Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Tecniche di creazione di prompt per la comprensione della visione
Nota
Questa documentazione è per Amazon Nova versione 1. Per informazioni su come promuovere la comprensione multimodale in Amazon Nova 2, visita Richiesta di input multimodali.
Le seguenti tecniche di creazione di prompt per la visione ti aiuteranno a creare prompt migliori per Amazon Nova.
Il posizionamento è importante
Ti consigliamo di inserire file multimediali (come immagini o video) prima di aggiungere qualsiasi documento, seguiti dal testo delle istruzioni o dai prompt per guidare il modello. Sebbene le immagini posizionate dopo il testo o intervallate da testo continuino a funzionare in modo adeguato, se il caso d’uso lo consente, l’approccio preferito è la struttura {media_file}-then-{text}.
Il seguente modello può essere utilizzato per posizionare i file multimediali prima del testo durante la comprensione visiva.
{ "role": "user", "content": [ { "image": "..." }, { "video": "..." }, { "document": "..." }, { "text": "..." } ] }
Nessuna struttura seguita |
Prompt ottimizzato |
|
|---|---|---|
Utente |
Spiega cosa sta succedendo nell’immagine [Image1.png] |
[Image1.png] Spiega cosa sta succedendo nell’immagine? |
Più file multimediali con componenti visivi
In situazioni in cui fornisci più file multimediali fra i turni, introduci ogni immagine con un’etichetta numerata. Ad esempio, se utilizzi due immagini, etichettale Image
1: e Image 2:. Se usi tre video, etichettali con Video
1:, Video 2: e Video 3:. Non sono necessarie nuove righe tra le immagini o tra le immagini e il prompt.
Il seguente modello può essere utilizzato per inserire più file multimediali:
messages = [ { "role": "user", "content": [ {"text":"Image 1:"}, {"image": {"format": "jpeg", "source": {"bytes": img_1_base64}}}, {"text":"Image 2:"}, {"image": {"format": "jpeg", "source": {"bytes": img_2_base64}}}, {"text":"Image 3:"}, {"image": {"format": "jpeg", "source": {"bytes": img_3_base64}}}, {"text":"Image 4:"}, {"image": {"format": "jpeg", "source": {"bytes": img_4_base64}}}, {"text":"Image 5:"}, {"image": {"format": "jpeg", "source": {"bytes": img_5_base64}}}, {"text":user_prompt}, ], } ]
Prompt non ottimizzato |
Prompt ottimizzato |
|---|---|
|
Descrivi ciò che vedi nella seconda immagine. [Image1.png] [Image2.png] |
[Image1.png] [Image2.png] Descrivi ciò che vedi nella seconda immagine. |
|
La seconda immagine è descritta nel documento incluso? [Image1.png] [Image2.png] [Document1.pdf] |
[Image1.png] [Image2.png] [Document1.pdf] La seconda immagine è descritta nel documento incluso? |
A causa dei lunghi token contestuali dei tipi di file multimediale, il prompt di sistema indicato all’inizio del prompt potrebbe non essere rispettato in alcune occasioni. In questa occasione, ti consigliamo di spostare le istruzioni di sistema ai turni degli utenti e di seguire le indicazioni generali di {media_file}-then-{text}. Ciò non influisce sulla creazione di prompt di sistema con RAG, sugli agenti o sull’utilizzo degli strumenti.
Utilizza le istruzioni per l’utente per seguire meglio le istruzioni per le attività di comprensione visiva
Per la comprensione dei video, il numero di token nel contesto rende molto importanti i suggerimenti in Il posizionamento è importante. Usa il prompt di sistema per aspetti più generali come tono e stile. Ti consigliamo di conservare le istruzioni relative al video come parte del prompt dell’utente per migliorare le prestazioni.
Il seguente modello può essere utilizzato per migliorare le istruzioni:
{ "role": "user", "content": [ { "video": { "format": "mp4", "source": { ... } } }, { "text": "You are an expert in recipe videos. Describe this video in less than 200 words following these guidelines: ..." } ] }
Proprio come per il testo, consigliamo di richiedere immagini e video chain-of-thought per ottenere prestazioni migliori. Si consiglia inoltre di inserire le chain-of-thought direttive nel prompt di sistema, mantenendo le altre istruzioni nel prompt dell'utente.
Importante
Il modello Amazon Nova Premier è un modello di intelligenza superiore della famiglia Amazon Nova che è in grado di gestire attività più complesse. Se le tue attività richiedono un chain-of-thought pensiero avanzato, ti consigliamo di utilizzare il modello di prompt fornito in Dai ad Amazon Nova il tempo di pensare () chain-of-thought. Questo approccio può aiutare a migliorare le capacità di analisi e risoluzione dei problemi del modello.
Pochi esempi di riprese
Proprio come per i modelli di testo, ti consigliamo di fornire esempi di immagini per migliorare le prestazioni di comprensione delle immagini (non è possibile fornire esempi di video, a causa della limitazione). single-video-per-inference Ti consigliamo di inserire gli esempi nel prompt dell’utente, dopo il file multimediale, anziché fornirli nel prompt di sistema.
| 0 colpi | 2 colpi | |
|---|---|---|
| Utente | [Immagine 1] | |
| Assistente | La descrizione dell'immagine 1 | |
| Utente | [Immagine 2] | |
| Assistente | La descrizione dell'immagine 2 | |
| Utente | [Image 3] Spiega cosa sta succedendo nell’immagine |
[Image 3] Spiega cosa sta succedendo nell’immagine |
Rilevamento del riquadro di delimitazione
Se devi identificare le coordinate del riquadro di delimitazione per un oggetto, puoi utilizzare il modello Amazon Nova per generare riquadri di delimitazione su una scala di [0, 1.000). Dopo aver ottenuto queste coordinate, puoi ridimensionarle in base alle dimensioni dell’immagine come fase di post-elaborazione. Per informazioni più dettagliate su come svolgere questa fase di post-elaborazione, consulta il notebook Amazon Nova Image Grounding
Di seguito è riportato un esempio di prompt per il rilevamento del riquadro di delimitazione:
Detect bounding box of objects in the image, only detect {item_name} category objects with high confidence, output in a list of bounding box format. Output example: [ {"{item_name}": [x1, y1, x2, y2]}, ... ] Result:
Stile o output più ricchi
L’output di comprensione dei video può essere molto breve. Se desideri output più lunghi, ti consigliamo di creare un utente tipo per il modello. Puoi fare in modo che questo utente tipo risponda nel modo desiderato, come se utilizzasse il ruolo di sistema.
È possibile apportare ulteriori modifiche alle risposte con tecniche one-shot e few-shot. Fornisci esempi di come dovrebbe essere una buona risposta e il modello può imitarne alcuni aspetti durante la generazione delle risposte.
Estrai il contenuto del documento in Markdown
Amazon Nova Premier dimostra funzionalità avanzate per comprendere i grafici incorporati nei documenti e la capacità di leggere e comprendere i contenuti di domini complessi come gli articoli scientifici. Inoltre, Amazon Nova Premier mostra prestazioni migliorate nell’estrazione dei contenuti dei documenti e può emettere queste informazioni nei formati Markdown Table e Latex.
L’esempio seguente fornisce una tabella in un’immagine, insieme a un prompt per Amazon Nova Premier per convertire il contenuto dell’immagine in una tabella Markdown. Dopo aver creato il Markdown (o Latex Representation), puoi utilizzare strumenti per convertire il contenuto in JSON o altro output strutturato.
Make a table representation in Markdown of the image provided.
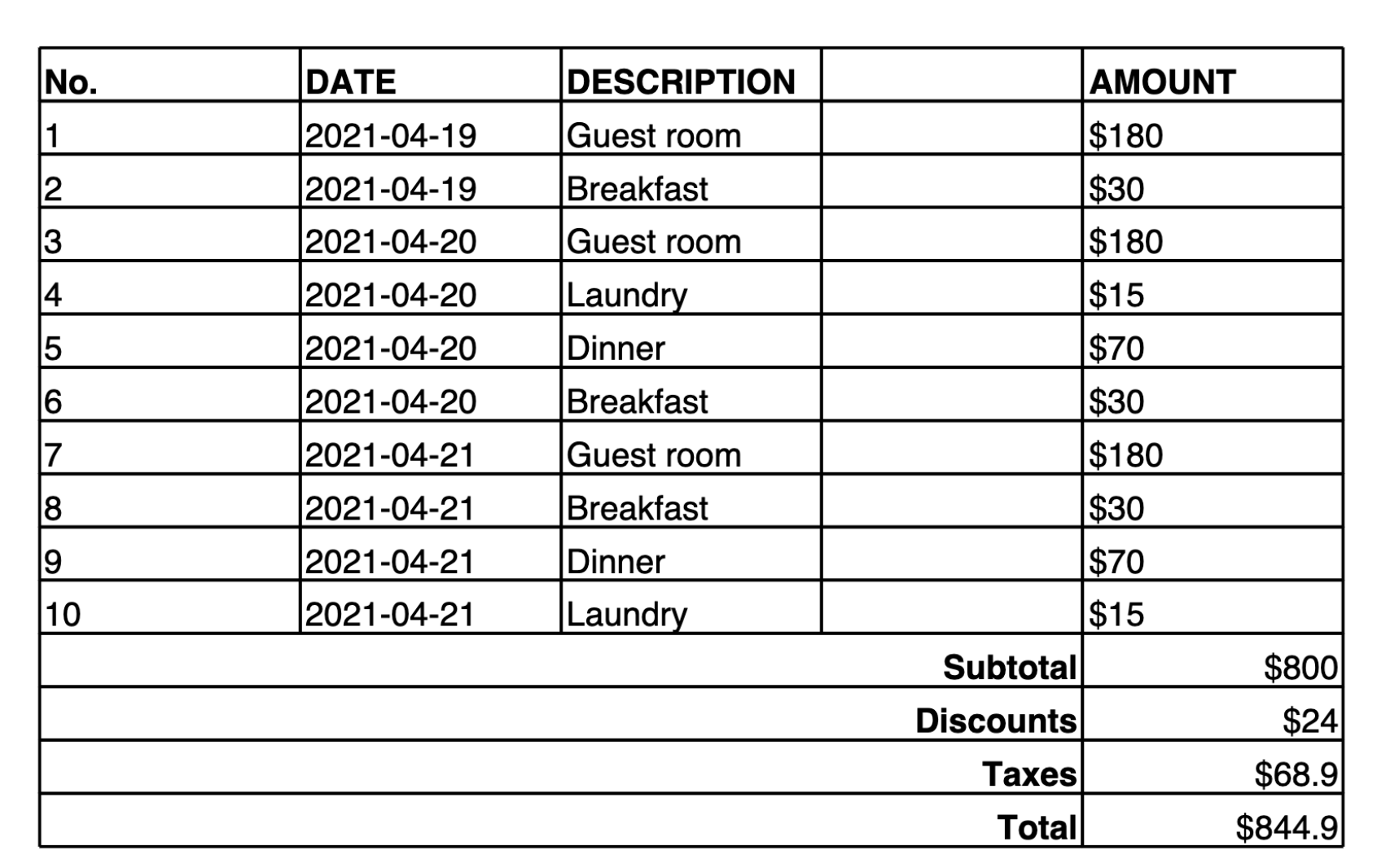
Di seguito è riportato l’output fornito dal modello:
| No. | DATE | DESCRIPTION | AMOUNT | |-----|------------|-------------|--------| | 1 | 2021-04-19 | Guest room | $180 | | 2 | 2021-04-19 | Breakfast | $30 | | 3 | 2021-04-20 | Guest room | $180 | | 4 | 2021-04-20 | Laundry | $15 | | 5 | 2021-04-20 | Dinner | $70 | | 6 | 2021-04-20 | Breakfast | $30 | | 7 | 2021-04-21 | Guest room | $180 | | 8 | 2021-04-21 | Breakfast | $30 | | 9 | 2021-04-21 | Dinner | $70 | | 10 | 2021-04-21 | Laundry | $15 | | | | Subtotal | $800 | | | | Discounts | $24 | | | | Taxes | $68.9 | | | | Total | $844.9 |
Questo output utilizza una notazione di tabella personalizzata in cui || viene utilizzato come separatore di colonna e && viene utilizzato come separatore di riga.
Impostazioni dei parametri di inferenza per la comprensione visiva
Per i casi d’uso relativi alla comprensione visiva, ti consigliamo di iniziare con i parametri di inferenza temperature impostati su 0 e topK impostati su 1. Dopo aver osservato l’output del modello, potrai quindi regolare i parametri di inferenza in base al caso d’uso. Solitamente, questi valori dipendono dall’attività e dalla varianza richiesta. Aumenta l’impostazione della temperatura per indurre più variazioni nelle risposte.
Classificazione video
Per ordinare efficacemente i contenuti video in categorie appropriate, fornisci categorie che il modello può utilizzare per la classificazione. Esamina il seguente prompt di esempio:
[Video] Which category would best fit this video? Choose an option from the list below: \Education\Film & Animation\Sports\Comedy\News & Politics\Travel & Events\Entertainment\Trailers\How-to & Style\Pets & Animals\Gaming\Nonprofits & Activism\People & Blogs\Music\Science & Technology\Autos & Vehicles
Taggare i video
Amazon Nova Premier presenta funzionalità migliorate per la creazione di tag video. Per ottenere risultati ottimali, usa la seguente istruzione per richiedere i tag separati da virgole: “Usa le virgole per separare ogni tag”. Di seguito è riportato un prompt di esempio:
[video] "Can you list the relevant tags for this video? Use commas to separate each tag."
Sottotitoli dettagliati dei video
Amazon Nova Premier dimostra funzionalità avanzate per fornire sottotitoli dettagliati, ossia descrizioni testuali approfondite generate per più segmenti all’interno del video. Di seguito è riportato un prompt di esempio:
[Video] Generate a comprehensive caption that covers all major events and visual elements in the video.
