Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Cos'è Amazon OpenSearch Serverless?
Amazon OpenSearch Serverless è un'opzione serverless on-demand per Amazon OpenSearch Service che elimina la complessità operativa del provisioning, della configurazione e del tuning dei cluster. OpenSearch È ideale per le organizzazioni che preferiscono non gestire autonomamente i propri cluster o che non dispongono delle risorse e delle competenze dedicate per gestire implementazioni su larga scala. Con OpenSearch Serverless, puoi cercare e analizzare grandi volumi di dati senza gestire l'infrastruttura sottostante.
Una raccolta OpenSearch Serverless è un gruppo di OpenSearch indici che interagiscono per supportare un carico di lavoro o un caso d'uso specifici. Le raccolte semplificano le operazioni rispetto ai OpenSearch cluster autogestiti, che richiedono il provisioning manuale.
Le raccolte utilizzano lo stesso storage ad alta capacità, distribuito e ad alta disponibilità dei domini di OpenSearch servizio forniti, ma riducono ulteriormente la complessità eliminando la configurazione e l'ottimizzazione manuali. Tutte le comunicazioni con gli endpoint OpenSearch Serverless utilizzano la crittografia TLS 1.2, che garantisce la crittografia dei dati in transito dal client all'endpoint. I dati vengono inoltre crittografati durante il transito tra i componenti interni di una raccolta. OpenSearch Serverless supporta anche OpenSearch le dashboard, che forniscono un'interfaccia per l'analisi dei dati.
OpenSearch Serverless è compatibile con l'open source. OpenSearch Man mano che vengono rilasciate nuove versioni, OpenSearch Serverless aggiorna automaticamente le raccolte per incorporare nuove funzionalità, correzioni di bug e miglioramenti delle prestazioni.
OpenSearch Serverless supporta le stesse operazioni API di acquisizione e interrogazione della suite OpenSearch open source, in modo da poter continuare a utilizzare i client e le applicazioni esistenti. I tuoi client devono essere compatibili con OpenSearch 3.x per poter funzionare con Serverless. OpenSearch Per ulteriori informazioni, consulta Inserimento di dati in raccolte Amazon Serverless OpenSearch.
Argomenti
Casi d'uso per Serverless OpenSearch
OpenSearch Serverless supporta due casi d'uso principali:
-
Analisi dei log: l'opzione dell'analisi dei log si concentra sull'analisi di grandi volumi di dati di serie temporali semistrutturati generati da macchine per approfondimenti sull'aspetto operativo e sul comportamento degli utenti.
-
Full-text ricerca: il segmento di ricerca full-text supporta le applicazioni nelle reti interne (sistemi di gestione dei contenuti, documenti legali) e le applicazioni connesse a Internet, come la ricerca di contenuti nei siti di e-commerce.
Quando crei una raccolta, scegli uno di questi casi d'uso. Per ulteriori informazioni, consulta Scelta di un tipo di raccolta.
Come funziona
OpenSearch I cluster tradizionali dispongono di un unico set di istanze che eseguono sia operazioni di indicizzazione che di ricerca e lo storage degli indici è strettamente associato alla capacità di elaborazione. Al contrario, OpenSearch Serverless utilizza un'architettura nativa del cloud che separa i componenti di indicizzazione (inserimento) dai componenti di ricerca (query), con Amazon S3 come storage di dati principale per gli indici.
Questa architettura disaccoppiata consente di scalare le funzioni di ricerca e indicizzazione indipendentemente l'una dall'altra, e indipendentemente dai dati indicizzati in S3. Inoltre, l'architettura fornisce l'isolamento per le operazioni di importazione e interrogazione in modo che possano essere eseguite contemporaneamente, senza conflitti tra le risorse.
Quando scrivi dati su una raccolta, Serverless li distribuisce alle unità di calcolo di indicizzazione. OpenSearch Le unità di calcolo di indicizzazione importano i dati in entrata e spostano gli indici su S3. Quando si esegue una ricerca sui dati della raccolta, OpenSearch Serverless indirizza le richieste alle unità di calcolo di ricerca che contengono i dati interrogati. Le unità di calcolo di ricerca scaricano i dati indicizzati direttamente da S3 (se non sono già memorizzati nella cache locale), eseguono operazioni di ricerca ed effettuano aggregazioni.
L'immagine seguente illustra questa architettura disaccoppiata:
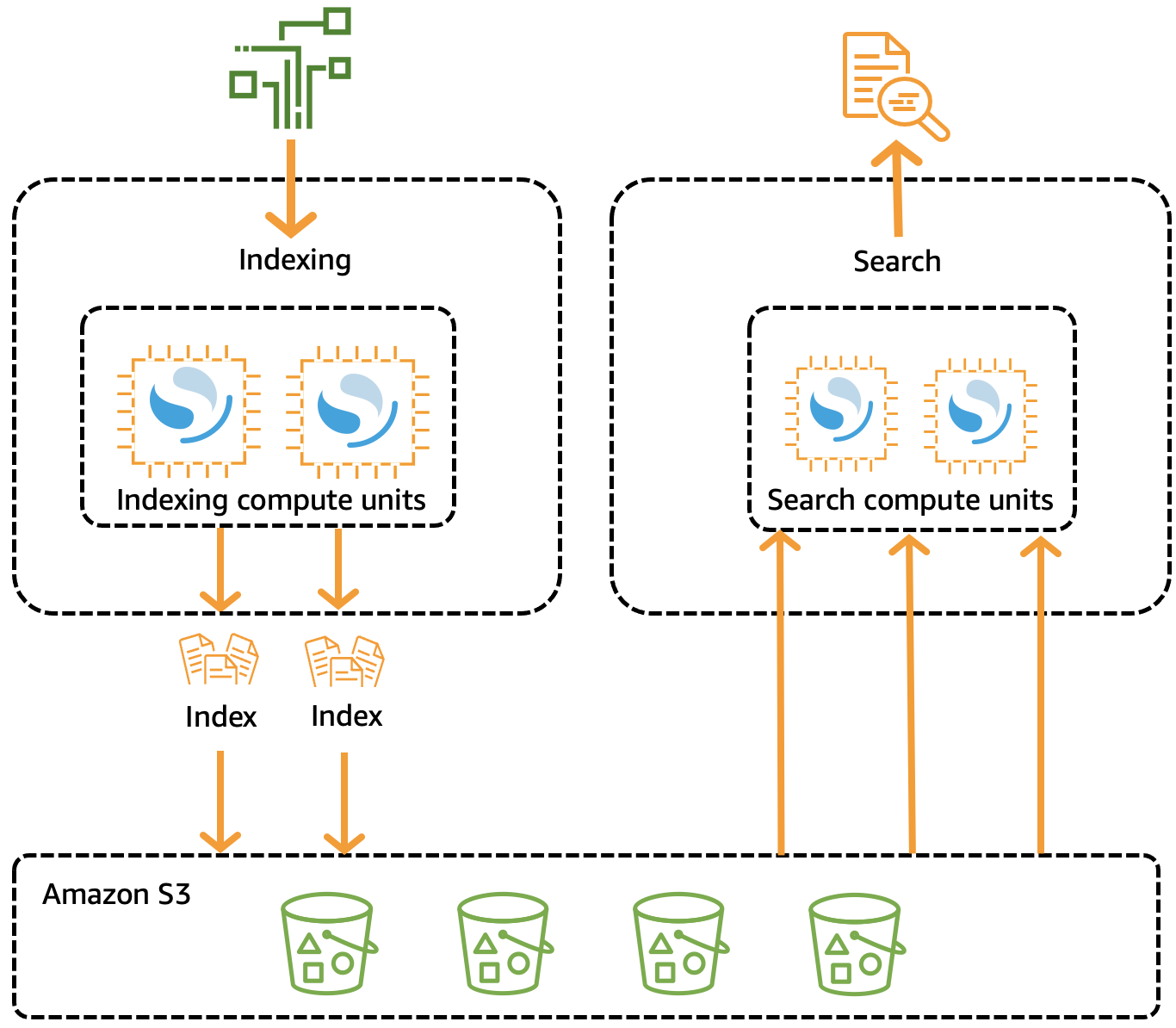
OpenSearch La capacità di elaborazione serverless per l'inserimento, la ricerca e l'interrogazione dei dati viene misurata in unità di calcolo (OCU). OpenSearch Ogni OCU è una combinazione di 6 GiB di memoria e della CPU virtuale (vCPU) corrispondente, oltre al trasferimento dei dati su Amazon S3.
OpenSearch Serverless fornisce le OCU separatamente per la ricerca e l'indicizzazione. OpenSearch Serverless aggiunge OCU aggiuntivi per la ricerca e l'inserimento solo se necessario per supportare le raccolte, in base ai limiti di capacità specificati. La capacità si riduce man mano che l'utilizzo del computer diminuisce.
Per informazioni su come ti vengono fatturati questi OCU, consulta i prezzi di Amazon OpenSearch Service
Scelta di un tipo di raccolta
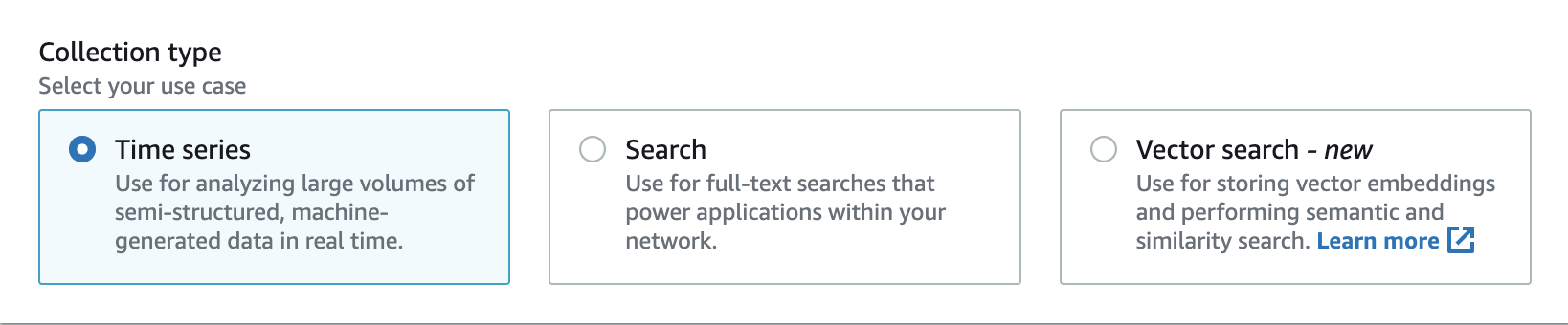
OpenSearch Serverless supporta tre tipi di raccolta principali:
Serie temporali: il segmento di analisi dei log che analizza grandi volumi di dati semistrutturati generati automaticamente in tempo reale, fornendo approfondimenti su operazioni, sicurezza, comportamento degli utenti e prestazioni aziendali.
Nota
Le raccolte di serie temporali sono disponibili solo per le raccolte Classic. NextGenle raccolte attualmente supportano solo i tipi di ricerca Search e Vector.
Ricerca: Full-text ricerca che abilita le applicazioni all'interno delle reti interne, come i sistemi di gestione dei contenuti e gli archivi di documenti legali, nonché le applicazioni connesse a Internet come la ricerca di siti di e-commerce e l'individuazione di contenuti.
Ricerca vettoriale: la ricerca semantica sugli incorporamenti vettoriali semplifica la gestione dei dati vettoriali e consente esperienze di ricerca aumentate basate sull'apprendimento automatico (ML). Supporta applicazioni di intelligenza artificiale generativa come chatbot, assistenti personali e rilevamento delle frodi.
Quando all'inizio crei una raccolta, scegli un tipo di raccolta:
Il tipo di raccolta scelto dipende dal tipo di dati che intendi importare nella raccolta e dal modo in cui intendi interrogarli. Non puoi modificare il tipo di raccolta dopo averla creata.
I tipi di raccolta presentano le seguenti differenze rilevanti:
-
Per le raccolte di ricerca e di ricerca vettoriale, tutti i dati vengono archiviati in hot storage per garantire tempi di risposta rapidi alle query. Le raccolte di serie temporali utilizzano una combinazione di archiviazione ad accesso frequente e a caldo, in cui i dati più recenti vengono conservati in un'archiviazione ad accesso frequente per ottimizzare i tempi di risposta alle interrogazioni per i dati a cui, come suggerisce il nome, si accede più frequentemente.
-
Per le raccolte di serie temporali, non è possibile indicizzarle in base a un ID di documento personalizzato o aggiornarle tramite richieste upsert. Questa operazione è riservata ai casi d'uso della ricerca. Puoi invece eseguire l'aggiornamento in base all'ID del documento. Per ulteriori informazioni, consulta Operazioni e autorizzazioni API supportate OpenSearch.
-
Per le raccolte di ricerche e serie temporali, non puoi utilizzare indici di tipo k-NN.
Supportata Regioni AWS
OpenSearch Serverless è disponibile in un sottoinsieme di Regioni AWS tale servizio è disponibile in. OpenSearch Per un elenco delle regioni supportate, consulta gli endpoint e le quote di Amazon OpenSearch Service nel. Riferimenti generali di AWS
Limitazioni
OpenSearch Serverless presenta le seguenti limitazioni:
-
Alcune operazioni OpenSearch API non sono supportate. Per informazioni, consulta Operazioni e autorizzazioni API supportate OpenSearch.
-
Alcuni OpenSearch plugin non sono supportati. Per informazioni, consulta OpenSearch Plugin supportati.
-
Al momento non è possibile migrare automaticamente i dati da un dominio di OpenSearch servizio gestito a una raccolta serverless. È necessario reindicizzare i dati da un dominio a una raccolta.
-
Cross-account l'accesso alle raccolte non è supportato. Non è possibile includere raccolte da altri account nelle tue policy di crittografia o accesso ai dati.
-
OpenSearch I plugin personalizzati non sono supportati.
-
Le istantanee automatiche sono supportate per le raccolte OpenSearch Serverless. Le istantanee manuali non sono supportate. Per ulteriori informazioni, consulta Backup delle raccolte tramite istantanee.
-
Cross-Region la ricerca e la replica non sono supportate.
-
Ci sono dei limiti al numero di risorse serverless di cui è possibile disporre in un singolo account e in una sola regione. Vedi OpenSearch Quote serverless.
-
L'intervallo di aggiornamento per gli indici nelle raccolte di ricerche e serie temporali è di circa 10 secondi.
-
Il numero di shard, il numero di intervalli e l'intervallo di aggiornamento non sono modificabili e vengono gestiti da Serverless. OpenSearch La strategia di sharding si basa sul tipo di raccolta e sul traffico. Ad esempio, una raccolta di serie temporali ridimensiona gli shard primari in base ai colli di bottiglia relativi al traffico di scrittura.
