Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Soluzione per il monitoraggio dell'infrastruttura Amazon EKS con Amazon Managed Grafana
Il monitoraggio dell'infrastruttura Amazon Elastic Kubernetes Service è uno degli scenari più comuni per i quali vengono utilizzati Amazon Managed Grafana. Questa pagina descrive un modello che fornisce una soluzione per questo scenario. La soluzione può essere installata utilizzando AWS Cloud Development Kit (AWS CDK)o con Terraform
Questa soluzione configura:
-
Il tuo spazio di lavoro Amazon Managed Service for Prometheus per archiviare i parametri dal tuo cluster Amazon EKS e creare un raccoglitore gestito per analizzare i parametri e trasferirli in quell'area di lavoro. Per ulteriori informazioni, consulta Ingest metrics with managed collectors. AWS
-
Raccolta di log dal cluster Amazon EKS tramite un CloudWatch agente. I log vengono archiviati e interrogati CloudWatch da Amazon Managed Grafana. Per ulteriori informazioni, consulta Logging for Amazon EKS
-
Il tuo spazio di lavoro Amazon Managed Grafana per recuperare i log e le metriche e creare dashboard e avvisi per aiutarti a monitorare il tuo cluster.
L'applicazione di questa soluzione creerà dashboard e avvisi che:
-
Valuta lo stato generale del cluster Amazon EKS.
-
Mostra lo stato e le prestazioni del piano di controllo di Amazon EKS.
-
Mostra lo stato e le prestazioni del piano dati Amazon EKS.
-
Visualizza informazioni dettagliate sui carichi di lavoro Amazon EKS nei namespace Kubernetes.
-
Visualizza l'utilizzo delle risorse in tutti i namespace, incluso l'utilizzo di CPU, memoria, disco e rete.
Informazioni su questa soluzione
Questa soluzione configura uno spazio di lavoro Amazon Managed Grafana per fornire parametri per il tuo cluster Amazon EKS. Le metriche vengono utilizzate per generare dashboard e avvisi.
Le metriche ti aiutano a gestire i cluster Amazon EKS in modo più efficace fornendo informazioni sullo stato e sulle prestazioni del piano dati e di controllo di Kubernetes. Puoi comprendere il tuo cluster Amazon EKS a livello di nodo, ai pod, fino al livello di Kubernetes, incluso il monitoraggio dettagliato dell'utilizzo delle risorse.
La soluzione offre funzionalità sia preventive che correttive:
-
Le funzionalità anticipatorie includono:
-
Gestisci l'efficienza delle risorse guidando le decisioni di pianificazione. Ad esempio, per fornire SLA in termini di prestazioni e affidabilità agli utenti interni del cluster Amazon EKS, puoi allocare risorse di CPU e memoria sufficienti ai loro carichi di lavoro in base al monitoraggio dell'utilizzo cronologico.
-
Previsioni di utilizzo: in base all'utilizzo attuale delle risorse del cluster Amazon EKS come nodi, volumi persistenti supportati da Amazon EBS o Application Load Balancers, puoi pianificare in anticipo, ad esempio, un nuovo prodotto o progetto con richieste simili.
-
Individua tempestivamente potenziali problemi: ad esempio, analizzando le tendenze del consumo di risorse a livello di namespace Kubernetes, puoi comprendere la stagionalità dell'utilizzo del carico di lavoro.
-
-
Le funzionalità correttive includono:
-
Riduci il tempo medio di rilevamento (MTTD) dei problemi sull'infrastruttura e sul livello di carico di lavoro Kubernetes. Ad esempio, esaminando la dashboard per la risoluzione dei problemi, puoi testare rapidamente le ipotesi su cosa è andato storto ed eliminarle.
-
Determina in quale parte dello stack si è verificato un problema. Ad esempio, il piano di controllo di Amazon EKS è completamente gestito da AWS e alcune operazioni, come l'aggiornamento di una distribuzione Kubernetes, potrebbero non riuscire se il server API è sovraccarico o la connettività ne risente.
-
L'immagine seguente mostra un esempio della cartella dashboard per la soluzione.
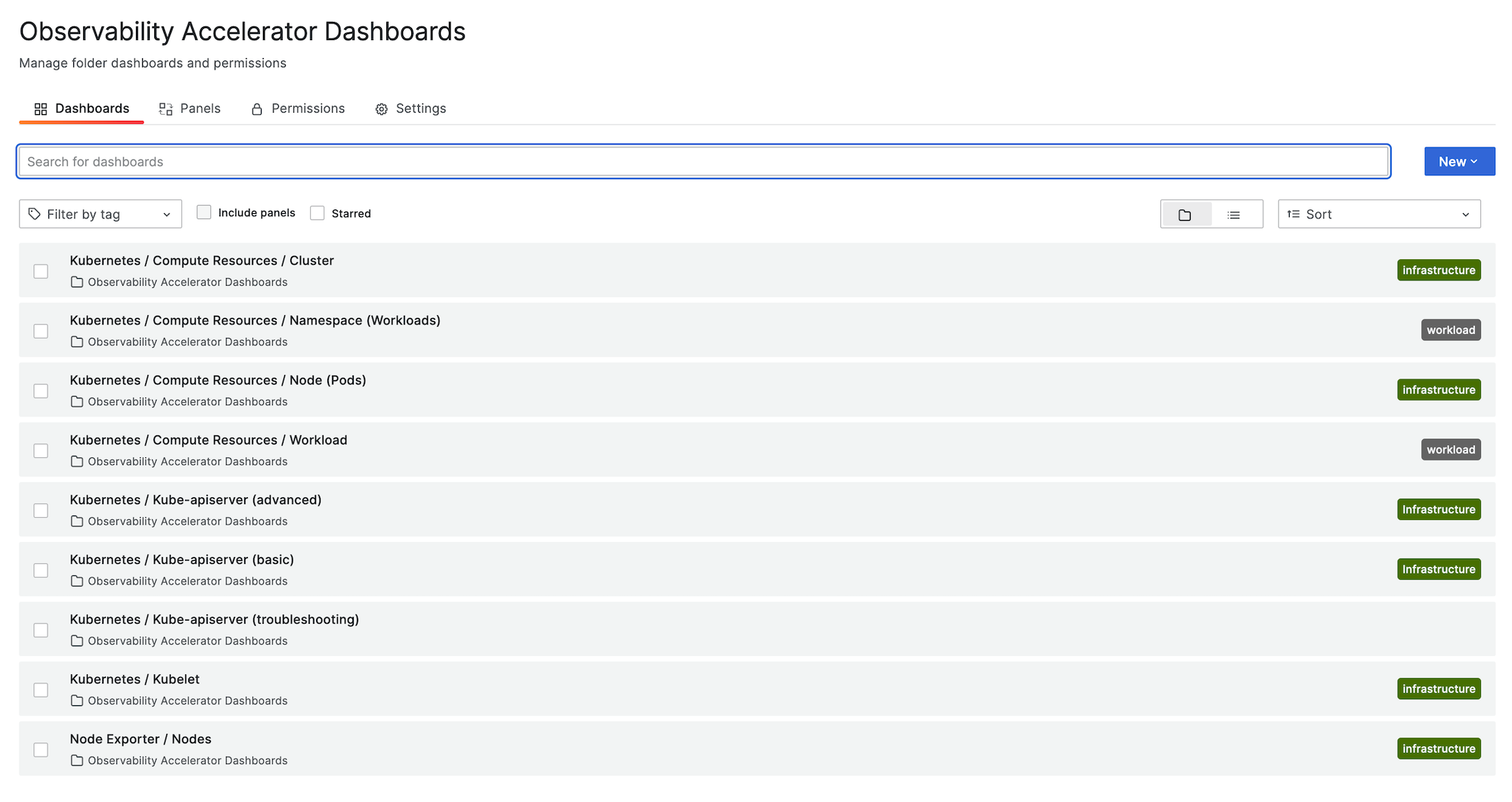
Puoi scegliere una dashboard per visualizzare maggiori dettagli, ad esempio, scegliendo di visualizzare le risorse di elaborazione per i carichi di lavoro, verrà visualizzata una dashboard, come quella mostrata nell'immagine seguente.
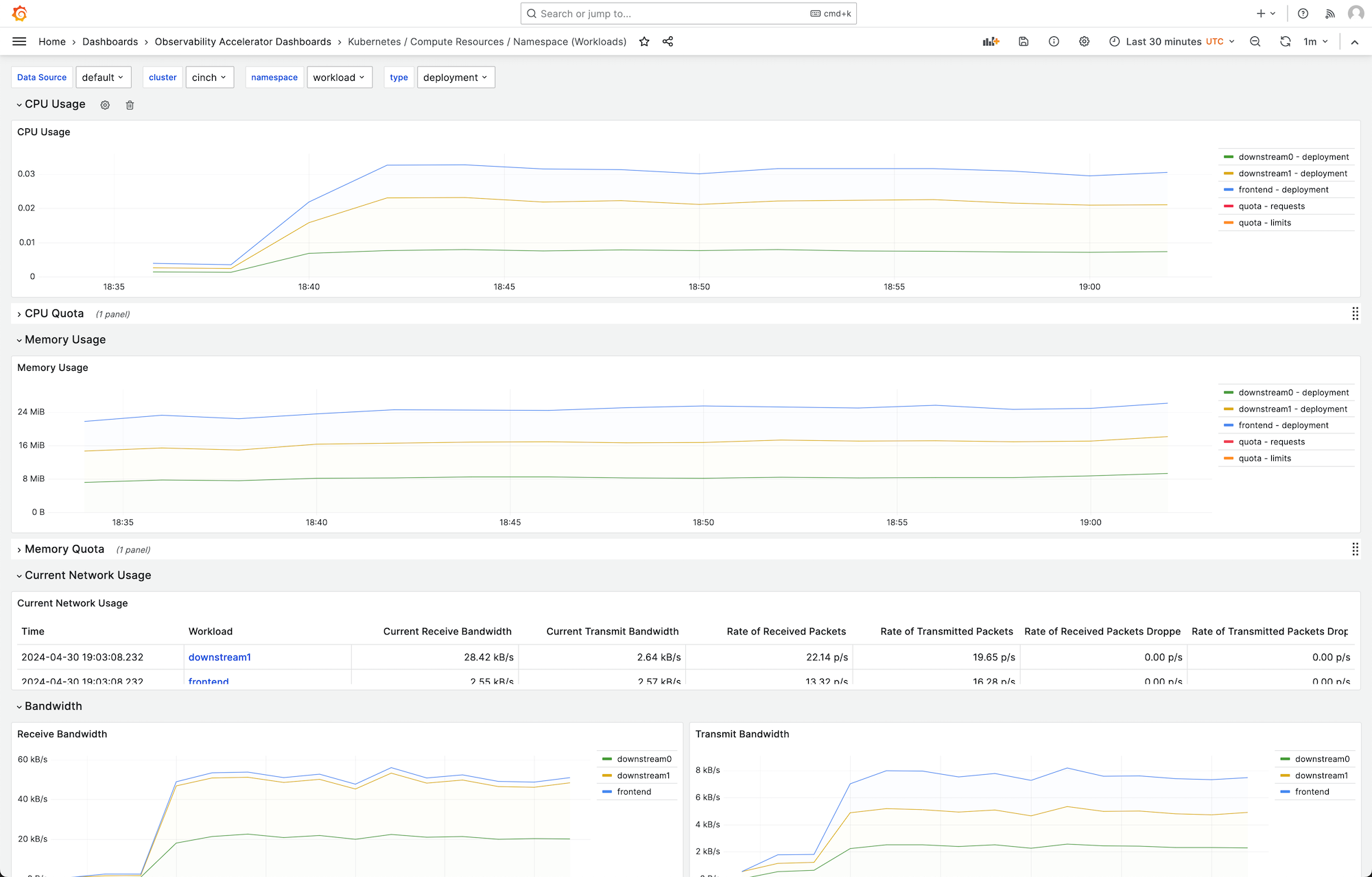
Le metriche vengono elaborate con un intervallo di scrape di 1 minuto. I dashboard mostrano le metriche aggregate a 1 minuto, 5 minuti o più, in base alla metrica specifica.
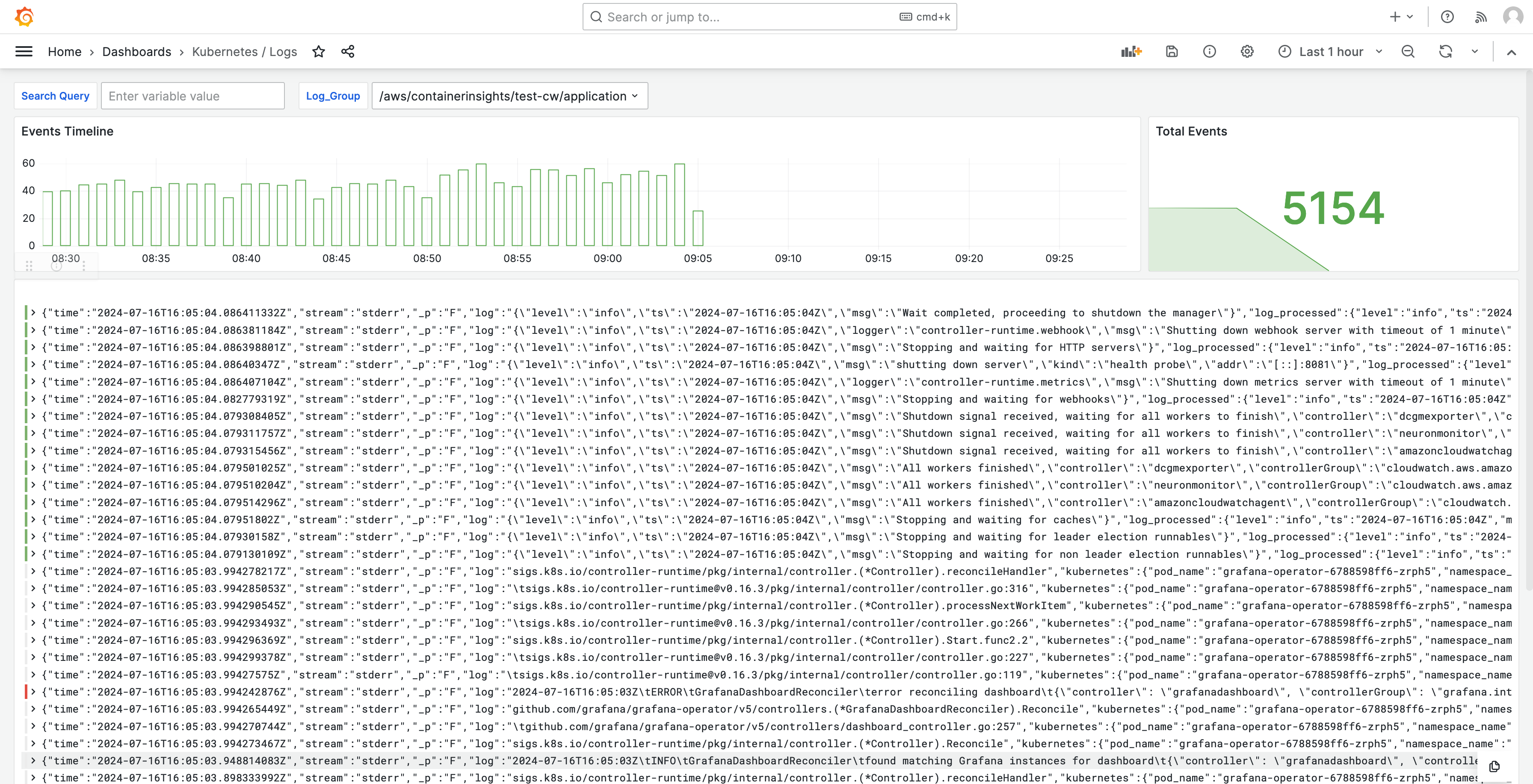
I log vengono visualizzati anche nelle dashboard, in modo da poter interrogare e analizzare i log per trovare le cause principali dei problemi. L'immagine seguente mostra un pannello di controllo dei log.
Per un elenco delle metriche tracciate da questa soluzione, consulta. Elenco delle metriche tracciate
Per un elenco degli avvisi creati dalla soluzione, consulta. Elenco degli avvisi creati
Costi
Questa soluzione crea e utilizza risorse nell'area di lavoro. Ti verrà addebitato l'utilizzo standard delle risorse create, tra cui:
-
Accesso agli spazi di lavoro Amazon Managed Grafana da parte degli utenti. Per ulteriori informazioni sui prezzi, consulta i prezzi di Amazon Managed Grafana
. -
Inserimento e archiviazione delle metriche di Amazon Managed Service for Prometheus, incluso l'uso del raccoglitore agentless di Amazon Managed Service for Prometheus e l'analisi metrica (elaborazione di esempi di query). Il numero di parametri utilizzati da questa soluzione dipende dalla configurazione e dall'utilizzo del cluster Amazon EKS.
Puoi visualizzare i parametri di ingestione e archiviazione in Amazon Managed Service for Prometheus utilizzando Per CloudWatch ulteriori informazioni, consulta i parametri CloudWatchnella Guida per l'utente di Amazon Managed Service for Prometheus.
Puoi stimare il costo utilizzando il calcolatore dei prezzi nella pagina dei prezzi di Amazon Managed Service for Prometheus
. Il numero di parametri dipenderà dal numero di nodi del cluster e dai parametri prodotti dalle applicazioni. -
CloudWatch Inserimento, archiviazione e analisi dei log. Per impostazione predefinita, la conservazione dei log è impostata per non scadere mai. È possibile modificarlo in CloudWatch. Per ulteriori informazioni sui prezzi, consulta la pagina CloudWatch dei prezzi di Amazon
. -
Costi di rete. È possibile che vengano addebitati costi AWS di rete standard per diverse zone di disponibilità, regioni o altro traffico.
I calcolatori dei prezzi, disponibili nella pagina dei prezzi di ciascun prodotto, possono aiutarti a comprendere i costi potenziali della tua soluzione. Le seguenti informazioni possono aiutare a calcolare un costo base per la soluzione in esecuzione nella stessa zona di disponibilità del cluster Amazon EKS.
| Prodotto | Metrica della calcolatrice | Valore |
|---|---|---|
Amazon Managed Service per Prometheus |
Serie Active |
8000 (base) 15.000 (per nodo) |
Intervallo di raccolta medio |
60 (secondi) |
|
Amazon Managed Service per Prometheus (gestore di raccolta) |
Numero di collezionisti |
1 |
Numero di campioni |
15 (base) 150 (per nodo) |
|
Numero di regole |
161 |
|
Intervallo medio di estrazione delle regole |
60 (secondi) |
|
Grafana gestito da Amazon |
Numero di attivi editors/administrators |
1 (o più, in base ai tuoi utenti) |
CloudWatch (Registri) |
Registri standard: dati acquisiti |
24,5 GB (base) 0,5 GB (per nodo) |
Registro Storage/Archival (registri standard e forniti) |
Sì all'archiviazione dei log: presupponendo 1 mese di conservazione |
|
Registri e dati previsti scansionati |
Ogni query di log insights di Grafana analizzerà tutti i contenuti dei log del gruppo nel periodo di tempo specificato. |
Questi numeri sono i numeri di base per una soluzione che esegue EKS senza software aggiuntivo. In questo modo si otterrà una stima dei costi base. Inoltre, esclude i costi di utilizzo della rete, che varieranno a seconda che l'area di lavoro Amazon Managed Grafana, l'area di lavoro Amazon Managed Service for Prometheus e il cluster Amazon EKS si trovino nella stessa zona di disponibilità e la VPN. Regione AWS
Nota
Quando un elemento di questa tabella include un (base) valore e un valore per risorsa (ad esempio,(per node)), dovresti aggiungere il valore di base al valore per risorsa moltiplicato per il numero di quella risorsa a tua disposizione. Ad esempio, per Serie temporali attive medie, inserisci un numero che sia8000 + the number of nodes in your cluster * 15,000. Se hai 2 nodi, devi inserire38,000, che è8000 + ( 2 * 15,000 ).
Prerequisiti
Questa soluzione richiede che siano state effettuate le seguenti operazioni prima di utilizzarla.
-
Devi avere o creare un cluster Amazon Elastic Kubernetes Service che desideri monitorare e il cluster deve avere almeno un nodo. Il cluster deve avere l'accesso agli endpoint del server API impostato in modo da includere l'accesso privato (può anche consentire l'accesso pubblico).
La modalità di autenticazione deve includere l'accesso all'API (può essere impostata su una delle due
APIopzioniAPI_AND_CONFIG_MAP). Ciò consente all'implementazione della soluzione di utilizzare le voci di accesso.Quanto segue deve essere installato nel cluster (vero per impostazione predefinita quando si crea il cluster tramite la console, ma deve essere aggiunto se si crea il cluster utilizzando l' AWS API o AWS CLI): AWS CNI, CoredNS e. Kube-proxy AddOns
Salva il nome del cluster da specificare in seguito. È possibile trovarlo nei dettagli del cluster nella console Amazon EKS.
Nota
Per informazioni dettagliate su come creare un cluster Amazon EKS, consulta Guida introduttiva ad Amazon EKS.
-
Devi creare uno spazio di lavoro Amazon Managed Service for Prometheus nello stesso Account AWS spazio del tuo cluster Amazon EKS. Per maggiori dettagli, consulta la Guida per l'utente di Amazon Managed Service for Prometheus.
Salva l'ARN dell'area di lavoro Amazon Managed Service for Prometheus per specificarlo in seguito.
-
Devi creare uno spazio di lavoro Amazon Managed Grafana con Grafana versione 9 o successiva, nello stesso del tuo cluster Amazon EKS Regione AWS . Per dettagli sulla creazione di un nuovo spazio di lavoro, consulta. Crea uno spazio di lavoro Amazon Managed Grafana
Il ruolo dell'area di lavoro deve disporre delle autorizzazioni per accedere ad Amazon Managed Service for Prometheus e alle API di Amazon. CloudWatch Il modo più semplice per farlo è utilizzare Service-managedle autorizzazioni e selezionare Amazon Managed Service for Prometheus e. CloudWatch Puoi anche aggiungere manualmente le AmazonGrafanaCloudWatchAccesspolitiche AmazonPrometheusQueryAccesse al tuo ruolo IAM nel tuo spazio di lavoro.
Salva l'ID e l'endpoint dell'area di lavoro Amazon Managed Grafana per specificarli in un secondo momento. L'ID è nel modulo.
g-123exampleL'ID e l'endpoint sono disponibili nella console Amazon Managed Grafana. L'endpoint è l'URL dell'area di lavoro e include l'ID. Ad esempio,https://g-123example.grafana-workspace.<region>.amazonaws.com/. -
Se stai distribuendo la soluzione con Terraform, devi creare un bucket Amazon S3 accessibile dal tuo account. Questo verrà utilizzato per archiviare i file di stato Terraform per la distribuzione.
Salva l'ID del bucket Amazon S3 per specificarlo in seguito.
-
Per visualizzare le regole di avviso di Amazon Managed Service for Prometheus, devi abilitare gli avvisi Grafana per l'area di lavoro Amazon Managed Grafana.
Inoltre, Amazon Managed Grafana deve disporre delle seguenti autorizzazioni per le tue risorse Prometheus. È necessario aggiungerle alle politiche gestite dal servizio o gestite dal cliente descritte in Autorizzazioni e policy di Amazon Managed Grafana per le fonti di dati AWS.
aps:ListRulesaps:ListAlertManagerSilencesaps:ListAlertManagerAlertsaps:GetAlertManagerStatusaps:ListAlertManagerAlertGroupsaps:PutAlertManagerSilencesaps:DeleteAlertManagerSilence
Nota
Sebbene non sia strettamente necessario per configurare la soluzione, devi configurare l'autenticazione degli utenti nel tuo spazio di lavoro Amazon Managed Grafana prima che gli utenti possano accedere ai dashboard creati. Per ulteriori informazioni, consulta Autentica gli utenti nelle aree di lavoro Amazon Managed Grafana.
Utilizzo di questa soluzione
Questa soluzione configura AWS l'infrastruttura per supportare i parametri di reporting e monitoraggio da un cluster Amazon EKS. Puoi installarlo utilizzando AWS Cloud Development Kit (AWS CDK)o con Terraform.
Elenco delle metriche tracciate
Questa soluzione crea uno scraper che raccoglie i parametri dal tuo cluster Amazon EKS. Queste metriche vengono archiviate in Amazon Managed Service for Prometheus e quindi visualizzate nelle dashboard di Amazon Managed Grafana. Per impostazione predefinita, lo scraper raccoglie tutte Prometheus-compatible le metriche esposte dal cluster. L'installazione nel cluster di software che produce più metriche aumenterà le metriche raccolte. Se lo desideri, puoi ridurre il numero di metriche aggiornando lo scraper con una configurazione che filtra le metriche.
I seguenti parametri vengono tracciati con questa soluzione, in una configurazione cluster Amazon EKS di base senza software aggiuntivo installato.
| Metrica | Descrizione/Scopo |
|---|---|
|
|
Indicatore dei servizi API contrassegnati come non disponibili suddivisi per nome APIService. |
|
|
Istogramma di latenza del webhook di ammissione in secondi, identificato per nome e suddiviso per ogni operazione e risorsa e tipo di API (convalida o ammissione). |
|
|
Numero massimo di richieste in volo attualmente utilizzate da questo apiserver per tipo di richiesta nell'ultimo secondo. |
|
|
Percentuale degli slot di cache attualmente occupati dai DEK memorizzati nella cache. |
|
|
Numero di richieste nella fase di esecuzione iniziale (per un WATCH) o qualsiasi (per una fase diversa da WATCH) nel sottosistema API Priority and Fairness. |
|
|
Numero di richieste rifiutate nella fase di esecuzione iniziale (per un WATCH) o in qualsiasi fase (per una fase diversa da WATCH) nel sottosistema API Priority and Fairness. |
|
|
Numero nominale di postazioni di esecuzione configurate per ogni livello di priorità. |
|
|
L'istogramma temporizzato della durata della fase iniziale (per un WATCH) o qualsiasi fase (per una fase diversa da WATCH) dell'esecuzione della richiesta nel sottosistema API Priority and Fairness. |
|
|
Il conteggio della fase iniziale (per un WATCH) o qualsiasi fase (per una fase diversa da WATCH) dell'esecuzione della richiesta nel sottosistema API Priority and Fairness. |
|
|
Indica una richiesta del server API. |
|
|
Indicatore delle API obsolete che sono state richieste, suddivise per gruppo di API, versione, risorsa, sottorisorsa e removed_release. |
|
|
Distribuzione della latenza di risposta in secondi per ogni verbo, valore di dry run, gruppo, versione, risorsa, sottorisorsa, ambito e componente. |
|
|
L'istogramma a intervalli di distribuzione della latenza di risposta in secondi per ogni verbo, valore di dry run, gruppo, versione, risorsa, sottorisorsa, ambito e componente. |
|
|
La distribuzione della latenza di risposta del Service Level Objective (SLO) in secondi per ogni verbo, valore di dry run, gruppo, versione, risorsa, sottorisorsa, ambito e componente. |
|
|
Numero di richieste terminate da apiserver per legittima difesa. |
|
|
Contatore di richieste apiserver suddiviso per ogni verbo, valore di dry run, gruppo, versione, risorsa, ambito, componente e codice di risposta HTTP. |
|
|
Tempo cumulativo di CPU consumato. |
|
|
Conteggio cumulativo dei byte letti. |
|
|
Conteggio cumulativo delle letture completate. |
|
|
Conteggio cumulativo dei byte scritti. |
|
|
Conteggio cumulativo delle scritture completate. |
|
|
Memoria cache totale delle pagine. |
|
|
Dimensione del file RSS. |
|
|
Utilizzo dello scambio di container. |
|
|
Set di lavoro attuale. |
|
|
Conteggio cumulativo dei byte ricevuti. |
|
|
Numero cumulativo di pacchetti persi durante la ricezione. |
|
|
Numero cumulativo di pacchetti ricevuti. |
|
|
Conteggio cumulativo dei byte trasmessi. |
|
|
Conteggio cumulativo dei pacchetti persi durante la trasmissione. |
|
|
Numero cumulativo di pacchetti trasmessi. |
|
|
L'istogramma a intervalli della latenza della richiesta etcd in secondi per ogni operazione e tipo di oggetto. |
|
|
Numero di goroutine attualmente esistenti. |
|
|
Numero di thread del sistema operativo creati. |
|
|
L'istogramma a intervalli della durata in secondi per le operazioni di cgroup manager. Suddiviso per metodo. |
|
|
Durata in secondi per le operazioni di cgroup manager. Suddiviso per metodo. |
|
|
Questa metrica è vera (1) se il nodo presenta un errore relativo alla configurazione, false (0) in caso contrario. |
|
|
Il nome del nodo. Il conteggio è sempre 1. |
|
|
L'istogramma ristretto della durata in secondi per riposizionare i pod in PLEG. |
|
|
Il conteggio della durata in secondi per il riposizionamento dei pod in PLEG. |
|
|
L'istogramma ristretto dell'intervallo in secondi tra una ripubblicazione in PLEG e l'altra. |
|
|
Il conteggio della durata in secondi tra il momento in cui Kubelet vede un pod per la prima volta e il pod che inizia a funzionare. |
|
|
L'istogramma suddiviso in intervalli della durata in secondi per sincronizzare un singolo pod. Suddiviso per tipo di operazione: creazione, aggiornamento o sincronizzazione. |
|
|
Il conteggio della durata in secondi per sincronizzare un singolo pod. Suddiviso per tipo di operazione: creazione, aggiornamento o sincronizzazione. |
|
|
Numero di contenitori attualmente in esecuzione. |
|
|
Numero di pod che dispongono di una sandbox Running Pod. |
|
|
L'istogramma suddiviso in intervalli della durata in secondi delle operazioni di runtime. Suddiviso per tipo di operazione. |
|
|
Numero cumulativo di errori di esecuzione per tipo di operazione. |
|
|
Numero cumulativo di operazioni di runtime per tipo di operazione. |
|
|
La quantità di risorse allocabili per i pod (dopo averne riservate alcune ai demoni di sistema). |
|
|
La quantità totale di risorse disponibili per un nodo. |
|
|
Il numero di risorse limite richieste da un contenitore. |
|
|
Il numero di risorse limite richieste da un contenitore. |
|
|
Il numero di risorse di richiesta richieste da un contenitore. |
|
|
Il numero di risorse di richiesta richieste da un contenitore. |
|
|
Informazioni sul proprietario del Pod. |
|
|
Le quote di risorse in Kubernetes impongono limiti di utilizzo su risorse come CPU, memoria e storage all'interno dei namespace. |
|
|
Le metriche di utilizzo della CPU per un nodo, incluso l'utilizzo per core e l'utilizzo totale. |
|
|
Secondi trascorsi dalle CPU in ciascuna modalità. |
|
|
La quantità cumulativa di tempo impiegato per eseguire I/O operazioni su disco per nodo. |
|
|
La quantità totale di tempo impiegata per eseguire I/O operazioni su disco per nodo. |
|
|
Il numero totale di byte letti dal disco dal nodo. |
|
|
Il numero totale di byte scritti su disco dal nodo. |
|
|
La quantità di spazio disponibile in byte sul filesystem di un nodo in un cluster Kubernetes. |
|
|
La dimensione totale del filesystem sul nodo. |
|
|
La media di carico di 1 minuto dell'utilizzo della CPU di un nodo. |
|
|
La media di caricamento di 15 minuti dell'utilizzo della CPU di un nodo. |
|
|
La media di carico in 5 minuti dell'utilizzo della CPU di un nodo. |
|
|
La quantità di memoria utilizzata per la memorizzazione nella cache del buffer dal sistema operativo del nodo. |
|
|
La quantità di memoria utilizzata per la memorizzazione nella cache del disco dal sistema operativo del nodo. |
|
|
La quantità di memoria disponibile per l'uso da parte di applicazioni e cache. |
|
|
La quantità di memoria libera disponibile sul nodo. |
|
|
La quantità totale di memoria fisica disponibile sul nodo. |
|
|
Il numero totale di byte ricevuti in rete dal nodo. |
|
|
Il numero totale di byte trasmessi in rete dal nodo. |
|
|
Tempo totale impiegato dalla CPU dell'utente e del sistema, in secondi. |
|
|
Dimensione della memoria residente in byte. |
|
|
Numero di richieste HTTP, partizionate per codice di stato, metodo e host. |
|
|
L'istogramma a intervalli della latenza delle richieste in secondi. Suddiviso per verbo e host. |
|
|
L'istogramma suddiviso in intervalli della durata delle operazioni di archiviazione. |
|
|
Il conteggio della durata delle operazioni di archiviazione. |
|
|
Numero cumulativo di errori durante le operazioni di storage. |
|
|
Una metrica che indica se la destinazione monitorata (ad esempio il nodo) è attiva e funzionante. |
|
|
Il numero totale di volumi gestiti dal gestore dei volumi. |
|
|
Numero totale di aggiunte gestite da workqueue. |
|
|
Profondità attuale della coda di lavoro. |
|
|
L'istogramma a intervalli che indica per quanto tempo, in secondi, un elemento rimane nella coda di lavoro prima di essere richiesto. |
|
|
L'istogramma suddiviso in intervalli di tempo in secondi per l'elaborazione di un elemento dalla coda di lavoro. |
Elenco degli avvisi creati
Nelle tabelle seguenti sono elencati gli avvisi creati da questa soluzione. Gli avvisi vengono creati come regole in Amazon Managed Service for Prometheus e vengono visualizzati nell'area di lavoro Amazon Managed Grafana.
Puoi modificare le regole, inclusa l'aggiunta o l'eliminazione di regole, modificando il file di configurazione delle regole nel tuo spazio di lavoro Amazon Managed Service for Prometheus.
Questi due avvisi sono avvisi speciali che vengono gestiti in modo leggermente diverso rispetto agli avvisi tipici. Invece di avvisarti di un problema, ti forniscono informazioni che vengono utilizzate per monitorare il sistema. La descrizione include dettagli su come utilizzare questi avvisi.
| Alert | Descrizione e utilizzo |
|---|---|
|
Si tratta di un avviso destinato a garantire il funzionamento dell'intera pipeline di avvisi. Questo avviso è sempre attivo, quindi dovrebbe essere sempre attivo in Alertmanager e sempre contro un ricevitore. Puoi integrarlo con il tuo meccanismo di notifica per inviare una notifica quando questo avviso non viene attivato. Ad esempio, è possibile utilizzare l'DeadMansSnitchintegrazione in PagerDuty. |
|
Si tratta di un avviso che viene utilizzato per inibire gli avvisi informativi. Di per sé, gli avvisi a livello di informazioni possono essere molto rumorosi, ma sono pertinenti se combinati con altri avvisi. Questo avviso viene attivato ogni volta che viene visualizzato un |
I seguenti avvisi forniscono informazioni o avvisi sul sistema.
| Alert | Gravità | Description |
|---|---|---|
|
|
warning |
L'interfaccia di rete cambia spesso il suo stato |
|
|
warning |
Si prevede che lo spazio disponibile nel file system si esaurirà entro le prossime 24 ore. |
|
|
critical |
Si prevede che lo spazio disponibile nel file system si esaurirà entro le prossime 4 ore. |
|
|
warning |
Lo spazio residuo nel file system è inferiore al 5%. |
|
|
critical |
Lo spazio residuo nel file system è inferiore al 3%. |
|
|
warning |
Si prevede che il file system esaurirà gli inode entro le prossime 24 ore. |
|
|
critical |
Si prevede che il file system esaurirà gli inode entro le prossime 4 ore. |
|
|
warning |
Nel file system sono rimasti meno del 5% degli inode. |
|
|
critical |
Al file system sono rimasti meno del 3% di inode. |
|
|
warning |
L'interfaccia di rete riporta molti errori di ricezione. |
|
|
warning |
L'interfaccia di rete riporta molti errori di trasmissione. |
|
|
warning |
Il numero di ingressi in conntrack si sta avvicinando al limite. |
|
|
warning |
Il raccoglitore di file di testo Node Exporter non è riuscito a raschiare. |
|
|
warning |
È stata rilevata un'inclinazione dell'orologio. |
|
|
warning |
L'orologio non si sincronizza. |
|
|
critical |
L'array RAID è danneggiato |
|
|
warning |
Dispositivo guasto nell'array RAID |
|
|
warning |
Si prevede che il kernel esaurirà presto il limite dei descrittori di file. |
|
|
critical |
Si prevede che il kernel esaurirà presto il limite dei descrittori di file. |
|
|
warning |
Il nodo non è pronto. |
|
|
warning |
Il nodo non è raggiungibile. |
|
|
info |
Kubelet sta funzionando a pieno regime. |
|
|
warning |
Lo stato di preparazione del nodo sta lampeggiando. |
|
|
warning |
Kubelet Pod Lifecycle Event Generator impiega troppo tempo per essere rimesso in vendita. |
|
|
warning |
La latenza di avvio di Kubelet Pod è troppo alta. |
|
|
warning |
Il certificato del client Kubelet sta per scadere. |
|
|
critical |
Il certificato client Kubelet sta per scadere. |
|
|
warning |
Il certificato del server Kubelet sta per scadere. |
|
|
critical |
Il certificato del server Kubelet sta per scadere. |
|
|
warning |
Kubelet non è riuscito a rinnovare il certificato client. |
|
|
warning |
Kubelet non è riuscito a rinnovare il certificato del server. |
|
|
critical |
L'obiettivo è scomparso dalla scoperta dell'obiettivo di Prometheus. |
|
|
warning |
Diverse versioni semantiche dei componenti Kubernetes in esecuzione. |
|
|
warning |
Il client del server dell'API Kubernetes presenta errori. |
|
|
warning |
Il certificato del client sta per scadere. |
|
|
critical |
Il certificato client sta per scadere. |
|
|
warning |
L'API aggregata Kubernetes ha segnalato errori. |
|
|
warning |
L'API aggregata Kubernetes non è attiva. |
|
|
critical |
L'obiettivo è scomparso dalla scoperta dell'obiettivo di Prometheus. |
|
|
warning |
L'apiserver Kubernetes ha terminato {{$value | humanizePercentage}} delle sue richieste in arrivo. |
|
|
critical |
Persistent Volume si sta riempiendo. |
|
|
warning |
Persistent Volume si sta riempiendo. |
|
|
critical |
Persistent Volume Inode si sta riempiendo. |
|
|
warning |
I Persistent Volume Inode si stanno riempiendo. |
|
|
critical |
Persistent Volume sta riscontrando problemi con il provisioning. |
|
|
warning |
Il cluster ha richiesto risorse CPU in eccesso. |
|
|
warning |
Il cluster ha richiesto risorse di memoria in eccesso. |
|
|
warning |
Il cluster ha sovraimpegnato le richieste di risorse della CPU. |
|
|
warning |
Il cluster ha richiesto risorse di memoria in eccesso. |
|
|
info |
La quota del namespace sarà piena. |
|
|
info |
La quota del namespace è completamente utilizzata. |
|
|
warning |
La quota del namespace ha superato i limiti. |
|
|
info |
I processi subiscono un rallentamento elevato della CPU. |
|
|
warning |
Il pod si blocca in modo anomalo. |
|
|
warning |
Pod è in uno stato non pronto da più di 15 minuti. |
|
|
warning |
Mancata corrispondenza nella generazione dell'implementazione a causa di un possibile rollback |
|
|
warning |
La distribuzione non corrisponde al numero previsto di repliche. |
|
|
warning |
StatefulSet non corrisponde al numero previsto di repliche. |
|
|
warning |
StatefulSet mancata corrispondenza generazionale dovuta a un possibile rollback |
|
|
warning |
StatefulSet l'aggiornamento non è stato implementato. |
|
|
warning |
DaemonSet il rollout è bloccato. |
|
|
warning |
Contenitore per cialde in attesa per più di 1 ora |
|
|
warning |
DaemonSet i pod non sono programmati. |
|
|
warning |
DaemonSet i pod sono programmati male. |
|
|
warning |
Job non è stato completato in tempo |
|
|
warning |
Job non completato. |
|
|
warning |
HPA non corrisponde al numero di repliche desiderato. |
|
|
warning |
HPA è in esecuzione al numero massimo di repliche |
|
|
critical |
kube-state-metrics sta riscontrando errori nelle operazioni sugli elenchi. |
|
|
critical |
kube-state-metrics presenta errori nelle operazioni di controllo. |
|
|
critical |
Lo sharding di kube-state-metrics non è configurato correttamente. |
|
|
critical |
Mancano gli shard kube-state-metrics. |
|
|
critical |
Il server API sta consumando un budget eccessivo per gli errori. |
|
|
critical |
Il server API sta consumando un budget eccessivo per gli errori. |
|
|
warning |
Il server API sta consumando un budget eccessivo per gli errori. |
|
|
warning |
Il server API sta consumando un budget eccessivo per gli errori. |
|
|
warning |
Uno o più obiettivi sono inattivi. |
|
|
critical |
Numero insufficiente di membri del cluster Etcd. |
|
|
warning |
Numero elevato di cambi di leader del cluster Etcd. |
|
|
critical |
Il cluster Etcd non ha un leader. |
|
|
warning |
Il cluster Etcd ha un numero elevato di richieste gRPC non riuscite. |
|
|
critical |
Le richieste gRPC del cluster Etcd sono lente. |
|
|
warning |
La comunicazione tra i membri del cluster Etcd è lenta. |
|
|
warning |
Numero elevato di proposte fallite del cluster Etcd. |
|
|
warning |
Durate di sincronizzazione elevate del cluster Etcd. |
|
|
warning |
Il cluster Etcd ha durate di commit superiori a quelle previste. |
|
|
warning |
Il cluster Etcd ha avuto esito negativo nelle richieste HTTP. |
|
|
critical |
Il cluster Etcd presenta un numero elevato di richieste HTTP non riuscite. |
|
|
warning |
Le richieste HTTP del cluster Etcd sono lente. |
|
|
warning |
L'orologio dell'host non si sincronizza. |
|
|
warning |
È stata rilevata un'interruzione dell'OOM host. |
Risoluzione dei problemi
Esistono alcuni fattori che possono causare il fallimento della configurazione del progetto. Assicurati di controllare quanto segue.
-
È necessario completare tutti i prerequisiti prima di installare la soluzione.
-
Il cluster deve contenere almeno un nodo prima di tentare di creare la soluzione o accedere alle metriche.
-
Nel cluster Amazon EKS devono essere installati
AWS CNICoreDNSkube-proxyi componenti aggiuntivi. Se non sono installati, la soluzione non funzionerà correttamente. Vengono installati per impostazione predefinita, quando si crea il cluster tramite la console. Potrebbe essere necessario installarli se il cluster è stato creato tramite un AWS SDK. -
L'installazione dei pod Amazon EKS è scaduta. Questo può accadere se la capacità disponibile dei nodi non è sufficiente. Le cause di questi problemi sono molteplici, tra cui:
-
Il cluster Amazon EKS è stato inizializzato con Fargate anziché Amazon EC2. Questo progetto richiede Amazon EC2.
-
I nodi sono contaminati e quindi non disponibili.
È possibile utilizzarlo
kubectl describe nodeper controllare le macchie. QuindiNODENAME| grep Taintskubectl taint nodeper rimuovere le macchie. Assicurati di includere il nomeNODENAMETAINT_NAME--dopo il nome della macchia. -
I nodi hanno raggiunto il limite di capacità. In questo caso puoi creare un nuovo nodo o aumentare la capacità.
-
-
Non vedi alcuna dashboard in Grafana: stai utilizzando l'ID dell'area di lavoro Grafana errato.
Esegui il seguente comando per ottenere informazioni su Grafana:
kubectl describe grafanas external-grafana -n grafana-operatorPuoi controllare i risultati per l'URL corretto dell'area di lavoro. Se non è quello che ti aspetti, esegui nuovamente la distribuzione con l'ID dell'area di lavoro corretto.
Spec: External: API Key: Key: GF_SECURITY_ADMIN_APIKEY Name: grafana-admin-credentials URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Status: Admin URL: https://g-123example.grafana-workspace.aws-region.amazonaws.com Dashboards: ... -
Non vedi alcuna dashboard in Grafana: stai utilizzando una chiave API scaduta.
Per cercare questo caso, è necessario contattare l'operatore grafana e verificare la presenza di errori nei log. Ottieni il nome dell'operatore Grafana con questo comando:
kubectl get pods -n grafana-operatorQuesto restituirà il nome dell'operatore, ad esempio:
NAME READY STATUS RESTARTS AGEgrafana-operator-1234abcd5678ef901/1 Running 0 1h2mUtilizzate il nome dell'operatore nel seguente comando:
kubectl logsgrafana-operator-1234abcd5678ef90-n grafana-operatorMessaggi di errore come i seguenti indicano una chiave API scaduta:
ERROR error reconciling datasource {"controller": "grafanadatasource", "controllerGroup": "grafana.integreatly.org", "controllerKind": "GrafanaDatasource", "GrafanaDatasource": {"name":"grafanadatasource-sample-amp","namespace":"grafana-operator"}, "namespace": "grafana-operator", "name": "grafanadatasource-sample-amp", "reconcileID": "72cfd60c-a255-44a1-bfbd-88b0cbc4f90c", "datasource": "grafanadatasource-sample-amp", "grafana": "external-grafana", "error": "status: 401, body: {\"message\":\"Expired API key\"}\n"} github.com/grafana-operator/grafana-operator/controllers.(*GrafanaDatasourceReconciler).ReconcileIn questo caso, crea una nuova chiave API e distribuisci nuovamente la soluzione. Se il problema persiste, puoi forzare la sincronizzazione utilizzando il seguente comando prima della ridistribuzione:
kubectl delete externalsecret/external-secrets-sm -n grafana-operator -
Installazioni CDK: parametro SSM mancante. Se vedi un errore come il seguente, esegui
cdk bootstrape riprova.Deployment failed: Error: aws-observability-solution-eks-infra-$EKS_CLUSTER_NAME: SSM parameter /cdk-bootstrap/xxxxxxx/version not found. Has the environment been bootstrapped? Please run 'cdk bootstrap' (see https://docs.aws.amazon.com/cdk/latest/ guide/bootstrapping.html) -
La distribuzione può fallire se il provider OIDC esiste già. Verrà visualizzato un errore simile al seguente (in questo caso, per le installazioni CDK):
| CREATE_FAILED | Custom::AWSCDKOpenIdConnectProvider | OIDCProvider/Resource/Default Received response status [FAILED] from custom resource. Message returned: EntityAlreadyExistsException: Provider with url https://oidc.eks.REGION.amazonaws.com/id/PROVIDER IDalready exists.In questo caso, vai al portale IAM ed elimina il provider OIDC e riprova.
-
Installazioni di Terraform: viene visualizzato un messaggio di errore che include e.
cluster-secretstore-sm failed to create kubernetes rest client for update of resourcefailed to create kubernetes rest client for update of resourceQuesto errore indica in genere che External Secrets Operator non è installato o abilitato nel cluster Kubernetes. Viene installato come parte della distribuzione della soluzione, ma a volte non è pronto quando la soluzione lo richiede.
Puoi verificare che sia installato con il seguente comando:
kubectl get deployments -n external-secretsSe è installato, può essere necessario del tempo prima che l'operatore sia completamente pronto per l'uso. È possibile verificare lo stato delle Custom Resource Definitions (CRD) necessarie eseguendo il comando seguente:
kubectl get crds|grep external-secretsQuesto comando dovrebbe elencare i CRD relativi all'operatore segreto esterno, incluso
clustersecretstores.external-secrets.ioand.externalsecrets.external-secrets.ioSe non sono elencati, attendi qualche minuto e ricontrolla.Una volta registrati i CRD, è possibile eseguire
terraform applynuovamente l'operazione per distribuire la soluzione.
