Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Integrazione di Amazon S3 Tables con e AWS Glue Data Catalog AWS Lake Formation
Le tabelle Amazon S3 forniscono uno storage S3 specificamente ottimizzato per i carichi di lavoro di analisi, migliorando le prestazioni delle query e riducendo i costi. I dati in Tabelle S3 sono archiviati in un nuovo tipo di bucket: un bucket di tabelle, che archivia le tabelle come sottorisorse. Le tabelle S3 hanno il supporto integrato per lo standard Apache Iceberg, che consente di interrogare facilmente i dati tabulari nei bucket di tabelle Amazon S3 utilizzando i motori di query più diffusi come Apache Spark.
Puoi integrare Amazon S3 Tables AWS Glue Data Catalog utilizzando i controlli di accesso IAM o con sovvenzioni IAM e Lake Formation:
-
Controllo degli accessi IAM: utilizza le policy IAM per controllare l'accesso a S3 Tables e Data Catalog. In questo approccio di controllo degli accessi, sono necessarie le autorizzazioni IAM sia sulle risorse S3 Tables che sugli oggetti Data Catalog per accedere alle risorse.
-
Controllo degli accessi a Lake Formation: utilizza le AWS Lake Formation concessioni oltre alle autorizzazioni AWS Glue IAM per controllare l'accesso a S3 Tables tramite il Data Catalog. In questa modalità, i principali richiedono le autorizzazioni IAM per interagire con il Data Catalog e le sovvenzioni Lake Formation determinano a quali risorse del catalogo (database, tabelle, colonne, righe) il principale può accedere. Questa modalità supporta sia il controllo degli accessi a grana grossolana (concessioni a livello di database e tabella) sia il controllo degli accessi a grana fine (sicurezza a livello di colonna e di riga). Quando viene configurato un ruolo registrato e la vendita di credenziali è abilitata, le autorizzazioni IAM di S3 Tables non sono richieste per il principale, poiché Lake Formation fornisce le credenziali per conto del principale utilizzando il ruolo registrato. Il controllo degli accessi di Lake Formation supporta anche la vendita di credenziali per motori di analisi di terze parti.
Questa sezione fornisce indicazioni per configurare l'integrazione con AWS Lake Formation per i seguenti scenari:
-
Scenario A: hai integrato S3 Tables and Data Catalog utilizzando i controlli di accesso IAM e ora intendi AWS Lake Formation utilizzarli. Per ulteriori informazioni, consulta Modifica dei controlli di accesso per l'integrazione con S3 Tables.
-
Scenario B: prevedi di integrare S3 Tables e Data Catalog utilizzando AWS Lake Formation e attualmente non li hai integrati nel tuo account e nella tua regione. Inizia con la Prerequisiti per l'integrazione del catalogo di tabelle Amazon S3 con Data Catalog e Lake Formation sezione e proseguiAbilitazione dell'integrazione con Amazon S3 Tables.
-
Scenario C: hai integrato S3 Tables e Data Catalog utilizzando AWS Lake Formation e ora intendi utilizzare IAM. Per ulteriori informazioni, consulta Modifica dei controlli di accesso per l'integrazione con S3 Tables.
Assicurati di seguire i passaggi descritti in Integrazione delle tabelle S3 con i servizi di AWS analisi in modo da disporre delle autorizzazioni appropriate per accedere alle risorse e alle tabelle AWS Glue Data Catalog e per lavorare con i servizi di analisi. AWS
Argomenti
Come funziona l'integrazione tra Data Catalog e Lake Formation
Quando integri il catalogo di tabelle S3 con Data Catalog e Lake Formation, il AWS Glue servizio crea un unico catalogo federato chiamato s3tablescatalog nel Data Catalog predefinito del tuo account specifico per il tuo. Regione AWS L'integrazione mappa tutte le risorse del table bucket di Amazon S3 nel tuo account e Regione AWS nel catalogo federato nel modo seguente:
I bucket da tavolo Amazon S3 diventano un catalogo multilivello nel Data Catalog.
-
Lo spazio dei nomi Amazon S3 associato è registrato come database nel Data Catalog.
-
Le tabelle Amazon S3 nel bucket di tabelle diventano tabelle nel Data Catalog.
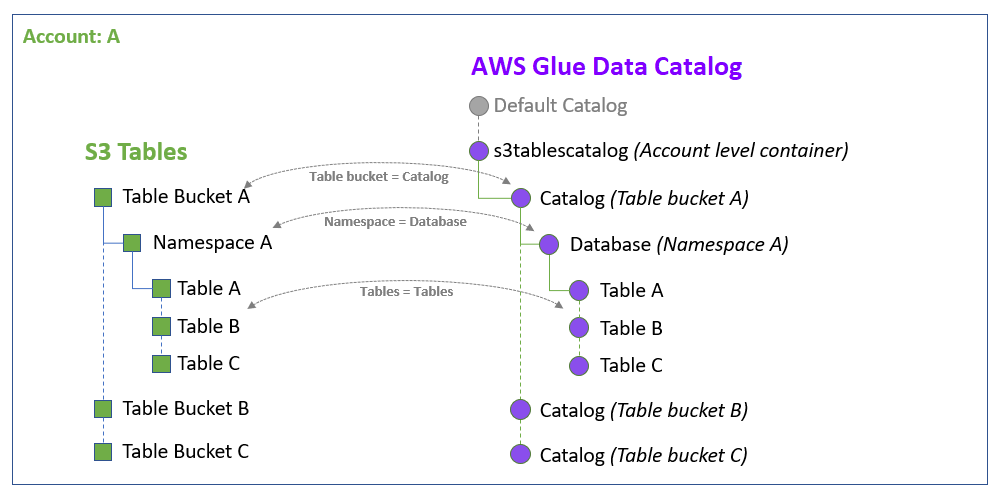
Dopo l'integrazione con Lake Formation, puoi creare tabelle Apache Iceberg nel catalogo di table buckets e accedervi tramite motori di AWS analisi integrati come Amazon Athena Amazon EMR e motori di analisi di terze parti.
Quando abiliti anche Lake Formation con integrazione, abilita un controllo granulare degli accessi tramite. AWS Lake Formation Questo approccio alla sicurezza significa che, oltre alle autorizzazioni AWS Identity and Access Management (IAM), devi concedere al tuo responsabile IAM con Lake Formation le autorizzazioni sulle tue tabelle prima di poterle utilizzare.
Esistono due tipi principali di autorizzazioni in AWS Lake Formation:
-
Le autorizzazioni di accesso ai metadati controllano la possibilità di creare, leggere, aggiornare ed eliminare database e tabelle di metadati nel Catalogo dati.
-
Le autorizzazioni di accesso ai dati sottostanti controllano la capacità di leggere e scrivere dati nelle posizioni Amazon S3 sottostanti a cui fanno riferimento le risorse del Catalogo dati.
Lake Formation utilizza una combinazione del proprio modello di autorizzazioni e del modello di autorizzazioni IAM per controllare l’accesso alle risorse del Catalogo dati e ai dati sottostanti:
-
Affinché una richiesta di accesso alle risorse del Catalogo dati o ai dati sottostanti abbia esito positivo, la richiesta deve superare i controlli di autorizzazione sia di IAM sia di Lake Formation.
-
Le autorizzazioni IAM controllano l'accesso a Lake Formation AWS Glue APIs e alle risorse, mentre le autorizzazioni di Lake Formation controllano l'accesso alle risorse del Data Catalog, alle sedi Amazon S3 e ai dati sottostanti.
Le autorizzazioni Lake Formation si applicano solo nella Regione in cui sono state concesse e un principale deve essere autorizzato da un amministratore del data lake o da un altro principale con le autorizzazioni necessarie al fine di ottenere le autorizzazioni Lake Formation.
