Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tutorial: importazione di dati in un dominio utilizzando Amazon Ingestion OpenSearch
Questo tutorial mostra come usare Amazon OpenSearch Ingestion per configurare una pipeline semplice e inserire dati in un dominio Amazon Service. OpenSearch Una pipeline è una risorsa che OpenSearch Ingestion fornisce e gestisce. È possibile utilizzare una pipeline per filtrare, arricchire, trasformare, normalizzare e aggregare i dati per l'analisi e la visualizzazione a valle in Service. OpenSearch
Questo tutorial illustra i passaggi di base per avviare rapidamente una pipeline. Per istruzioni più complete, consultaCreazione di pipeline.
In questo tutorial completerai le seguenti fasi:
All'interno del tutorial, creerai le seguenti risorse:
-
Un dominio denominato su
ingestion-domaincui la pipeline scrive -
Una pipeline denominata
ingestion-pipeline
Autorizzazioni richieste
Per completare questo tutorial, l'utente o il ruolo deve avere una politica basata sull'identità allegata con le seguenti autorizzazioni minime. Queste autorizzazioni consentono di creare un ruolo di pipeline e allegare una policy (iam:Create*eiam:Attach*), creare o modificare un dominio () e lavorare con es:* pipelines (). osis:*
Fase 1: Creare il ruolo della pipeline
Innanzitutto, crea un ruolo che la pipeline assumerà per accedere al OpenSearch service domain sink. Includerai questo ruolo nella configurazione della pipeline più avanti in questo tutorial.
Per creare il ruolo della pipeline
-
Apri la AWS Identity and Access Management console all'indirizzo https://console.aws.amazon.com/iamv2/
. -
Scegli Politiche, quindi scegli Crea politica.
-
In questo tutorial, inserirai i dati in un dominio chiamato
ingestion-domain, che creerai nel passaggio successivo. Seleziona JSON e incolla la seguente politica nell'editor. Sostituisciloyour-account-idSe desideri scrivere dati su un dominio esistente, sostituiscili
ingestion-domaincon il nome del tuo dominio.Nota
Per semplicità in questo tutorial, utilizziamo un'ampia politica di accesso. Negli ambienti di produzione, tuttavia, ti consigliamo di applicare una politica di accesso più restrittiva al tuo ruolo di pipeline. Per un esempio di policy che fornisce le autorizzazioni minime richieste, vedi. Concedere alle pipeline OpenSearch di Amazon Ingestion l'accesso ai domini
-
Scegliete Avanti, scegliete Avanti e assegnate un nome alla vostra policy pipeline-policy.
-
Scegli Crea policy.
-
Quindi, crea un ruolo e allega la policy ad esso. Selezionare Roles (Ruoli), quindi selezionare Create role (Crea ruolo).
-
Scegli una politica di fiducia personalizzata e incolla la seguente politica nell'editor:
-
Scegli Next (Successivo). Quindi cerca e seleziona pipeline-policy (che hai appena creato).
-
Scegli Avanti e assegna un nome al ruolo. PipelineRole
-
Scegli Crea ruolo.
Ricorda l'Amazon Resource Name (ARN) del ruolo (ad esempio,arn:aws:iam::). Ne avrai bisogno quando creerai la tua pipeline.your-account-id:role/PipelineRole
Passaggio 2: crea un dominio
Innanzitutto, crea un dominio denominato in ingestion-domain cui inserire i dati.
Accedi alla console di Amazon OpenSearch Service da https://console.aws.amazon.com/aos/casa
-
È in esecuzione OpenSearch 1.0 o versione successiva oppure Elasticsearch 7.4 o versione successiva
-
Utilizza l'accesso pubblico
-
Non utilizza un controllo degli accessi a grana fine
Nota
Questi requisiti hanno lo scopo di garantire la semplicità di questo tutorial. Negli ambienti di produzione, puoi configurare un dominio con accesso VPC utilizzando un controllo degli and/or accessi granulare. Per utilizzare un controllo granulare degli accessi, consulta Mappare il ruolo della pipeline.
Il dominio deve avere una politica di accesso che conceda l'autorizzazione al ruolo OpenSearchIngestion-PipelineRole IAM, che OpenSearch Service creerà per te nella fase successiva. La pipeline assumerà questo ruolo per inviare i dati al domain sink.
Assicurati che il dominio abbia la seguente politica di accesso a livello di dominio, che concede al ruolo della pipeline l'accesso al dominio. Sostituisci la regione e l'ID dell'account con i tuoi:
Per ulteriori informazioni sulla creazione di politiche di accesso a livello di dominio, consulta. Policy basate sulle risorse
Se hai già creato un dominio, modifica la politica di accesso esistente per fornire le autorizzazioni di cui sopra. OpenSearchIngestion-PipelineRole
Fase 3: Creare una pipeline
Ora che hai un dominio, puoi creare una pipeline.
Come creare una pipeline
-
Nella console di Amazon OpenSearch Service, scegli Pipelines dal riquadro di navigazione a sinistra.
-
Scegliere Create pipeline (Crea pipeline).
-
Seleziona la pipeline vuota, quindi scegli Seleziona blueprint.
-
In questo tutorial, creeremo una semplice pipeline che utilizza il plug-in di origine HTTP
. Il plugin accetta i dati di registro in un formato di matrice JSON. Specificheremo un singolo dominio di OpenSearch servizio come sink e inseriremo tutti i dati nell' application_logsindice.Nel menu Sorgente, scegli HTTP. Per il percorso, inserisci /logs.
-
Per semplicità, in questo tutorial, configureremo l'accesso pubblico alla pipeline. Per le opzioni di rete di origine, scegli Accesso pubblico. Per informazioni sulla configurazione dell'accesso al VPC, vedere. Configurazione dell'accesso VPC per le pipeline di Amazon Ingestion OpenSearch
-
Scegli Next (Successivo).
-
Per Processore, inserisci Data e scegli Aggiungi.
-
Abilita A partire dall'ora di ricezione. Lascia tutte le altre impostazioni come predefinite.
-
Scegli Next (Successivo).
-
Configura i dettagli del lavandino. Per il tipo di OpenSearch risorsa, scegli Cluster gestito. Quindi scegli il dominio di OpenSearch servizio che hai creato nella sezione precedente.
Per il nome dell'indice, inserisci application_logs. OpenSearch Ingestion crea automaticamente questo indice nel dominio se non esiste già.
-
Scegli Next (Successivo).
-
Assegna un nome alla pipeline di ingestione-pipeline. Lasciate le impostazioni di capacità come predefinite.
-
Per il ruolo Pipeline, seleziona Crea e usa un nuovo ruolo di servizio. Il ruolo pipeline fornisce le autorizzazioni necessarie affinché una pipeline possa scrivere nel domain sink e leggere da fonti basate su pull. Selezionando questa opzione, OpenSearch consenti a Ingestion di creare il ruolo per te, anziché crearlo manualmente in IAM. Per ulteriori informazioni, consulta Configurazione di ruoli e utenti in Amazon OpenSearch Ingestion.
-
Per il suffisso del nome del ruolo di servizio, immettere. PipelineRole In IAM, il ruolo avrà il seguente formato
arn:aws:iam::.your-account-id:role/OpenSearchIngestion-PipelineRole -
Scegli Next (Successivo). Controlla la configurazione della pipeline e scegli Crea pipeline. La pipeline impiega 5-10 minuti per diventare attiva.
Fase 4: Inserimento di alcuni dati di esempio
Quando lo stato della pipeline è impostatoActive, puoi iniziare a importare i dati al suo interno. È necessario firmare tutte le richieste HTTP alla pipeline utilizzando Signature Version 4. Utilizza uno strumento HTTP come Postman
Nota
Il principale che firma la richiesta deve disporre dell'autorizzazione IAM. osis:Ingest
Innanzitutto, ottieni l'URL di importazione dalla pagina delle impostazioni di Pipeline:
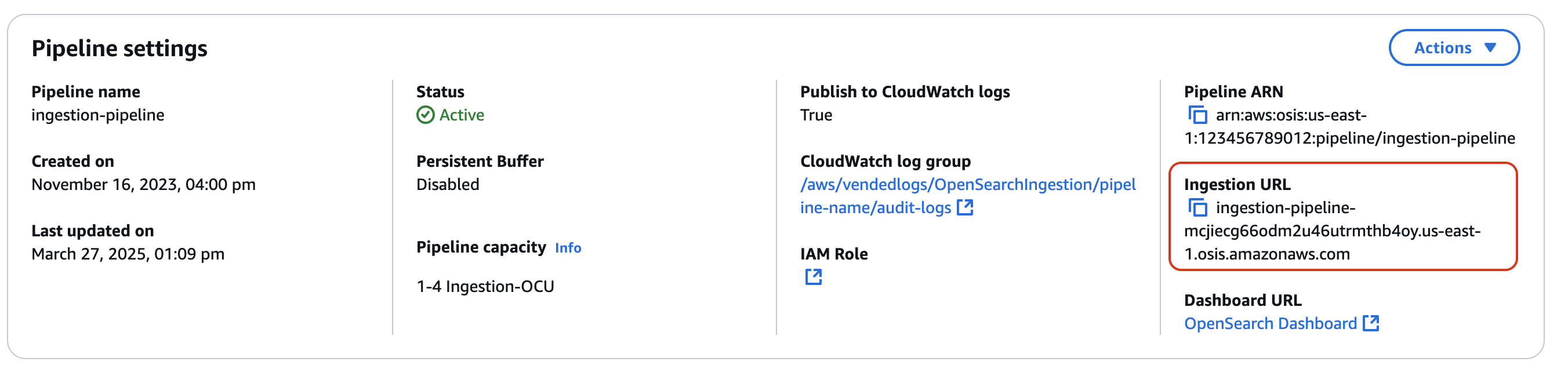
Quindi, inserisci alcuni dati di esempio. La seguente richiesta utilizza awscurl
awscurl --service osis --regionus-east-1\ -X POST \ -H "Content-Type: application/json" \ -d '[{"time":"2014-08-11T11:40:13+00:00","remote_addr":"122.226.223.69","status":"404","request":"GET http://www.k2proxy.com//hello.html HTTP/1.1","http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)"}]' \ https://pipeline-endpoint.us-east-1.osis.amazonaws.com/logs
Dovresti vedere una risposta. 200 OK Se ricevi un errore di autenticazione, potrebbe essere dovuto al fatto che stai importando dati da un account diverso da quello in cui si trova la pipeline. Per informazioni, consulta Risoluzione dei problemi relativi alle autorizzazioni.
Ora, interroga l'application_logsindice per assicurarti che la voce di registro sia stata inserita correttamente:
awscurl --service es --regionus-east-1\ -X GET \ https://search-ingestion-domain.us-east-1.es.amazonaws.com/application_logs/_search | json_pp
Esempio di risposta:
{ "took":984, "timed_out":false, "_shards":{ "total":1, "successful":5, "skipped":0, "failed":0 }, "hits":{ "total":{ "value":1, "relation":"eq" }, "max_score":1.0, "hits":[ { "_index":"application_logs", "_type":"_doc", "_id":"z6VY_IMBRpceX-DU6V4O", "_score":1.0, "_source":{ "time":"2014-08-11T11:40:13+00:00", "remote_addr":"122.226.223.69", "status":"404", "request":"GET http://www.k2proxy.com//hello.html HTTP/1.1", "http_user_agent":"Mozilla/4.0 (compatible; WOW64; SLCC2;)", "@timestamp":"2022-10-21T21:00:25.502Z" } } ] } }
Risoluzione dei problemi relativi alle autorizzazioni
Se hai seguito i passaggi del tutorial e continui a riscontrare errori di autenticazione quando tenti di importare dati, è possibile che il ruolo della scrittura in una pipeline sia Account AWS diverso da quello della pipeline stessa. In questo caso, devi creare e assumere un ruolo che ti consenta specificamente di importare dati. Per istruzioni, consulta Fornire l'accesso all'importazione su più account.
Risorse correlate
Questo tutorial ha presentato un semplice caso d'uso di ingestione di un singolo documento tramite HTTP. Negli scenari di produzione, configurerai le tue applicazioni client (come Fluent Bit, Kubernetes o OpenTelemetry Collector) per inviare dati a una o più pipeline. Le tue pipeline saranno probabilmente più complesse del semplice esempio di questo tutorial.
Per iniziare a configurare i client e ad acquisire dati, consulta le seguenti risorse:
