Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di tabelle Apache Iceberg
AWS Lake Formation supporta la creazione di tabelle Apache Iceberg che utilizzano il formato di dati Apache Parquet AWS Glue Data Catalog con dati che risiedono in Amazon S3. Una tabella nel catalogo dati è la definizione dei metadati che rappresenta i dati in un datastore. Per impostazione predefinita, Lake Formation crea tabelle Iceberg v2. Per la differenza tra le tabelle v1 e v2, consulta Modifiche al tipo di formato nella documentazione di Apache Iceberg.
Apache Iceberg è un formato a tabella aperta per set di dati analitici di dimensioni molto grandi. Iceberg consente di modificare facilmente lo schema, operazione nota anche come evoluzione dello schema, il che significa che gli utenti possono aggiungere, rinominare o rimuovere colonne da una tabella di dati senza pregiudicare i dati sottostanti. Iceberg fornisce anche supporto per il controllo delle versioni dei dati, che consente agli utenti di tenere traccia delle modifiche apportate ai dati nel tempo. Ciò abilita la funzionalità di query temporale, che consente agli utenti di accedere e interrogare le versioni storiche dei dati e analizzare le modifiche ai dati tra aggiornamenti ed eliminazioni.
Puoi utilizzare la console Lake Formation o l'CreateTableoperazione nell' AWS Glue API per creare una tabella Iceberg nel Data Catalog. Per ulteriori informazioni, vedere CreateTable action (Python: create_table).
Quando si crea una tabella Iceberg nel catalogo dati, occorre specificare il formato della tabella e il percorso del file dei metadati in Amazon S3 per poter eseguire letture e scritture.
Puoi usare Lake Formation per proteggere la tua tabella Iceberg utilizzando autorizzazioni di controllo degli accessi granulari quando registri la posizione dati di Amazon S3 con. AWS Lake Formation Per i dati di origine in Amazon S3 e i metadati non registrati con Lake Formation, l'accesso è determinato dalle politiche di autorizzazione IAM per Amazon S3 e dalle azioni. AWS Glue Per ulteriori informazioni, consulta Gestione delle autorizzazioni di Lake Formation.
Il catalogo dati non supporta la creazione di partizioni e l'aggiunta di proprietà delle tabelle Iceberg.
Prerequisiti
Per creare tabelle Iceberg nel catalogo dati e configurare le autorizzazioni di accesso ai dati di Lake Formation, occorre soddisfare i seguenti requisiti:
-
Autorizzazioni richieste per creare tabelle Iceberg senza i dati registrati con Lake Formation.
Oltre alle autorizzazioni richieste per creare una tabella nel catalogo dati, il creatore della tabella richiede le seguenti autorizzazioni:
s3:PutObject sulla risorsa arn:aws:s3:::{bucketName}
-
s3:GetObject sulla risorsa arn:aws:s3:::{bucketName}
-
s3:DeleteObject sulla risorsa arn:aws:s3:::{bucketName}
-
Autorizzazioni richieste per creare tabelle Iceberg con dati registrati con Lake Formation:
Per utilizzare Lake Formation per gestire e proteggere i dati nel data lake, registrare la posizione Amazon S3 che contiene i dati per le tabelle con Lake Formation. In questo modo Lake Formation può fornire credenziali a servizi di AWS analisi come Athena, Redshift Spectrum e Amazon EMR per accedere ai dati. Per ulteriori informazioni sulla registrazione di una sede Amazon S3, consulta. Aggiungere una posizione Amazon S3 al tuo data lake
Un principale che legge e scrive i dati sottostanti registrati con Lake Formation richiede le seguenti autorizzazioni:
-
lakeformation:GetDataAccess
-
DATA_LOCATION_ACCESS
Un principale che dispone di autorizzazioni di localizzazione dei dati in una sede dispone anche delle autorizzazioni di localizzazione su tutte le sedi secondarie.
Per ulteriori informazioni sulle autorizzazioni relative alla localizzazione dei dati, consulta. Controllo sottostante dell'accesso ai dati
Per abilitare la compattazione, il servizio deve assumere un ruolo IAM con le autorizzazioni per aggiornare le tabelle nel catalogo dati. Per i dettagli, consulta Prerequisiti per l'ottimizzazione delle tabelle.
Creazione di una tabella Iceberg
Puoi creare tabelle Iceberg v1 e v2 utilizzando la console Lake Formation o AWS Command Line Interface come documentato in questa pagina. Puoi anche creare tabelle Iceberg usando la console o. AWS Glue Crawler di AWS Glue Per ulteriori informazioni, consultare Catalogo dati e crawler nella Guida per gli sviluppatori di AWS Glue .
Per creare una tabella Iceberg
- Console
-
Accedi a Console di gestione AWS, e apri la console Lake Formation all'indirizzo https://console.aws.amazon.com/lakeformation/.
In catalogo dati, scegliere Tabelle e utilizzare il pulsante Crea tabella per specificare i seguenti attributi:
-
Nome tabella: inserisci un nome per la tabella. Se si utilizza Athena per accedere alle tabelle, utilizzare questi suggerimenti per la denominazione della Guida per l'utente di Amazon Athena.
-
Database: scegli un database esistente o creane uno nuovo.
-
Descrizione: la descrizione della tabella. È possibile scrivere una descrizione per aiutare a comprendere i contenuti della tabella.
-
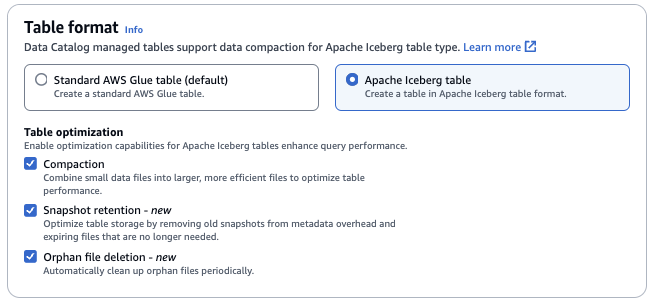
Formato tabella: per il formato tabella, scegli Apache Iceberg.
Ottimizzazione della tabella
-
Compattazione: I file di dati vengono uniti e riscritti per rimuovere i dati obsoleti e consolidare i dati frammentati in file più grandi ed efficienti.
Conservazione degli snapshot: gli snapshot sono versioni con data e ora di una tabella Iceberg. Le configurazioni di conservazione degli snapshot consentono ai clienti di stabilire per quanto tempo conservare gli snapshot e quanti snapshot conservare. La configurazione di un ottimizzatore di conservazione degli snapshot può aiutare a gestire il sovraccarico di archiviazione rimuovendo gli snapshot più vecchi e non necessari e i relativi file sottostanti.
Eliminazione di file orfani: i file orfani sono file a cui non fanno più riferimento i metadati della tabella Iceberg. Questi file possono accumularsi nel tempo, soprattutto dopo operazioni come l'eliminazione di tabelle o i processi ETL non riusciti. L'abilitazione dell'eliminazione dei file orfani AWS Glue consente di identificare e rimuovere periodicamente questi file non necessari, liberando spazio di archiviazione.
Per ulteriori informazioni, consulta Ottimizzazione delle tabelle Iceberg.
-
Ruolo IAM: per eseguire la compattazione, il servizio assume un ruolo IAM per conto dell'utente. Puoi scegliere un ruolo IAM utilizzando il menu a discesa. Assicurati che il ruolo disponga delle autorizzazioni necessarie per abilitare la compattazione.
Per ulteriori informazioni sulle autorizzazioni richieste, consulta Prerequisiti per l'ottimizzazione delle tabelle.
-
Posizione: specifica il percorso della cartella in Amazon S3 che memorizza la tabella dei metadati. Iceberg ha bisogno di un file di metadati e di una posizione nel catalogo dati per poter eseguire letture e scritture.
-
Schema: scegli Aggiungi colonne per aggiungere colonne e tipi di dati delle colonne. Si dispone della possibilità di creare una tabella vuota e di aggiornare lo schema in un secondo momento. Il catalogo dati supporta i tipi di dati Hive. Per ulteriori informazioni, consultare Tipi di dati Hive.
Iceberg consente di evolvere lo schema e la partizione dopo aver creato la tabella. È possibile usare le query di Athena per aggiornare lo schema della tabella e le query Spark per aggiornare le partizioni.
- AWS CLI
-
aws glue create-table \
--database-name iceberg-db \
--region us-west-2 \
--open-table-format-input '{
"IcebergInput": {
"MetadataOperation": "CREATE",
"Version": "2"
}
}' \
--table-input '{"Name":"test-iceberg-input-demo",
"TableType": "EXTERNAL_TABLE",
"StorageDescriptor":{
"Columns":[
{"Name":"col1", "Type":"int"},
{"Name":"col2", "Type":"int"},
{"Name":"col3", "Type":"string"}
],
"Location":"s3://DOC_EXAMPLE_BUCKET_ICEBERG/"
}
}'