
Per un step-by-step flusso di lavoro che utilizza Amazon Textract per estrarre automaticamente il contenuto dai file PDF ed elaborarlo in un output pulito, consulta lo schema Estrarre automaticamente il contenuto dai file PDF utilizzando Amazon Textract sul AWS sito Web Prescriptive Guidance. Il modello utilizza una tecnica di abbinamento dei modelli per identificare correttamente il campo, il nome chiave e le tabelle richiesti, quindi applica le correzioni post-elaborazione a ciascun tipo di dati.
Le migliori pratiche per la fase di elaborazione
Utilizza le seguenti quattro best practice per garantire una fase di elaborazione corretta:
-
Crea un file JSON modello per ogni tipo di file PDF che desideri elaborare. Puoi memorizzare questi diversi file JSON modello in un bucket S3 chiamato dalla funzione Lambda. Se desideri elaborare diversi tipi di file PDF in un'unica funzione Lambda, devi utilizzare un identificatore univoco per ogni tipo di file PDF (ad esempio, il nome della cartella del tipo di file PDF nel bucket S3). Dopo essere stata richiamata, la funzione Lambda recupera il file JSON modello appropriato e lo elabora.
-
Imposta un meccanismo per tracciare con precisione lo stato di ogni passaggio della funzione Lambda. Ad esempio, puoi aggiungere
Successstati per dopo la chiamata Amazon Textract, quando il file JSON finale viene salvato in una tabella Amazon DynamoDB o quando i file PDF vengono salvati in un bucket S3. È inoltre possibile creare una tabella DynamoDB separata per tenere traccia dello stato di ogni file PDF nelle diverse fasi, in modo da garantire la visibilità del processo. -
Gestisci le limitazioni e le interruzioni delle connessioni riprovando automaticamente le operazioni non riuscite quando elabori in batch molti file PDF. La limitazione può verificarsi in Amazon Textract se la connessione si interrompe o si supera il numero massimo di transazioni al secondo (TPS). Per ulteriori informazioni e passaggi per riprovare automaticamente le operazioni non riuscite, consulta Gestione delle chiamate limitate e delle connessioni interrotte nella documentazione di Amazon Textract.
-
Se disponi di file PDF con più pagine, puoi utilizzare un'operazione asincrona per elaborare l'intero file o suddividere il file PDF in una singola pagina, utilizzare un'operazione sincrona per elaborare ogni pagina e quindi combinare i risultati di ciascuna pagina. Per un'implementazione completa del codice di un'operazione asincrona, consulta Rilevamento e analisi del testo in documenti multipagina nella documentazione di Amazon Textract. Per ulteriori informazioni sull'utilizzo di un'operazione sincrona, consulta Rilevamento e analisi del testo nei documenti a pagina singola nella documentazione di Amazon Textract.
