Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Migrazione sul posto
La migrazione sul posto elimina la necessità di riscrivere tutti i file di dati. I file di metadati Iceberg vengono invece generati e collegati ai file di dati esistenti. Questo metodo è in genere più veloce ed economico, soprattutto per set di dati o tabelle di grandi dimensioni con formati di file compatibili come Parquet, Avro e ORC.
Nota
La migrazione sul posto non può essere utilizzata durante la migrazione a Amazon S3 Tables.
Iceberg offre due opzioni principali per implementare la migrazione sul posto:
-
Utilizzo della procedura snapshot
per creare una nuova tabella Iceberg mantenendo invariata la tabella di origine. Per ulteriori informazioni, consulta Snapshot Table nella documentazione di Iceberg. -
Utilizzo della procedura di migrazione
per creare una nuova tabella Iceberg in sostituzione della tabella di origine. Per ulteriori informazioni, consulta Migrate Table nella documentazione di Iceberg. Sebbene questa procedura funzioni con Hive Metastore (HMS), attualmente non è compatibile con. AWS Glue Data Catalog La procedura di replica della migrazione delle tabelle riportata più AWS Glue Data Catalog avanti in questa guida fornisce una soluzione alternativa per ottenere un risultato simile con Data Catalog.
Dopo aver eseguito la migrazione sul posto utilizzando uno dei due snapshot omigrate, alcuni file di dati potrebbero rimanere non migrati. Ciò accade in genere quando gli autori continuano a scrivere nella tabella di origine durante o dopo la migrazione. Per incorporare questi file rimanenti nella tabella Iceberg, è possibile utilizzare la procedura add_files
Supponiamo che tu abbia una products tabella basata su Parquet che è stata creata e popolata in Athena come segue:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
Le sezioni seguenti spiegano come utilizzare le procedure snapshot and migrate con questa tabella.
Opzione 1: procedura di istantanea
La snapshot procedura crea una nuova tabella Iceberg con un nome diverso ma replica lo schema e il partizionamento della tabella di origine. Questa operazione lascia la tabella di origine completamente invariata sia durante che dopo l'azione. Crea in modo efficace una copia leggera della tabella, particolarmente utile per testare scenari o esplorare i dati senza rischiare di modificare la fonte di dati originale. Questo approccio consente un periodo di transizione in cui sia la tabella originale che la tabella Iceberg rimangono disponibili (vedi le note alla fine di questa sezione). Una volta completato il test, puoi portare la tua nuova tabella Iceberg in produzione trasferendo tutti gli autori e i lettori alla nuova tabella.
Puoi eseguire la snapshot procedura utilizzando Spark in qualsiasi modello di distribuzione Amazon EMR (ad esempio, Amazon EMR su EC2, Amazon EMR su EKS, EMR Serverless) e. AWS Glue
Per testare la migrazione sul posto con la procedura Spark, segui questi passaggi: snapshot
-
Avvia un'applicazione Spark e configura la sessione Spark con le seguenti impostazioni:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Esegui la
snapshotprocedura per creare una nuova tabella Iceberg che punti ai file di dati della tabella originale:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)Il dataframe di output contiene
imported_files_count(il numero di file che sono stati aggiunti). -
Convalida la nuova tabella interrogandola:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Note
-
Dopo aver eseguito la procedura, qualsiasi modifica del file di dati sulla tabella di origine non sincronizzerà la tabella generata. I nuovi file aggiunti non saranno visibili nella tabella Iceberg e i file rimossi influiranno sulle funzionalità di interrogazione nella tabella Iceberg. Per evitare problemi di sincronizzazione:
-
Se la nuova tabella Iceberg è destinata all'uso in produzione, interrompi tutti i processi che scrivono sulla tabella originale e reindirizzali alla nuova tabella.
-
Se hai bisogno di un periodo di transizione o se la nuova tabella Iceberg è a scopo di test, consulta Mantenere le tabelle Iceberg sincronizzate dopo la migrazione sul posto più avanti in questa sezione per indicazioni su come mantenere la sincronizzazione delle tabelle.
-
-
Quando si utilizza la
snapshotprocedura, lagc.enabledproprietà viene impostata sulle proprietà della tabella Iceberg creata.falseQuesta impostazione proibisce azioni comeexpire_snapshots, oDROP TABLEcon l'PURGEopzioneremove_orphan_files, che eliminerebbero fisicamente i file di dati. Le operazioni di eliminazione o unione di Iceberg, che non hanno un impatto diretto sui file sorgente, sono ancora consentite. -
Per rendere la tua nuova tabella Iceberg completamente funzionante, senza limiti alle azioni che eliminano fisicamente i file di dati, puoi modificare la proprietà della
gc.enabledtabella in.trueTuttavia, questa impostazione consentirà azioni che influiscono sui file di dati di origine, che potrebbero compromettere l'accesso alla tabella originale. Pertanto, modificate lagc.enabledproprietà solo se non è più necessario mantenere la funzionalità della tabella originale. Esempio:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Opzione 2: procedura di migrazione
La migrate procedura crea una nuova tabella Iceberg con lo stesso nome, schema e partizionamento della tabella di origine. Quando viene eseguita, questa procedura blocca la tabella di origine e la rinomina in <table_name>_BACKUP_ (o in un nome personalizzato specificato dal parametro della procedura). backup_table_name
Nota
Se si imposta il parametro della drop_backup procedura sutrue, la tabella originale non verrà conservata come backup.
Di conseguenza, la procedura della migrate tabella richiede che tutte le modifiche che influiscono sulla tabella di origine vengano interrotte prima dell'esecuzione dell'azione. Prima di eseguire la migrate procedura:
-
Interrompi tutti gli scrittori che interagiscono con la tabella dei sorgenti.
-
Modifica lettori e scrittori che non supportano nativamente Iceberg per abilitare il supporto Iceberg.
Esempio:
-
Athena continua a lavorare senza modifiche.
-
Spark richiede:
-
File Iceberg Java Archive (JAR) da includere nel classpath (consulta le sezioni Lavorare con Iceberg in Amazon EMR e Lavorare con Iceberg AWS Glue nelle sezioni precedenti di questa guida).
-
Le seguenti configurazioni del catalogo delle sessioni Spark (utilizzate
SparkSessionCatalogper aggiungere il supporto Iceberg mantenendo le funzionalità di catalogo integrate per le tabelle non Iceberg):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Dopo aver eseguito la procedura, potete riavviare i vostri writer con la nuova configurazione di Iceberg.
Attualmente, la migrate procedura non è compatibile con AWS Glue Data Catalog, poiché il Data Catalog non supporta l'RENAMEoperazione. Pertanto, ti consigliamo di utilizzare questa procedura solo quando lavori con Hive Metastore. Se utilizzi il Data Catalog, consulta la sezione successiva per un approccio alternativo.
Puoi eseguire la migrate procedura su tutti i modelli di distribuzione di Amazon EMR (Amazon EMR su EC2, Amazon EMR su EKS, EMR Serverless) e AWS Glue, ma richiede una connessione configurata a Hive Metastore. Amazon EMR su EC2 è la scelta consigliata perché fornisce una configurazione Hive Metastore integrata, che riduce al minimo la complessità di configurazione.
Per testare la migrazione sul posto con la procedura migrate Spark da un cluster Amazon EMR su EC2 configurato con Hive Metastore, segui questi passaggi:
-
Avvia un'applicazione Spark e configura la sessione Spark per utilizzare l'implementazione del catalogo Iceberg Hive. Ad esempio, se utilizzi la
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Crea una
productstabella in Hive Metastore. Questa è la tabella di origine, che esiste già in una migrazione tipica.-
Crea la tabella Hive
productsesterna in Hive Metastore per puntare ai dati esistenti in Amazon S3:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Aggiungi le partizioni esistenti utilizzando il comando:
MSCK REPAIR TABLEspark.sql(f""" MSCK REPAIR TABLE products """ ) -
Verifica che la tabella contenga dati eseguendo una
SELECTquery:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Output di esempio:

-
-
Usa la procedura Iceberg:
migratedf_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()Il dataframe di output contiene
migrated_files_count(il numero di file che sono stati aggiunti alla tabella Iceberg):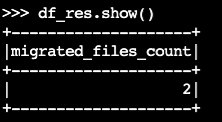
-
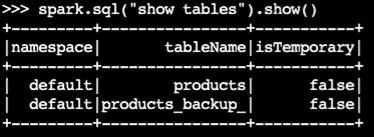
Conferma che la tabella di backup è stata creata:
spark.sql("show tables").show()Output di esempio:
-
Convalida l'operazione interrogando la tabella Iceberg:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Note
-
Dopo aver eseguito la procedura, tutti i processi correnti che eseguono query o scrivono nella tabella di origine ne risentiranno se non sono configurati correttamente con il supporto Iceberg. Pertanto, ti consigliamo di seguire questi passaggi:
-
Arresta tutti i processi utilizzando la tabella di origine prima della migrazione.
-
Eseguire la migrazione.
-
Riattiva i processi utilizzando le impostazioni Iceberg appropriate.
-
-
Se durante il processo di migrazione si verificano modifiche ai file di dati (vengono aggiunti nuovi file o rimossi), la tabella generata non sarà sincronizzata. Per le opzioni di sincronizzazione, vedi Mantenere sincronizzate le tabelle Iceberg dopo la migrazione sul posto più avanti in questa sezione.
Replica della procedura di migrazione delle tabelle in AWS Glue Data Catalog
È possibile replicare il risultato della procedura di migrazione in AWS Glue Data Catalog (eseguire il backup della tabella originale e sostituirla con una tabella Iceberg) seguendo questi passaggi:
-
Utilizzate la procedura snapshot per creare una nuova tabella Iceberg che punti ai file di dati della tabella originale.
-
Esegui il backup dei metadati della tabella originale nel Data Catalog:
-
Utilizza l'GetTableAPI per recuperare la definizione della tabella di origine.
-
Utilizza l'GetPartitionsAPI per recuperare la definizione della partizione della tabella di origine.
-
Utilizza l'CreateTableAPI per creare una tabella di backup nel Data Catalog.
-
Utilizza l'BatchCreatePartitionAPI CreatePartitiono per registrare le partizioni nella tabella di backup nel Data Catalog.
-
-
Modifica la proprietà della tabella
gc.enabledIceberg perfalseabilitare le operazioni complete della tabella. -
Rilasciare la tabella originale.
-
Individua il file JSON dei metadati della tabella Iceberg nella cartella dei metadati della posizione principale della tabella.
-
Registra la nuova tabella nel Data Catalog utilizzando la procedura register_table
con il nome della tabella originale e la posizione del metadata.jsonfile creato dalla procedura:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Mantenere sincronizzate le tabelle Iceberg dopo la migrazione sul posto
La add_files procedura fornisce un modo flessibile per incorporare i dati esistenti nelle tabelle Iceberg. In particolare, registra i file di dati esistenti (come i file Parquet) facendo riferimento ai loro percorsi assoluti nel livello di metadati di Iceberg. Per impostazione predefinita, la procedura aggiunge file da tutte le partizioni di tabella a una tabella Iceberg, ma è possibile aggiungere selettivamente file da partizioni specifiche. Questo approccio selettivo è particolarmente utile in diversi scenari:
-
Quando vengono aggiunte nuove partizioni alla tabella di origine dopo la migrazione iniziale.
-
Quando i file di dati vengono aggiunti o rimossi da partizioni esistenti dopo la migrazione iniziale. Tuttavia, la riaggiunta di partizioni modificate richiede prima l'eliminazione delle partizioni. Ulteriori informazioni al riguardo sono fornite più avanti in questa sezione.
Ecco alcune considerazioni sull'utilizzo della add_file procedura dopo l'esecuzione della migrazione sul posto (snapshotomigrate), per mantenere la nuova tabella Iceberg sincronizzata con i file di dati di origine:
-
Quando vengono aggiunti nuovi dati a nuove partizioni nella tabella di origine, utilizzate la
add_filesprocedura con l'partition_filteropzione per incorporare selettivamente queste aggiunte nella tabella Iceberg:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)oppure:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
La
add_filesprocedura cerca i file nell'intera tabella di origine o in partizioni specifiche quando specificate l'partition_filteropzione e tenta di aggiungere tutti i file trovati alla tabella Iceberg. Per impostazione predefinita, la proprietà dellacheck_duplicate_filesprocedura è impostata sutrue, il che impedisce l'esecuzione della procedura se i file esistono già nella tabella Iceberg. Questo è importante perché non esiste un'opzione integrata per ignorare i file aggiunti in precedenza e la disattivazionecheck_duplicate_filescomporterà l'aggiunta di due volte dei file, con la conseguente creazione di duplicati. Quando vengono aggiunti nuovi file alla tabella di origine, procedi nel seguente modo:-
Per le nuove partizioni, usa
add_fileswithpartition_filtera per importare solo i file dalla nuova partizione. -
Per le partizioni esistenti, eliminate prima la partizione dalla tabella Iceberg, quindi eseguitela nuovamente
add_filesper quella partizione, specificando.partition_filterEsempio:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
Nota
Ogni add_files operazione genera una nuova istantanea della tabella Iceberg con dati aggiunti.
Scelta della giusta strategia di migrazione in atto
Per scegliere la migliore strategia di migrazione sul posto, considera le domande nella tabella seguente.
Domanda |
Raccomandazione |
Spiegazione |
|---|---|---|
Vuoi migrare rapidamente senza riscrivere i dati mantenendo entrambe le tabelle Hive e Iceberg accessibili per test o transizioni graduali? |
|
Utilizzate la |
Stai usando Hive Metastore e vuoi sostituire immediatamente la tua tabella Hive con una tabella Iceberg, senza riscrivere i dati? |
|
Utilizzare la Nota: questa opzione è compatibile con Hive Metastore ma non con. AWS Glue Data Catalog Utilizzate la |
Stai usando AWS Glue Data Catalog e vuoi sostituire immediatamente la tua tabella Hive con una tabella Iceberg, senza riscrivere i dati? |
Adattamento della |
Replica il comportamento
Nota: questa opzione richiede la gestione manuale delle chiamate AWS Glue API per il backup dei metadati. Utilizzate la |
