Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Arricchimento semantico automatico per Serverless
Panoramica di
La funzionalità di arricchimento semantico automatico può contribuire a migliorare la pertinenza della ricerca fino al 20% rispetto alla ricerca lessicale. L'arricchimento semantico automatico elimina il peso indifferenziato della gestione dell'infrastruttura del modello ML (machine learning) e dell'integrazione con il motore di ricerca. La funzionalità è disponibile per tutti e tre i tipi di raccolta serverless: Search, Time Series e Vector.
Concetti di ricerca semantica
I motori di ricerca tradizionali si basano sulla corrispondenza parola per parola (denominata ricerca lessicale) per trovare risultati per le query. Sebbene funzioni bene per domande specifiche come i numeri di modello dei televisori, potrebbe non restituire risultati pertinenti per ricerche più astratte. Ad esempio, quando si cerca «scarpe per la spiaggia», una ricerca lessicale corrisponde semplicemente alle singole parole «scarpe», «spiaggia», «per» e «il» negli articoli del catalogo, e potenzialmente mancano prodotti pertinenti come «sandali impermeabili» o «calzature da surf» che non contengono i termini di ricerca esatti.
La ricerca semantica restituisce risultati di query che incorporano non solo la corrispondenza delle parole chiave, ma anche l'intento e il significato contestuale della ricerca dell'utente. Ad esempio, se un utente cerca «come curare un mal di testa», un sistema di ricerca semantico potrebbe restituire i seguenti risultati:
-
Rimedi contro l'emicrania
-
Tecniche di gestione del dolore
-
Over-the-counter antidolorifici
Dettagli del modello e benchmark delle prestazioni
Sebbene questa funzionalità gestisca le complessità tecniche dietro le quinte senza esporre il modello sottostante, la descrizione del modello e i risultati dei benchmark seguenti aiutano a prendere decisioni informate sull'adozione delle funzionalità nei carichi di lavoro critici.
L'arricchimento semantico automatico utilizza un modello sparso preaddestrato e gestito dai servizi che funziona in modo efficace senza richiedere una messa a punto personalizzata. Il modello analizza i campi specificati, espandendoli in vettori sparsi basati su associazioni apprese da diversi dati di addestramento. I termini estesi e i relativi pesi di significatività vengono archiviati nel formato di indice Lucene nativo per un recupero efficiente. Abbiamo ottimizzato questo processo utilizzando la modalità solo documento, in cui la codifica avviene solo
La convalida delle prestazioni durante lo sviluppo delle funzionalità ha utilizzato il set di dati di recupero dei passaggi MS MARCO
-
Lingua inglese - Miglioramento della pertinenza del 20% rispetto alla ricerca lessicale. Ha inoltre ridotto la latenza di ricerca P90 del 7,7% rispetto alla ricerca lessicale (BM25 è di 26 ms e l'arricchimento semantico automatico è di 24 ms).
-
Multi-lingual - Miglioramento della pertinenza del 105% rispetto alla ricerca lessicale, mentre la latenza di ricerca P90 è aumentata del 38,4% rispetto alla ricerca lessicale (BM25 è di 26 ms e l'arricchimento semantico automatico è di 36 ms).
Data la natura unica di ogni carico di lavoro, è possibile valutare questa funzionalità nel proprio ambiente di sviluppo utilizzando criteri di benchmarking personalizzati prima di prendere decisioni di implementazione.
Lingue supportate
La funzionalità supporta l'inglese. Inoltre, il modello supporta anche arabo, bengalese, cinese, finlandese, francese, hindi, indonesiano, giapponese, coreano, persiano, russo, spagnolo, swahili e telugu.
Imposta un indice di arricchimento semantico automatico per le raccolte serverless
Puoi configurare un indice con l'arricchimento semantico automatico abilitato per i campi di testo tramite la console, le API e CloudFormation i modelli durante la creazione di un nuovo indice. Per abilitarlo per un indice esistente, è necessario ricreare l'indice con l'arricchimento semantico automatico abilitato per i campi di testo.
Con la AWS console, puoi creare un indice con campi di arricchimento semantico automatico. Dopo aver selezionato una raccolta, puoi trovare il pulsante Crea indice nella parte superiore della console. Dopo aver scelto Crea indice, la console offre opzioni per definire campi di arricchimento semantico automatico. In un indice, puoi avere combinazioni di arricchimento semantico automatico per l'inglese e i campi multilingue, oltre che lessicali.
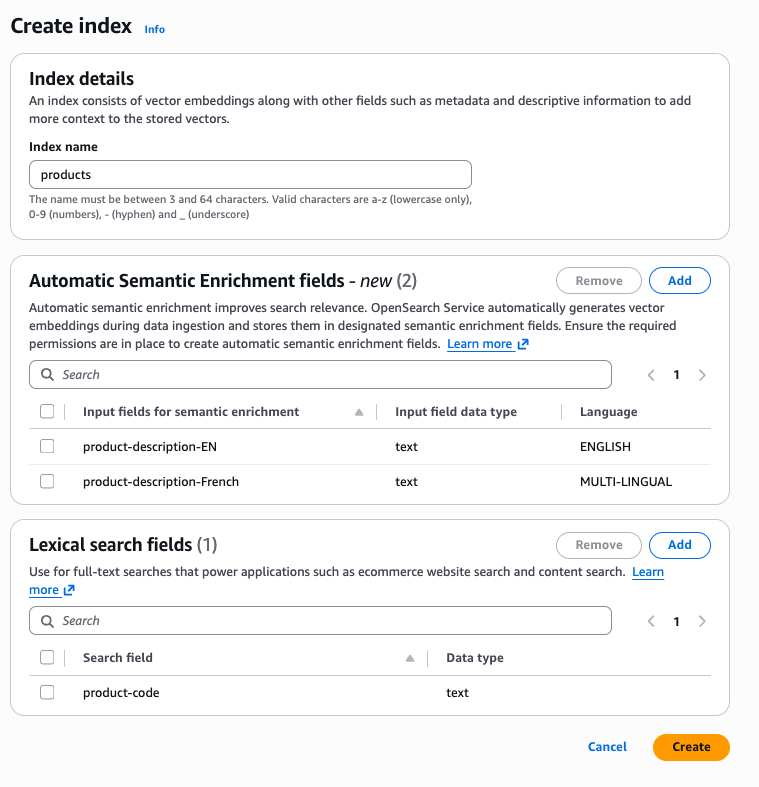
Per creare un indice di arricchimento semantico automatico utilizzando l'interfaccia a riga di AWS comando (AWS CLI), usa il comando create-index:
aws opensearchserverless create-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body] \
Nell'esempio seguente index-schema, il title_semantic campo ha un tipo di campo impostato su text e il parametro impostato su status. semantic_enrichment ENABLED L'impostazione del semantic_enrichment parametro consente l'arricchimento semantico automatico sul campo. title_semantic È possibile utilizzare il language_options campo per specificare uno oenglish. multi-lingual
aws opensearchserverless create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Per descrivere l'indice creato, utilizzate il seguente comando:
aws opensearchserverless get-index \ --id [collection_id] \ --index-name [index_name] \
È inoltre possibile utilizzare CloudFormation i modelli (Type:AWS::OpenSearchServerless::CollectionIndex) per creare una ricerca semantica durante il provisioning della raccolta e dopo la creazione della raccolta.
Aggiorna un indice esistente
È possibile aggiornare un indice esistente per aggiungere nuovi campi di arricchimento semantico, abilitare o disabilitare l'arricchimento semantico su campi esistenti o aggiungere campi di testo non semantici. Usa il update-index comando e fornisci solo i campi che desideri modificare in. index-schema I campi non inclusi nella richiesta vengono lasciati invariati.
Nota
L'indice settings non può essere aggiornato. Se includi un settings blocco nella richiesta, l'operazione restituisce un errore di convalida. Per modificare le impostazioni dell'indice, è necessario eliminare e ricreare l'indice.
Per aggiornare un indice utilizzando il AWS CLI, usa il update-index comando:
aws opensearchserverless update-index \ --id [collection_id] \ --index-name [index_name] \ --index-schema [index_body]
Aggiungi un nuovo campo di arricchimento semantico
È possibile aggiungere un nuovo text campo con arricchimento semantico abilitato a un indice esistente. Il servizio configura automaticamente il modello ML, la pipeline di importazione e la pipeline di ricerca richiesti. I nuovi documenti indicizzati dopo l'aggiornamento vengono arricchiti automaticamente.
Importante
I documenti esistenti non vengono riempiti. Per compilare il campo di arricchimento semantico sui documenti esistenti, è necessario reinserirli dopo l'aggiornamento. Fino a quando non verranno reinseriti, i documenti esistenti non trarranno vantaggio dalla ricerca semantica nel nuovo campo.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Disabilita l'arricchimento semantico su un campo
Per disabilitare l'arricchimento semantico su un campo in cui è attualmente abilitato, imposta su. status DISABLED Il campo viene rimosso dalle pipeline di acquisizione e ricerca. Il campo di testo sottostante e il relativo campo di incorporamento rimangono nell'indice ma non vengono più arricchiti.
aws opensearchserverless update-index \ --id my-collection-id \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Aggiorna le limitazioni
Le seguenti operazioni non sono supportate update-index e richiedono l'eliminazione e la ricreazione dell'indice:
-
Modifica
language_optionsin un campo su cui attualmente è abilitato l'arricchimento semantico. Disattiva prima il campo, quindi riattivalo con la nuova opzione di lingua. -
Aggiornamento dei campi annidati. L'arricchimento semantico è supportato solo nei campi di primo livello.
text -
Aggiornamento dell'indice.
settings
Nota
Se l'indice ha una pipeline di acquisizione o ricerca personalizzata che non è stata creata mediante l'arricchimento semantico automatico, l'operazione di aggiornamento è bloccata. Rimuovi la pipeline personalizzata prima di aggiungere campi di arricchimento semantico.
Inserimento e ricerca di dati
Dopo aver creato un indice con l'arricchimento semantico automatico abilitato, la funzionalità funziona automaticamente durante il processo di inserimento dei dati, senza bisogno di configurazioni aggiuntive.
Inserimento di dati: quando aggiungi documenti all'indice, il sistema automaticamente:
-
Analizza i campi di testo che hai designato per l'arricchimento semantico
-
Genera codifiche semantiche utilizzando il modello sparse gestito dal servizio OpenSearch
-
Memorizza queste rappresentazioni arricchite insieme ai dati originali
Questo processo utilizza i OpenSearch connettori ML e le pipeline di importazione integrati, che vengono creati e gestiti automaticamente dietro le quinte.
Ricerca: i dati di arricchimento semantico sono già indicizzati, quindi le query vengono eseguite in modo efficiente senza richiamare nuovamente il modello ML. Ciò significa che ottieni una maggiore pertinenza della ricerca senza alcun sovraccarico di latenza di ricerca aggiuntivo.
Configurazione delle autorizzazioni per l'arricchimento semantico automatico
Prima di creare un indice di arricchimento semantico automatico, è necessario configurare le autorizzazioni richieste. Questa sezione spiega le autorizzazioni necessarie e come configurarle.
Autorizzazioni della policy IAM
Utilizza la seguente policy AWS Identity and Access Management (IAM) per concedere le autorizzazioni necessarie per lavorare con l'arricchimento semantico automatico:
- Autorizzazioni chiave
-
-
Le
aoss:*Indexautorizzazioni consentono la gestione degli indici -
L'
aoss:APIAccessAllautorizzazione consente le operazioni OpenSearch dell'API -
Per limitare le autorizzazioni a una raccolta specifica, sostituiscile
"Resource": "*"con l'ARN della raccolta
-
Configura le autorizzazioni di accesso ai dati
Per configurare un indice per l'arricchimento semantico automatico, è necessario disporre di politiche di accesso ai dati appropriate che consentano l'accesso a risorse di indicizzazione, pipeline e raccolta di modelli. Per ulteriori informazioni sulle politiche di accesso ai dati, vedere. Controllo dell'accesso ai dati per Amazon OpenSearch Serverless Per la procedura di configurazione di una politica di accesso ai dati, vedereCreazione di policy di accesso ai dati (console).
Autorizzazioni di accesso ai dati
[ { "Description": "Create index permission", "Rules": [ { "ResourceType": "index", "Resource": ["index/collection_name/*"], "Permission": [ "aoss:CreateIndex", "aoss:DescribeIndex", "aoss:UpdateIndex", "aoss:DeleteIndex" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create pipeline permission", "Rules": [ { "ResourceType": "collection", "Resource": ["collection/collection_name"], "Permission": [ "aoss:CreateCollectionItems", "aoss:DescribeCollectionItems" ] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, { "Description": "Create model permission", "Rules": [ { "ResourceType": "model", "Resource": ["model/collection_name/*"], "Permission": ["aoss:CreateMLResource"] } ], "Principal": [ "arn:aws:iam::account_id:role/role_name" ] }, ]
Autorizzazioni di accesso alla rete
Per consentire alle API di servizio di accedere alle raccolte private, è necessario configurare politiche di rete che consentano l'accesso richiesto tra l'API del servizio e la raccolta. Per ulteriori informazioni sulle politiche di rete, consulta Accesso alla rete per Amazon OpenSearch Serverless.
[ { "Description":"Enable automatic semantic enrichment in a private collection", "Rules":[ { "ResourceType":"collection", "Resource":[ "collection/collection_name" ] } ], "AllowFromPublic":false, "SourceServices":[ "aoss.amazonaws.com" ], } ]
Per configurare le autorizzazioni di accesso alla rete per una raccolta privata
-
Accedi alla console di OpenSearch servizio all'indirizzo https://console.aws.amazon.com/aos/home
. -
Nel riquadro di navigazione a sinistra, scegli Politiche di rete. Poi esegui una delle seguenti operazioni:
-
Scegli il nome di una policy esistente e scegli Modifica
-
Scegli Crea politica di rete e configura i dettagli della politica
-
-
Nell'area Tipo di accesso, scegli Privato (consigliato), quindi seleziona Accesso privato al AWS servizio.
-
Nel campo di ricerca, scegli Servizio, quindi scegli aoss.amazonaws.com.
-
Nell'area Tipo di risorsa, seleziona la casella di controllo Abilita l'accesso all'endpoint. OpenSearch
-
Per Cerca raccolte o inserisci termini di prefisso specifici, nel campo di ricerca, seleziona Nome raccolta. Quindi inserisci o seleziona il nome delle raccolte da associare alla politica di rete.
-
Scegli Crea per una nuova politica di rete o Aggiorna per una politica di rete esistente.
Supportata Regioni AWS
L'arricchimento semantico automatico per OpenSearch Serverless è disponibile nelle seguenti versioni: Regioni AWS
Stati Uniti orientali (Virginia settentrionale)
Stati Uniti orientali (Ohio)
Stati Uniti occidentali (Oregon)
Asia Pacifico (Mumbai)
Asia Pacifico (Singapore)
Asia Pacifico (Sydney)
Asia Pacifico (Tokyo)
Europa (Francoforte)
Europa (Irlanda)
Europa (Stoccolma)
Europa (Spagna)
Riscritture delle query
L'arricchimento semantico automatico converte automaticamente le query «match» esistenti in query di ricerca semantiche senza richiedere modifiche alle query. Se una query di corrispondenza fa parte di una query composta, il sistema analizza la struttura delle query, trova le query di corrispondenza e le sostituisce con query sparse neurali. Attualmente, la funzionalità supporta solo la sostituzione delle query «match», indipendentemente dal fatto che si tratti di una query autonoma o di parte di una query composta. «multi_match» non è supportato. Inoltre, la funzionalità supporta tutte le query composte per sostituire le relative query di corrispondenza annidate. Le query composte includono: bool, boosting, constant_score, dis_max, function_score e hybrid.
Limitazioni dell'arricchimento semantico automatico
La ricerca semantica automatica è più efficace se applicata a campi di piccole e medie dimensioni contenenti contenuti in linguaggio naturale, come titoli di film, descrizioni di prodotti, recensioni e riassunti. Sebbene la ricerca semantica aumenti la pertinenza per la maggior parte dei casi d'uso, potrebbe non essere ottimale per determinati scenari. Considerate le seguenti limitazioni quando decidete se implementare l'arricchimento semantico automatico per il vostro caso d'uso specifico.
-
Documenti molto lunghi: l'attuale modello sparso elabora solo i primi 8.192 token di ogni documento in inglese. Per i documenti multilingue, sono 512 token. Per articoli lunghi, prendi in considerazione l'implementazione della suddivisione in blocchi dei documenti per garantire l'elaborazione completa dei contenuti.
-
Carichi di lavoro di analisi dei log: l'arricchimento semantico aumenta in modo significativo la dimensione dell'indice, il che potrebbe non essere necessario per l'analisi dei log, dove in genere è sufficiente una corrispondenza esatta. Il contesto semantico aggiuntivo raramente migliora l'efficacia della ricerca nei log abbastanza da giustificare i maggiori requisiti di archiviazione.
-
L'arricchimento semantico automatico non è compatibile con la funzionalità Derived Source.
Prezzi
Amazon OpenSearch Service fattura l'arricchimento semantico automatico in base alle unità di OpenSearch calcolo (OCU) utilizzate durante la generazione di vettori sparsi al momento dell'indicizzazione. Ti viene addebitato solo l'utilizzo effettivo durante l'indicizzazione dei campi di testo in cui hai abilitato l'arricchimento semantico automatico. One Semantic Search OCU può elaborare 11,1 milioni di token per contenuti in inglese. Per elaborare 2,4 miliardi di token, occorrono circa 216 Semantic Search OCU-hours (2,4 miliardi/11,10 milioni). Con un prezzo di 0,24 dollari per ricerca semantica OCU-hour, il costo per l'elaborazione di 10 GB di dati per la ricerca semantica automatica sarebbe di 51 dollari (216 x 0 dollari). OCU-hours 24/OCU-ora). Non sono previsti costi aggiuntivi per la ricerca semantica (OCU) durante le operazioni di ricerca o per l'archiviazione dei dati.
Puoi monitorare questo consumo utilizzando il CloudWatch parametro SemanticSearchOCU Amazon. Per dettagli specifici sui limiti dei token del modello, sul throughput di volume per OCU e un esempio di calcolo di esempio, visita OpenSearch Service Pricing.
