Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Convalida della coerenza dei dati durante una migrazione online
La fase successiva del processo di migrazione online è la convalida dei dati. Le doppie scritture aggiungono nuovi dati al tuo database Amazon Keyspaces e hai completato la migrazione dei dati storici utilizzando il caricamento in blocco o la scadenza dei dati con TTL.
Ora puoi utilizzare la fase di convalida per confermare che entrambi gli archivi dati contengano effettivamente gli stessi dati e restituiscano gli stessi risultati di lettura. Puoi scegliere una delle due opzioni seguenti per verificare che entrambi i database contengano dati identici.
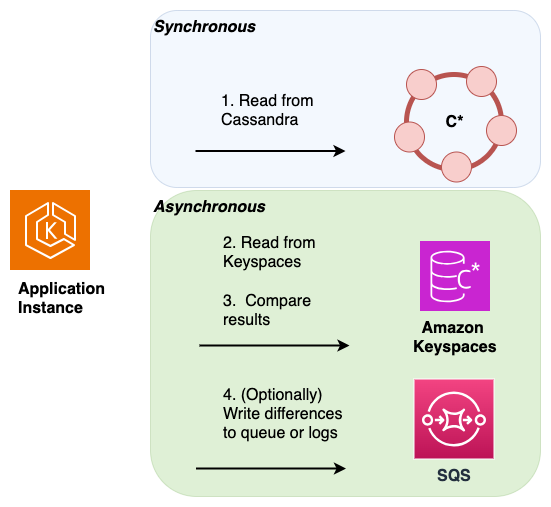
Doppie letture: per verificare che sia il database di origine che quello di destinazione contengano lo stesso set di dati appena scritti e storici, puoi implementare letture doppie. A tale scopo, leggi sia il database principale Cassandra che quello secondario di Amazon Keyspaces in modo analogo al metodo dual write e confronta i risultati in modo asincrono.
I risultati del database primario vengono restituiti al client e i risultati del database secondario vengono utilizzati per la convalida rispetto al set di risultati primario. Le differenze rilevate possono essere registrate o inviate a una coda di lettere morte (DLQ) per una successiva riconciliazione.
Nel diagramma seguente, l'applicazione esegue una lettura sincrona da Cassandra, che è l'archivio dati primario) e una lettura asincrona da Amazon Keyspaces, che è l'archivio dati secondario.
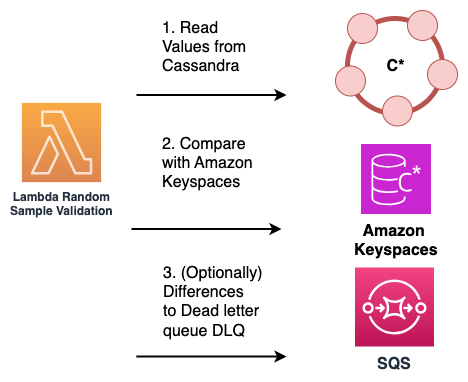
Letture di esempio: una soluzione alternativa che non richiede modifiche al codice dell'applicazione consiste nell'utilizzare AWS Lambda le funzioni per campionare periodicamente e in modo casuale i dati sia dal cluster Cassandra di origine che dal database Amazon Keyspaces di destinazione.
Queste funzioni Lambda possono essere configurate per essere eseguite a intervalli regolari. La funzione Lambda recupera un sottoinsieme casuale di dati sia dal sistema di origine che da quello di destinazione, quindi esegue un confronto tra i dati campionati. Eventuali discrepanze o discrepanze tra i due set di dati possono essere registrate e inviate a una coda di lettere morte (DLQ) dedicata per una successiva riconciliazione.
Questo processo è illustrato nello schema seguente.