Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica di DR Orchestrator Framework
DR Orchestrator Framework offre una soluzione con un solo clic per orchestrare e automatizzare il ripristino di emergenza interregionale per i database. AWS Utilizza AWS Step Functionsed esegue i passaggi richiesti durante AWS Lambdail failover e il failback. Le macchine a stati Step Functions forniscono la base per il processo decisionale all'interno della progettazione dell'orchestratore. Le operazioni API per l'esecuzione di azioni di failover o failback sono codificate in funzioni Lambda richiamate dall'interno della macchina a stati. Le funzioni Lambda vengono eseguite AWS SDK per Python (Boto3)
DR Orchestrator Framework contiene due macchine a stati principali che corrispondono alle fasi di failover e failback.
Per Amazon RDS, la fase di failover promuove una replica di lettura RDS interregionale in un'istanza DB autonoma. Per Amazon Aurora, quando la regione principale è inattiva durante un'interruzione rara e inaspettata, il relativo nodo di scrittura non è disponibile. La replica tra il nodo di scrittura e i cluster secondari si interrompe. È necessario scollegare il cluster secondario dal database globale e promuoverlo come cluster autonomo. Le applicazioni possono connettersi e inviare traffico di scrittura al cluster autonomo. È possibile utilizzare lo stesso processo per passare dal cluster DB primario del database globale alle regioni secondarie. Utilizzate questo approccio per scenari controllati come i seguenti:
-
Manutenzione operativa
-
Procedure operative pianificate
-
Promozione di un cluster secondario Amazon ElastiCache (Redis OSS) come nuovo cluster primario
La fase di failback stabilisce la replica in tempo reale dei dati tra una regione primaria attiva e una nuova regione secondaria.
È fondamentale comprendere che DR Orchestrator si applica solo ai database. Tutte le applicazioni che fanno riferimento a questi database e si trovano nella stessa regione potrebbero richiedere una soluzione di failover tandem separata. Dopo il failover dei database nella regione secondaria, è necessario aggiornare le applicazioni per connettersi alle nuove istanze del database, che fungeranno da origine dati.
Il processo di failover
Per eseguire un failover, eseguite la macchina a DR Orchestrator FAILOVER stati. In questa fase, un database secondario è già presente nella regione secondaria, come replica di lettura (Amazon RDS) o come cluster secondario (Amazon Aurora). Quando si esegue la macchina a DR Orchestrator
FAILOVER stati, il database secondario diventa il principale.
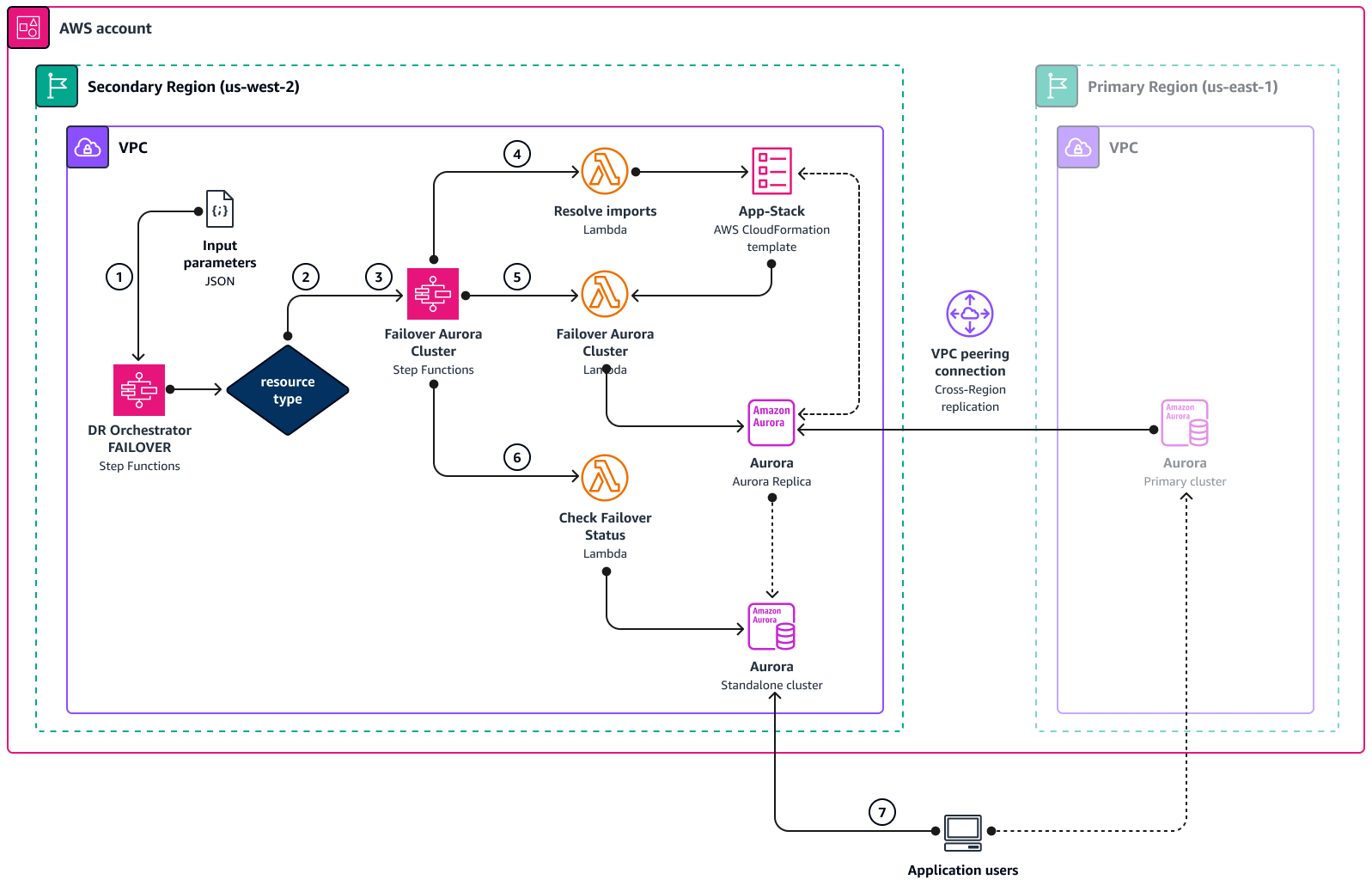
Architettura di DR Orchestrator FAILOVER
Il diagramma seguente mostra i concetti del processo di failover per Amazon Aurora quando si utilizza DR Orchestrator. Amazon Aurora e Amazon ElastiCache utilizzano lo stesso flusso di lavoro ma con macchine a stati e funzioni Lambda diverse.
-
La macchina a
DR Orchestrator FAILOVERstati legge i parametri JSON di input. -
In base al
resourceTypeparametro, la macchina a stati chiama altre macchine a stati:Promote RDS Read ReplicaFailover Aurora Cluster, o.Failover ElastiCacheSe nell'input viene passata più di una risorsa, queste macchine a stati funzionano in parallelo. -
La macchina a
Failover Aurora Clusterstati richiama le funzioni Lambda in ciascuno dei tre passaggi seguenti. -
La funzione
Resolve importsLambda si risolve"! import <export-variable-name>"con i valori effettivi del modello.App-StackAWS CloudFormation -
La funzione
Failover Aurora ClusterLambda promuove la replica di lettura come istanza DB autonoma. -
La funzione
Check Failover StatusLambda controlla lo stato dell'istanza DB promossa. Dopo che lo stato è DISPONIBILE, la funzione Lambda invia un token di successo alla macchina a stati chiamante e completa. -
È possibile reindirizzare le applicazioni al database autonomo nella regione DR (
us-west-2), che ora è il database principale.
Il processo di failback
Dopo che la regione principale precedente (us-east-1) è stata nuovamente attivata, è possibile eseguire il failback, in modo che il database in entrata us-east-1 diventi nuovamente la principale. Per avviare il failback, esegui la macchina a DR Orchestrator FAILBACK stati. Come indica il nome, questa macchina a stati inizia a replicare le modifiche nella nuova regione principale (us-west-2) nella precedente regione primaria (us-east-1), che funge da regione secondaria corrente.
Una volta stabilita la replica tra le due regioni, è possibile avviare il failback. Per eseguire il failback e tornare alla regione primaria originale (us-east-1), esegui la macchina a DR Orchestrator FAILOVER stati nella regione secondaria corrente (us-east-1) per promuoverla nella regione primaria.
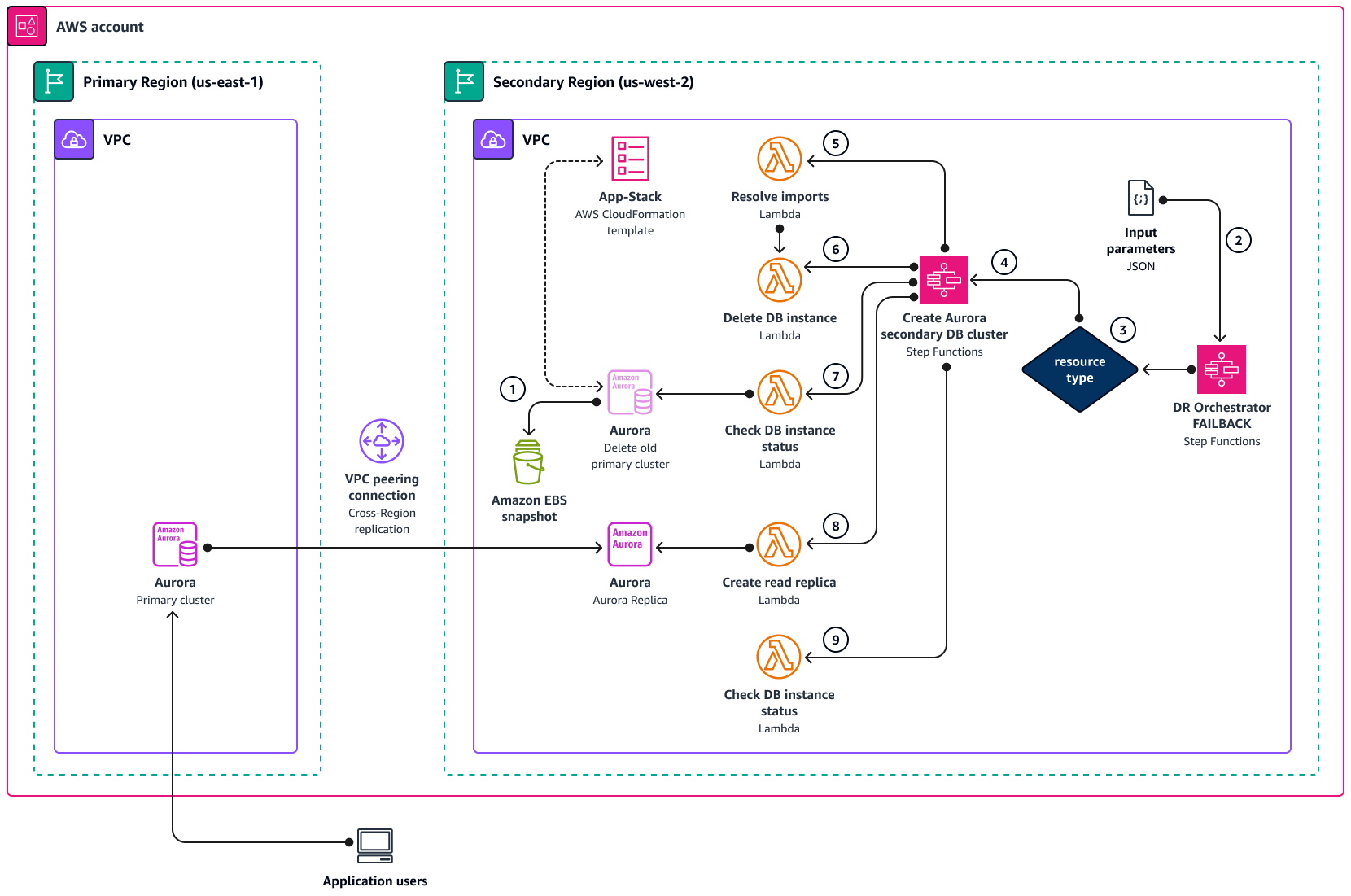
Architettura di DR Orchestrator FAILBACK
Il diagramma seguente mostra i concetti del processo di failback per Amazon Aurora quando si utilizza DR Orchestrator.
-
Prima di iniziare il failback, scatta un'istantanea manuale del DB da utilizzare quando si esegue l'analisi della causa principale (RCA).
Inoltre, disabilita il
DeletionProtectionper il cluster Aurora nella regione primaria precedente ()us-east-1. -
La macchina a
DR Orchestrator FAILBACKstati legge i parametri JSON di input. -
In base a
resourceType, la macchina aDR Orchestrator FAILBACKstati chiama la macchina aCreate Aurora Secondary DB Clusterstati. -
La macchina a
Create Aurora Secondary DB Clusterstati richiama le funzioni Lambda in ciascuno dei seguenti cinque passaggi. -
La funzione
Resolve importLambda si risolve"! import <export-variable-name>"con i valori effettivi del modello.App-StackCloudFormation -
La funzione
Delete DB InstanceLambda elimina la precedente istanza principale. -
La funzione
Check DB instance statusLambda controllaDelete DB Instance statusfino all'eliminazione del DB. -
La funzione
Create Read ReplicaLambda crea una replica di lettura nella regione secondaria dall'istanza DB che si trova nella nuova regione primaria. -
La funzione
Check DB instance statusLambda verifica lo stato dell'istanza DB di replica in lettura. Quando lo stato è DISPONIBILE, la funzione Lambda invia un token di successo alla macchina a stati chiamante, operazione completata.
FAILOVER DI DR Orchestrator
Utilizza la macchina a DR Orchestrator FAILOVER stati nell'evento DR quando la regione primaria (us-east-1) è inattiva o durante eventi pianificati come la manutenzione operativa.
La funzione può essere chiamata per eseguire il failover di uno o più database in parallelo.
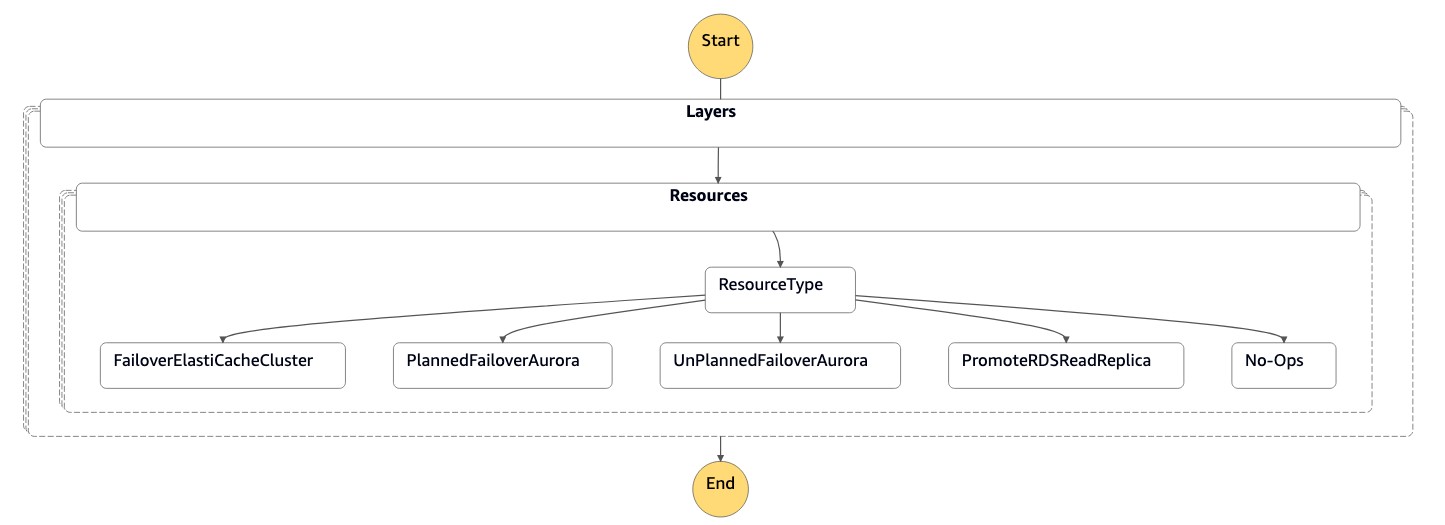
La macchina a stati accetta parametri in formato JSON, come illustrato nel codice seguente:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PromoteRDSReadReplica", "resourceName": "Promote RDS MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn" } }, { "resourceType": "FailoverElastiCacheCluster", "resourceName": "Failover ElastiCache Cluster", "parameters": { "GlobalReplicationGroupId": "!Import demo-redis-cluster-global-replication-group-id", "TargetRegion": "!Import demo-redis-cluster-target-region", "TargetReplicationGroupId": "!Import demo-redis-cluster-target-replication-group-id" } } ] } ] }
Dettagli dei parametri
La tabella seguente mostra i parametri utilizzati dalla macchina a DR Orchestrator
FAILOVER stati.
| Nome del parametro | Description | Valori previsti |
|---|---|---|
layer(obbligatorio: numero) |
La sequenza di elaborazione. Tutte le risorse definite nel livello 1 devono essere eseguite prima dell'esecuzione delle risorse del livello 2. | 1 o 2 e così via |
| risorse (richiesto: matrice di dizionari) | Tutte le risorse all'interno di un singolo livello vengono eseguite in parallelo. |
|
resourceType(obbligatorio: stringa) |
Tipo di risorsa per identificare la risorsa | PromoteRDSReadReplica o FailoverElastiCacheCluster |
resourceName(opzionale: stringa) |
Per identificare a quale portafoglio di applicazioni appartengono queste risorse | Promote RDS for MySQL Read Replica |
| parametri (obbligatorio: matrice di dizionari) | Elenco dei parametri necessari per eseguire il failover o il failback del AWS database |
|
FAILBACK DI DR Orchestrator
Utilizza la macchina a DR Orchestrator FAILBACK stati dopo l'evento DR, quando la precedente regione primaria () us-east-1 è attiva. Puoi creare la replica di lettura per Amazon RDS nella precedente regione principale dalla nuova regione principale (us-west-2) per renderla conforme alla tua strategia di disaster recovery. Poiché si tratta di un evento pianificato, puoi pianificare questa attività durante il fine settimana o durante le ore lavorative non di punta con un tempo di inattività stimato.
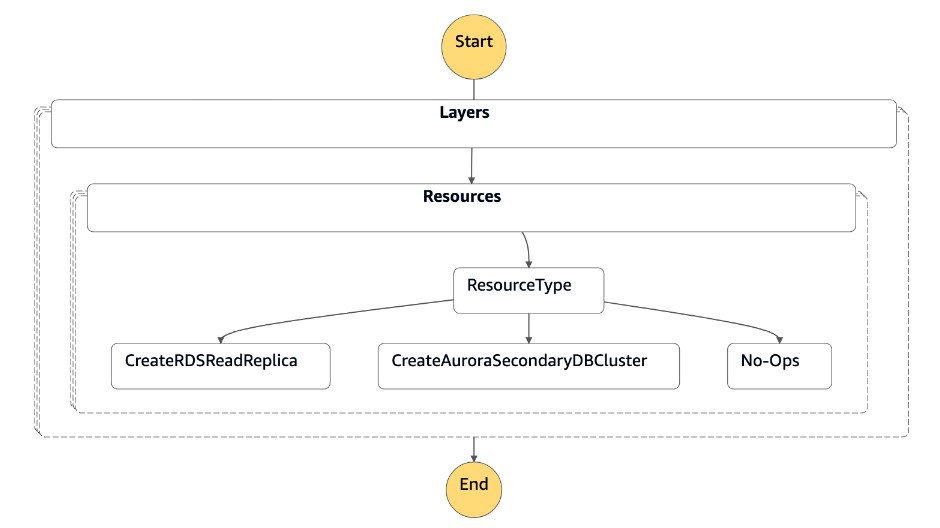
La macchina a stati accetta parametri in formato JSON, come illustrato nel codice seguente:
{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateRDSReadReplica", "resourceName": "Create RDS for MySQL Read Replica", "parameters": { "RDSInstanceIdentifier": "!Import rds-mysql-instance-identifier", "TargetClusterIdentifier": "!Import rds-mysql-instance-global-arn", "SourceRDSInstanceIdentifier": "!Import rds-mysql-instance-source-identifier", "SourceRegion": "!Import rds-mysql-instance-SourceRegion", "MultiAZ": "!Import rds-mysql-instance-MultiAZ", "DBInstanceClass": "!Import rds-mysql-instance-DBInstanceClass", "DBSubnetGroup": "!Import rds-mysql-instance-DBSubnetGroup", "DBSecurityGroup": "!Import rds-mysql-instance-DBSecurityGroup", "KmsKeyId": "!Import rds-mysql-instance-KmsKeyId", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "Port": "!Import rds-mysql-instance-DBPortNumber", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] }
