AWS Il servizio di modernizzazione del mainframe (esperienza Managed Runtime Environment) non è più aperto a nuovi clienti. Per funzionalità simili a AWS Mainframe Modernization Service (esperienza Managed Runtime Environment), esplora AWS Mainframe Modernization Service (Experience). Self-Managed I clienti esistenti possono continuare a utilizzare il servizio normalmente. Per ulteriori informazioni, consulta Modifica della disponibilità di AWS Mainframe Modernization.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Endpoint per l'applicazione Gapwalk in AWS Transform for mainframe
In questo argomento, scopri gli endpoint per l'applicazione web Gapwalk. Questi utilizzano il percorso principale. /gapwalk-application
Argomenti
Endpoint correlati ai job Batch (modernizzati JCLs e simili)
I processi Batch possono essere eseguiti in modo sincrono o asincrono (vedere i dettagli di seguito). I processi Batch vengono eseguiti utilizzando script groovy che sono il risultato della modernizzazione degli script legacy (JCL).
Argomenti
Elenca gli script distribuiti
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/scripts -
Argomenti: nessuno
-
Questo endpoint restituisce l'elenco degli script groovy distribuiti sul server, come stringa. Questo endpoint è destinato principalmente all'uso da un browser Web, poiché la String risultante è una pagina HTML, con collegamenti attivi (un collegamento per script avviabile - vedi esempio di seguito).
Risposta di esempio:
<p><a href=./script/COMBTRAN>COMBTRAN</a></p><p><a href=./script/CREASTMT>CREASTMT</a></p><p><a href=./script/INTCALC>INTCALC</a></p><p><a href=./script/POSTTRAN>POSTTRAN</a></p><p><a href=./script/REPROC>REPROC</a></p><p><a href=./script/TRANBKP>TRANBKP</a></p><p><a href=./script/TRANREPT>TRANREPT</a></p><p><a href=./script/functions>functions</a></p>
Nota
I collegamenti rappresentano l'URL da utilizzare per avviare ogni script elencato in modo sincrono.
-
Metodo supportato: GET/POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/triggerscripts -
Argomenti: nessuno
-
Questo endpoint restituisce l'elenco degli script groovy distribuiti sul server, come stringa. Questo endpoint è destinato principalmente all'uso da un browser Web, poiché la String risultante è una pagina HTML, con collegamenti attivi (un collegamento per script avviabile - vedi esempio di seguito).
A differenza della precedente risposta dell'endpoint, i link rappresentano l'URL da utilizzare per avviare ogni script elencato in modo asincrono.
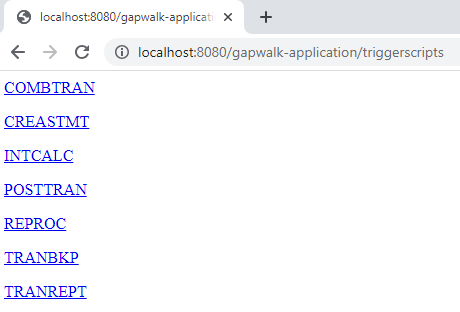
Avvia uno script in modo sincrono
Questo endpoint ha due varianti con percorsi dedicati per l'utilizzo di GET e POST (vedi sotto).
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/script/{scriptId:.+} -
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/post/script/{scriptId:.+} -
Argomenti:
-
identificatore dello script per avviare la convalida dell'input: l'ID dello script non deve essere vuoto, non può superare i 255 caratteri e deve corrispondere allo schema:
^[a-zA-Z0-9._-]+$ -
opzionalmente: parametri da passare allo script, utilizzando i parametri di richiesta (visti come a).
Map<String,String>I parametri forniti verranno aggiunti automaticamente ai collegamenti dello script groovyinvocato. Convalida dell'input: la mappa dei parametri non può superare le 50 voci.
-
-
La chiamata esegue lo script (identificato da scriptID) con parametri opzionali e attende il completamento prima di restituire uno con:
ResponseEntityString-
HTTP 200: «Fatto». o messaggio di successo JSON in caso di esecuzione riuscita
-
HTTP 200: un messaggio di errore JSON con dettagli sull'errore di esecuzione. Informazioni aggiuntive disponibili nei log del server.
Nota
Runtime ora supporta la restituzione del codice di stato HTTP 500 per le esecuzioni di job non riuscite. Vedi Proprietà disponibili per l'applicazione principale per configurare questo codice di risposta.
-
Convalida dell'input: l'ID o i parametri dello script non validi restituiranno HTTP 400 Bad Request con i dettagli dell'errore di convalida.
{ "exitCode": -1, "stepName": "STEP15", "program": "CBACT04C", "status": "Error" }Guardando i log del server, possiamo capire che si tratta di un problema di distribuzione (il programma previsto non è stato distribuito correttamente, quindi non può essere trovato, il che rende impossibile l'esecuzione del lavoro):

-
Nota
Le chiamate sincrone devono essere riservate ai lavori di breve durata. I lavori con esecuzione prolungata dovrebbero invece essere avviati in modo asincrono (vedi endpoint dedicato di seguito).
Avvia uno script in modo asincrono
-
Metodi supportati: GET/POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/triggerscript/{scriptId:.+} -
Argomenti:
-
identificatore dello script per avviare la convalida dell'input: l'ID dello script non deve essere vuoto, non può superare i 255 caratteri e deve corrispondere allo schema:
^[a-zA-Z0-9._-]+$ -
opzionalmente: parametri da passare allo script, utilizzando i parametri di richiesta (visti come a).
Map<String,String>I parametri forniti verranno aggiunti automaticamente ai collegamenti dello script groovyinvocato. Convalida dell'input: la mappa dei parametri non può superare le 50 voci.
-
-
A differenza della modalità sincrona descritta in precedenza, l'endpoint non attende il completamento dell'esecuzione del job per inviare una risposta. L'esecuzione del processo viene avviata immediatamente, se è possibile trovare un thread disponibile in tal senso, e al chiamante viene inviata immediatamente una risposta con l'ID di esecuzione del lavoro, un identificatore univoco che rappresenta l'esecuzione del lavoro, che può essere utilizzato per interrogare lo stato di esecuzione del lavoro o forzare l'interruzione di un'esecuzione del lavoro che si suppone non funzioni correttamente. Il formato della risposta è:
Triggered script <script identifier> [unique job execution id] @ <date and time> -
Poiché l'esecuzione asincrona del processo si basa su un numero fisso limitato di thread, l'esecuzione del lavoro potrebbe non essere avviata se non viene trovato alcun thread disponibile. In tal caso, il messaggio restituito sarà piuttosto simile a:
Script [<script identifier>] NOT triggered - Thread limit reached (<actual thread limit>) - Please retry later or increase thread limit.Vedi l'
settriggerthreadlimitendpoint qui sotto per scoprire come aumentare il limite dei thread.
Risposta di esempio:
Triggered script INTCALC [d43cbf46-4255-4ce2-aac2-79137573a8b4] @ 06-12-2023 16:26:15
L'identificatore univoco di esecuzione del lavoro consente di recuperare rapidamente le voci di registro correlate nei log del server, se necessario. Viene utilizzato anche da diversi altri endpoint descritti di seguito.
Elenco degli script attivati
-
Metodi supportati: GET/POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorsi:,
/triggeredscripts/{status:.+}/triggeredscripts/{status:.+}/{namefilter} -
Argomenti:
-
Status (obbligatorio): lo stato degli script attivati da recuperare. Convalida dell'input: lo stato non deve essere vuoto e non può superare i 50 caratteri. I valori possibili sono:
-
all: mostra tutti i dettagli sull'esecuzione del lavoro, indipendentemente dal fatto che i lavori siano ancora in esecuzione o meno. -
running: mostra solo i dettagli dei lavori attualmente in esecuzione. -
done: mostra i dettagli dei lavori solo per i lavori la cui esecuzione è terminata. -
killed: mostra i dettagli dei lavori solo per i lavori la cui esecuzione è stata interrotta forzatamente utilizzando l'endpoint dedicato (vedi sotto). -
triggered: mostra solo i dettagli dei lavori che sono stati attivati ma non ancora avviati. -
failed: mostra i dettagli dei lavori solo per i lavori la cui esecuzione è stata contrassegnata come fallita. -
_namefilter (opzionale) _: recupera solo le esecuzioni per l'identificatore di script specificato. Convalida dell'input: non può superare i 255 caratteri
-
-
-
Restituisce una raccolta di dettagli sulle esecuzioni dei lavori in formato JSON. Per ulteriori informazioni, consulta Dettagli sull'esecuzione del lavoro, struttura dei messaggi.
Risposta di esempio:
[ { "scriptId": "INTCALC", "caller": "127.0.0.1", "identifier": "d43cbf46-4255-4ce2-aac2-79137573a8b4", "startTime": "06-12-2023 16:26:15", "endTime": "06-12-2023 16:26:15", "status": "DONE", "executionResult": "{ \"exitCode\": -1, \"stepName\": \"STEP15\", \"program\": \"CBACT04C\", \"status\": \"Error\" }", "executionMode": "ASYNCHRONOUS" } ]
Recupero dei dettagli sull'esecuzione del lavoro
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/getjobexecutioninfo/{jobexecutionid:.+} -
Argomenti:
-
jobexecutionid (obbligatorio): l'identificatore univoco di esecuzione del lavoro per recuperare i dettagli di esecuzione del lavoro corrispondenti. Convalida dell'input: l'ID di esecuzione del lavoro non deve essere vuoto e non può superare i 255 caratteri
-
-
Restituisce una stringa JSON che rappresenta i dettagli di un singolo processo (vediDettagli sull'esecuzione del lavoro, struttura dei messaggi) o una risposta vuota se non è stato possibile trovare dettagli sull'esecuzione del lavoro per l'identificatore specificato.
Elenco degli script avviati in modo asincrono che possono essere eliminati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/killablescripts -
Restituisce una raccolta di identificatori di esecuzione dei lavori che sono stati avviati in modo asincrono che sono ancora attualmente in esecuzione e che possono essere interrotti forzatamente (vedi l'endpoint di seguito).
/kill
Elenco degli script avviati in modo sincrono che possono essere eliminati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/killablesyncscripts -
Restituisce una raccolta di identificatori di esecuzione dei lavori che sono stati avviati in modo sincrono, sono ancora attualmente in esecuzione e possono essere interrotti forzatamente (vedi l'
/killendpoint di seguito).
Uccidere una determinata esecuzione di lavoro
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/kill/{identifier:.+} -
Argomento: identificatore di esecuzione del lavoro (obbligatorio): l'identificatore univoco di esecuzione del lavoro che indica che l'esecuzione del lavoro deve essere annullata con la forza. Convalida dell'input: l'identificatore non deve essere vuoto e non può superare i 255 caratteri
-
Restituisce un messaggio di testo che descrive in dettaglio l'esito del tentativo di interruzione dell'esecuzione del lavoro; il messaggio conterrà l'identificatore dello script, l'identificatore univoco dell'esecuzione del lavoro e la data e l'ora in cui si è verificato il completamento dell'esecuzione. Se non è possibile trovare alcuna esecuzione del processo in esecuzione per l'identificatore specificato, verrà invece restituito un messaggio di errore.
avvertimento
-
Il runtime fa del suo meglio per interrompere correttamente l'esecuzione del job di destinazione. Pertanto, la risposta dall'endpoint /kill potrebbe impiegare un po' di tempo prima che arrivi al chiamante, poiché il runtime di AWS Transform for mainframe cercherà di ridurre al minimo l'impatto aziendale dell'interruzione del processo.
-
Interrompere forzatamente l'esecuzione di un lavoro non dovrebbe essere fatto alla leggera, in quanto potrebbe avere conseguenze aziendali dirette, tra cui la possibile perdita o il danneggiamento dei dati. Dovrebbe essere riservato ai casi in cui l'esecuzione di un determinato lavoro è andata storta e i mezzi per la correzione dei dati sono chiaramente identificati.
-
La soppressione di un posto di lavoro dovrebbe portare a ulteriori indagini (analisi post mortem) per capire cosa è andato storto e adottare misure correttive adeguate.
-
In ogni caso, il tentativo di terminare un processo in esecuzione verrà registrato nei log del server con messaggi a livello di avviso.
Elenco dei checkpoint esistenti per la riavviabilità
La riavvio del lavoro si basa sulla capacità degli script di registrare i checkpoint per tracciare l'avanzamento dell'esecuzione del CheckpointRegistry lavoro. Se l'esecuzione di un job non riesce a terminare correttamente e i checkpoint di riavvio sono stati registrati, è sufficiente riavviare l'esecuzione del job dall'ultimo checkpoint registrato conosciuto (senza dover eseguire i passaggi precedenti precedenti al checkpoint).
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/restarts/{scriptId}/{jobId} -
Argomenti:
-
scriptId (opzionale - stringa): lo script che viene riavviato.
-
joBid (opzionale - stringa): l'identificatore univoco dell'esecuzione di un lavoro.
-
-
Restituisce un elenco in formato JSON di punti di riavvio esistenti, che può essere utilizzato per riavviare un processo la cui esecuzione non è avvenuta e non è terminata correttamente o per attivare un riavvio ritardato ignorando i passaggi eseguiti in precedenza. Se nessuno script ha registrato alcun checkpoint, il contenuto della pagina sarà «Nessun checkpoint registrato».
Riavvio di un lavoro (in modo sincrono)
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/restart/{hashcode}/{scriptId}/{skipflag} -
Argomenti:
-
hashcode (intero - obbligatorio): riavvia l'esecuzione più recente di un job, utilizzando l'hashcode fornito come valore di checkpoint (vedi l'
/restartsendpoint sopra riportato per scoprire come recuperare un valore di checkpoint valido). -
scriptID (opzionale - stringa): lo script che viene riavviato.
-
skipflag (opzionale - boolean): salta l'esecuzione del passaggio selezionato (checkpoint) ed emette un riavvio dal passaggio successivo immediato (se presente).
-
-
Restituzioni: vedi la descrizione del reso sopra.
/script
Riavvio di un lavoro (in modo asincrono)
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/triggerrestart/{hashcode}/{scriptId}/{skipflag} -
Argomenti:
-
hashcode (intero - obbligatorio): riavvia l'esecuzione più recente di un job, utilizzando l'hashcode fornito come valore di checkpoint (vedi l'
/restartsendpoint sopra riportato per scoprire come recuperare un valore di checkpoint valido). -
scriptID (opzionale - stringa): lo script che viene riavviato.
-
skipflag (opzionale - boolean): salta l'esecuzione del passaggio selezionato (checkpoint) ed emette un riavvio dal passaggio successivo immediato (se presente).
-
-
Restituzioni: vedi la descrizione del reso sopra.
/triggerscript
Impostazione del limite di thread per le esecuzioni di lavori asincroni
L'esecuzione asincrona del processo si basa su un pool di thread dedicato nella JVM. Tale pool ha un limite fisso per quanto riguarda il numero di thread disponibili. L'utente ha la possibilità di regolare il limite in base alle capacità dell'host (numero CPUs, memoria disponibile, ecc...). Per impostazione predefinita, il limite di thread è impostato su 5 thread.
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/settriggerthreadlimit/{threadlimit:.+} -
Argomento (numero intero): il nuovo limite di thread da applicare. Convalida dell'input: deve essere compreso tra 1 e 1000 inclusi.
-
Restituisce un messaggio (
String) che indica il nuovo limite del thread e quello precedente, o un messaggio di errore se il valore limite del thread fornito non è valido (non è un numero intero strettamente positivo).
Risposta di esempio:
Set thread limit for Script Tower Control to 10 (previous value was 5)
Conteggio delle esecuzioni di lavori attivate attualmente in esecuzione
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/countrunningtriggeredscripts -
Restituisce un messaggio che indica il numero di processi in esecuzione avviati in modo asincrono e il limite di thread (ovvero il numero massimo di processi attivati che possono essere eseguiti contemporaneamente).
Risposta di esempio:
0 triggered script(s) running (limit =10)
Nota
Questo può essere usato per verificare, prima di avviare un lavoro, se il limite del thread non è stato raggiunto (il che impedirebbe l'avvio del processo).
Elimina le informazioni sull'esecuzione dei job
Le informazioni sulle esecuzioni dei processi rimangono nella memoria del server finché il server è attivo. Potrebbe essere conveniente eliminare le informazioni più vecchie dalla memoria, poiché non sono più rilevanti; questo è lo scopo di questo endpoint.
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/purgejobinformation/{age:.+} -
Argomenti: un valore intero strettamente positivo che rappresenta l'età in ore delle informazioni da eliminare. Convalida dell'input: deve essere compreso tra 0 e 365 inclusi.
-
Restituisce un messaggio con le seguenti informazioni:
-
Nome del file di eliminazione in cui le informazioni eliminate sull'esecuzione del lavoro vengono archiviate a scopo di archiviazione.
-
Numero di informazioni sull'esecuzione del lavoro eliminate.
-
Numero di informazioni rimanenti sull'esecuzione del lavoro nel memo
-
Endpoint delle metriche
Convalida dell'input: tutti gli endpoint delle metriche convalidano i parametri della richiesta e restituiscono HTTP 400 Bad Request per i valori non validi.
JVM
Questo endpoint restituisce le metriche disponibili relative alla JVM.
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/metrics/jvm -
Argomenti: nessuno
-
Restituisce un messaggio con le seguenti informazioni:
-
threadActiveCount: numero di thread attivi.
-
jvmMemoryUsed: memoria utilizzata attivamente dalla Java Virtual Machine.
-
jvmMemoryMax: Memoria massima consentita per la Java Virtual Machine.
-
jvmMemoryFree: Memoria disponibile non attualmente utilizzata dalla Java Virtual Machine.
-
Sessione
Questo endpoint restituisce le metriche relative alle sessioni HTTP attualmente aperte.
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/metrics/session -
Argomenti: nessuno
-
Restituisce un messaggio con le seguenti informazioni:
-
SessionCount: numero di sessioni utente attive attualmente gestite dal server.
-
Archiviazione
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/metrics/batch -
Argomenti:
-
startTimestamp (opzionale, numero): timestamp iniziale per il filtraggio dei dati. Convalida dell'input: deve essere un valore numerico valido.
-
EndTimestamp (opzionale, numero): timestamp di fine per il filtraggio dei dati. Convalida dell'input: deve essere un valore numerico valido.
-
pagina (opzionale, numero): numero di pagina per l'impaginazione. Convalida dell'input: deve essere un numero intero positivo.
-
PageSize (opzionale, numero): numero di elementi per pagina nell'impaginazione. Convalida dell'input: deve essere un numero intero strettamente positivo, massimo 500.
-
Convalida dell'input: la mappa dei parametri non può superare le 20 voci
-
-
Restituisce un messaggio con le seguenti informazioni:
-
contenuto: Elenco delle metriche di esecuzione in batch.
-
PageNumber: numero di pagina corrente nell'impaginazione.
-
PageSize: numero di elementi visualizzati per pagina.
-
TotalPages: numero totale di pagine disponibili.
-
numberOfElements: Numero di articoli nella pagina corrente.
-
last: contrassegno booleano per l'ultima pagina.
-
first: bandiera booleana per la prima pagina.
-
Transaction
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/metrics/transaction -
Argomenti:
-
startTimestamp (opzionale, numero): timestamp iniziale per il filtraggio dei dati. Convalida dell'input: deve essere un valore numerico valido.
-
EndTimestamp (opzionale, numero): timestamp di fine per il filtraggio dei dati. Convalida dell'input: deve essere un valore numerico valido.
-
pagina (opzionale, numero): numero di pagina per l'impaginazione. Convalida dell'input: deve essere un numero intero positivo.
-
PageSize (opzionale, numero): numero di elementi per pagina nell'impaginazione. Convalida dell'input: deve essere un numero intero strettamente positivo, massimo 500.
-
Convalida dell'input: la mappa dei parametri non può superare le 20 voci
-
-
Restituisce un messaggio con le seguenti informazioni:
-
contenuto: Elenco delle metriche di esecuzione delle transazioni.
-
PageNumber: numero di pagina corrente nell'impaginazione.
-
PageSize: numero di elementi visualizzati per pagina.
-
TotalPages: numero totale di pagine disponibili.
-
numberOfElements: Numero di articoli nella pagina corrente.
-
last: contrassegno booleano per l'ultima pagina.
-
first: bandiera booleana per la prima pagina.
-
Altri endpoint
Usa questi endpoint per elencare programmi o servizi registrati, scoprire lo stato di salute e gestire le transazioni JICS.
Argomenti
Elencare i programmi registrati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/programs -
Restituisce l'elenco dei programmi registrati, come pagina html. Ogni programma è designato dal suo identificatore principale. Nell'elenco vengono restituiti sia i programmi legacy modernizzati che i programmi di utilità (IDCAMS, IEBGENER, ecc...). Tieni presente che i programmi di utilità disponibili dipenderanno dalle applicazioni web di utilità che sono state distribuite sul tuo server tomcat. Ad esempio, i programmi di supporto alle z/OS utilità potrebbero non essere disponibili per gli asset iSeries modernizzati, in quanto non pertinenti.
Elenco dei servizi registrati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/services -
Restituisce l'elenco dei servizi di runtime registrati, come pagina html. I servizi forniti sono forniti dal runtime AWS Transform for mainframe come utilità, che possono essere utilizzate ad esempio negli script groovy. I servizi di caricamento Blusam (per creare set di dati Blusam da set di dati preesistenti) rientrano in questa categoria.
Risposta di esempio:
<p>BluesamESDSFileLoader</p><p>BluesamKSDSFileLoader</p><p>BluesamRRDSFileLoader</p>
Health status (Stato di integrità)
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/ -
Restituisce un messaggio semplice che indica che l'applicazione gapwalk è attiva e funzionante ()
Jics application is running.
Elenco delle transazioni JICS disponibili
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/transactions -
Restituisce una pagina html che elenca tutte le transazioni JICS disponibili. Ciò ha senso solo per gli ambienti con elementi JICS (modernizzazione degli elementi CICS precedenti).
Risposta di esempio:
<p>INQ1</p><p>MENU</p><p>MNT2</p><p>ORD1</p><p>PRNT</p>
Avvia una transazione JICS
-
Metodi supportati: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/jicstransrunner/{jtrans:.+} -
Argomenti:
-
Identificatore di transazione JICS (stringa, obbligatorio): identificatore della transazione JICS da avviare (lunghezza massima 8 caratteri)
-
<String, Object>richiesto: dati di input aggiuntivi da passare alla transazione, come mappa. Il contenuto di questa mappa verrà utilizzato per alimentare la COMMAREA
che verrà consumata dalla transazione JICS. La mappa può essere vuota se non sono richiesti dati per eseguire la transazione. -
opzionale: voci di intestazioni Http, per personalizzare l'ambiente di esecuzione per una determinata transazione. Sono supportate le seguenti chiavi di intestazione:
-
jics-channel: Il nome del JICS CHANNEL che verrà utilizzato dal programma che verrà lanciato al momento dell'avvio della transazione. -
jics-container: Il nome del JICS CONTAINER da utilizzare per l'avvio di questa transazione JICS. -
jics-startcode: lo STARTCODE (stringa, fino a 2 caratteri) da utilizzare all'inizio della transazione JICS. Vedi STARTCODEper i valori possibili (sfoglia la pagina). -
jicxa-xid: Lo XID (struttura X/Open transaction identifier XID) di una «transazione globale» (XA), avviata dal chiamante, acui parteciperà l'attuale avvio della transazione JICS. Convalida dell'input: XID non deve essere vuoto e non può superare i 255 caratteri.
-
-
-
Restituisce una serializzazione
com.netfective.bluage.gapwalk.rt.shared.web.TransactionResultBeanJSON, che rappresenta il risultato dell'avvio della transazione JICS. -
Convalida dell'input: i valori XID non validi (vuoti o superiori a 255 caratteri) restituiranno HTTP 400 Bad Request con i dettagli dell'errore di convalida.
Per ulteriori informazioni sui dettagli della struttura, vedere. Struttura dei risultati del lancio della transazione
Avviare una transazione JICS (alternativa)
-
metodi supportati: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
percorso:
/jicstransaction/{jtrans:.+} -
Argomenti:
- Identificatore di transazione JICS (stringa, obbligatorio)
-
identificatore della transazione JICS da avviare (lunghezza massima di 8 caratteri)
- richiesto: dati di input aggiuntivi da passare alla transazione, come mappa<String, Object>
-
Il contenuto di questa mappa verrà utilizzato per alimentare la COMMAREA
che verrà consumata dalla transazione JICS. La mappa può essere vuota se non sono richiesti dati per eseguire la transazione. - opzionale: voci di intestazioni Http, per personalizzare l'ambiente di esecuzione per una determinata transazione.
-
Sono supportate le seguenti chiavi di intestazione:
-
jics-channel: Il nome del JICS CHANNEL che verrà utilizzato dal programma che verrà lanciato al momento dell'avvio della transazione. -
jics-container: Il nome del JICS CONTAINER da utilizzare per l'avvio di questa transazione JICS. -
jics-startcode: lo STARTCODE (stringa, fino a 2 caratteri) da utilizzare all'inizio della transazione JICS. Per i valori possibili, vedi STARTCODE(sfoglia la pagina). -
jicxa-xid: Lo XID (struttura X/Open transaction identifier XID) di una «transazione globale» (XA), avviata dal chiamante, acui parteciperà l'avvio della transazione JICS corrente. Convalida dell'input: XID non deve essere vuoto e non può superare i 255 caratteri.
-
-
Restituisce una serializzazione
com.netfective.bluage.gapwalk.rt.shared.web.RecordHolderBeanJSON, che rappresenta il risultato dell'avvio della transazione JICS. I dettagli della struttura sono disponibili in. Struttura dei risultati del record di avvio delle transazioni -
Convalida dell'input: i valori XID non validi (vuoti o superiori a 255 caratteri) restituiranno HTTP 400 Bad Request con i dettagli dell'errore di convalida.
Elenca le sessioni attive
-
metodi supportati: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
percorso:
/activesessionlist -
Argomenti: nessuno
-
Convalida dell'input: la mappa dei parametri non può superare le 20 voci
-
Restituisce un elenco di serializzazioni
com.netfective.bluage.gapwalk.application.web.sessiontracker.SessionTrackerObjectin JSON, che rappresenta l'elenco delle sessioni utente attive. Quando il tracciamento delle sessioni è disabilitato, verrà restituito un elenco vuoto.
Endpoint relativi alle code di lavoro
Le code di lavoro sono il supporto di AWS Transform for mainframe per il meccanismo di invio dei AS400 lavori. Le code di lavoro vengono utilizzate AS400 per eseguire lavori su pool di thread specifici. Una coda di processi è definita da un nome e da un numero massimo di thread che corrisponde al numero massimo di programmi che possono essere eseguiti contemporaneamente su quella coda. Se in coda vengono inviati più lavori rispetto al numero massimo di thread, i lavori aspetteranno che un thread sia disponibile.
Per un elenco completo dello stato di un lavoro in coda, vedi. Possibile stato di un lavoro in coda
Le operazioni sulle code di lavoro vengono gestite tramite i seguenti endpoint dedicati. È possibile richiamare queste operazioni dall'URL dell'applicazione Gapwalk con il seguente URL principale:. http://server:port/gapwalk-application/jobqueue
Elenca le code disponibili
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
list-queues -
Restituisce l'elenco delle code disponibili insieme al loro stato, come elenco JSON di valori-chiave.
Risposta di esempio:
{"Default":"STAND_BY","queue1":"STARTED","queue2":"STARTED"}
Gli stati possibili per una coda di lavoro sono:
- STAND_BY
-
la coda dei lavori è in attesa di essere avviata.
- AVVIATA
-
la coda dei lavori è attiva e funzionante.
- UNKNOWN
-
lo stato della coda dei lavori non può essere determinato.
Avvia o riavvia una coda di lavori
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/restart/{name} -
Argomento: il nome della coda da avviare/riavviare, come stringa - obbligatorio. Convalida dell'input: il nome della coda non deve essere vuoto e non può superare i 255 caratteri.
-
L'endpoint non restituisce nulla ma si affida piuttosto allo stato http per indicare l'esito dell'operazione: start/restart
- HTTP 200
-
l' start/restart operazione è andata bene: la coda di lavoro specificata è ora AVVIATA.
- HTTP 404
-
la coda dei lavori non esiste.
- HTTP 503
-
si è verificata un'eccezione durante il start/restart tentativo (i log del server devono essere ispezionati per capire cosa è andato storto).
Invia un'offerta di lavoro per il lancio
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/submit -
Argomento: obbligatorio come corpo della richiesta, serializzazione JSON di un
com.netfective.bluage.gapwalk.rt.jobqueue.SubmitJobMessageoggetto. Per ulteriori informazioni, consulta Invia il lavoro e pianifica l'input del lavoro. -
Restituisce un JSON contenente l'originale
SubmitJobMessagee un registro che indica se il lavoro è stato inviato o meno.
Elenca tutti i lavori inviati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/list-jobs?status={status}&size={size}&page={page}&sort={sort} -
Argomenti:
-
pagina: numero di pagina da recuperare (impostazione predefinita = 1)
-
dimensione: dimensione della pagina (impostazione predefinita = 50, max = 300)
-
sort: L'ordine dei lavori. (predefinito = «ExecutionID»). «ExecutionID» è attualmente l'unico valore supportato
-
status: (opzionale) Se presente, filtrerà in base allo stato.
-
-
Restituisce un elenco di tutti i lavori pianificati, come stringa JSON. Per un esempio di risposta, vedereElenco delle risposte ai lavori pianificati.
Rilasciare tutti i lavori che sono «in attesa»
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/release-all -
Restituisce un messaggio che indica l'esito dell'operazione di tentativo di rilascio. Ecco due casi possibili:
-
HTTP 200 e un messaggio «Tutti i lavori sono stati rilasciati con successo!» se tutti i lavori sono stati rilasciati con successo.
-
HTTP 503 e un messaggio «Jobs not released». Si è verificato un errore sconosciuto. Vedi «log» per maggiori dettagli» se qualcosa è andato storto con il tentativo di rilascio.
-
Rilascia tutti i lavori che sono «in attesa» per un determinato nome di lavoro
Per un determinato nome di lavoro, è possibile inviare più offerte di lavoro, con numeri di lavoro diversi (l'unicità di un lavoro è garantita da una coppia <job name, job number>). L'endpoint tenterà di rilasciare tutte le offerte di lavoro con il nome del lavoro specificato, che sono «in attesa».
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/release/{name} -
Argomenti: il nome del lavoro da cercare, sotto forma di stringa. Obbligatorio.
-
Restituisce un messaggio che indica il risultato dell'operazione di tentativo di rilascio. Ecco due casi possibili:
-
HTTP 200 e un messaggio «Jobs in group <name>(<number of released jobs>) rilasciato con successo!» i lavori sono stati rilasciati con successo.
-
HTTP 503 e un messaggio «Jobs in group <name>not released. Si è verificato un errore sconosciuto. Vedi il registro per maggiori dettagli» se qualcosa è andato storto con il tentativo di rilascio.
-
Rilascia un determinato lavoro per un numero di lavoro
<job name, job number>L' endpoint tenterà di rilasciare l'unica candidatura di lavoro «in attesa» per la coppia specificata.
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/release/{name}/{number} -
Argomenti:
- nome
-
il nome del lavoro da cercare, come stringa. Obbligatorio.
- numero
-
il numero del lavoro da cercare, come numero intero. Obbligatorio.
- restituisce
-
un messaggio che indica l'esito dell'operazione di tentativo di rilascio. Ecco due casi possibili:
-
HTTP 200 e un messaggio «» Job <name/number> rilasciato con successo!» se il lavoro è stato rilasciato con successo.
-
<name/number>HTTP 503 e un messaggio «Job>Non rilasciato. Si è verificato un errore sconosciuto. Vedi il registro per maggiori dettagli» se qualcosa è andato storto con il tentativo di rilascio.
-
Invia un lavoro con un programma ripetuto
Pianifica un lavoro che verrà eseguito con una pianificazione ripetuta.
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN, ROLE_USER
-
Percorso:
/schedule -
Argomento: il corpo della richiesta deve contenere una serializzazione JSON di un
com.netfective.bluage.gapwalk.rt.jobqueue.SubmitJobMessageoggetto.
Elenca tutti i lavori ripetuti inviati
-
Metodo supportato: GET
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/schedule/list?status={status}&size={size}&page={page}&sort={sort} -
Argomenti:
-
pagina: numero di pagina da recuperare (impostazione predefinita = 1)
-
dimensione: dimensione della pagina (impostazione predefinita = 50, max = 300)
-
sort: L'ordine dei lavori. (predefinito = «id»). «id» è l'unico valore supportato per ora.
-
status: (opzionale) Se presente, filtrerà in base allo stato. I valori possibili sono quelli indicati nella sezione 1.
-
status: (opzionale) Se presente, filtrerà in base allo stato. I valori possibili sono quelli indicati nella sezione 1.
-
Restituisce un elenco di tutti i lavori pianificati, come stringa JSON.
-
Annulla la pianificazione di un lavoro ripetuto
Rimuove un lavoro creato in base a una pianificazione ripetuta. Lo stato di pianificazione dei processi è impostato su INATTIVO.
-
Metodo supportato: POST
Richiede l'autenticazione e uno dei seguenti ruoli: ROLE_ADMIN, ROLE_SUPER_ADMIN
-
Percorso:
/schedule/remove/{schedule_id} -
Argomento:
schedule_id, l'identificatore del lavoro pianificato da rimuovere.
